 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach to Geographical Candidate Selection through Toponym Matching
Paper and Code
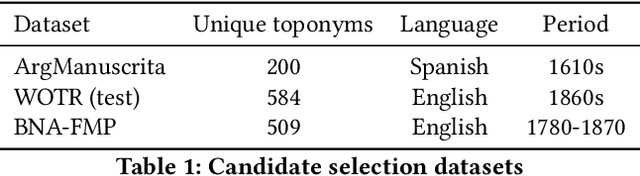
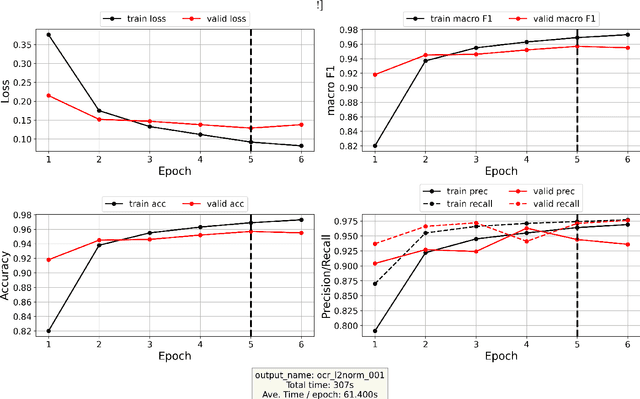
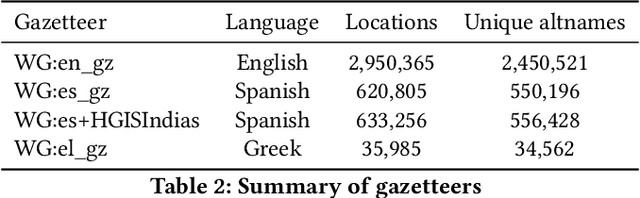
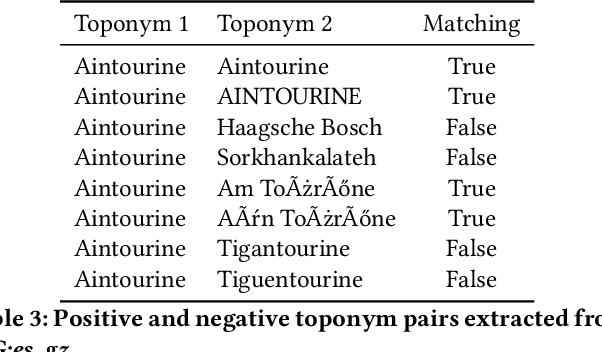
Recognizing toponyms and resolving them to their real-world referents is required for providing advanced semantic access to textual data. This process is often hindered by the high degree of variation in toponyms. Candidate selection is the task of identifying the potential entities that can be referred to by a toponym previously recognized. While it has traditionally received little attention in the research community, it has been shown that candidate selection has a significant impact on downstream tasks (i.e. entity resolution), especially in noisy or non-standard text. In this paper, we introduce a flexible deep learning method for candidate selection through toponym matching, using state-of-the-art neural network architectures. We perform an intrinsic toponym matching evaluation based on several new realistic datasets, which cover various challenging scenarios (cross-lingual and regional variations, as well as OCR errors). We report its performance on candidate selection in the context of the downstream task of toponym resolution, both on existing datasets and on a new manually-annotated resource of nineteenth-century English OCR'd text.