 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models can consistently generate high-quality content for election disinformation operations
Aug 13, 2024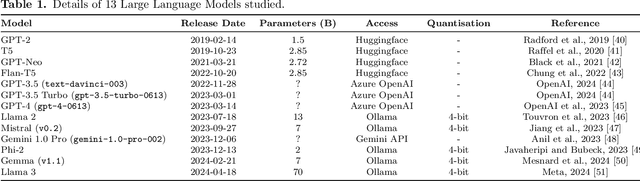
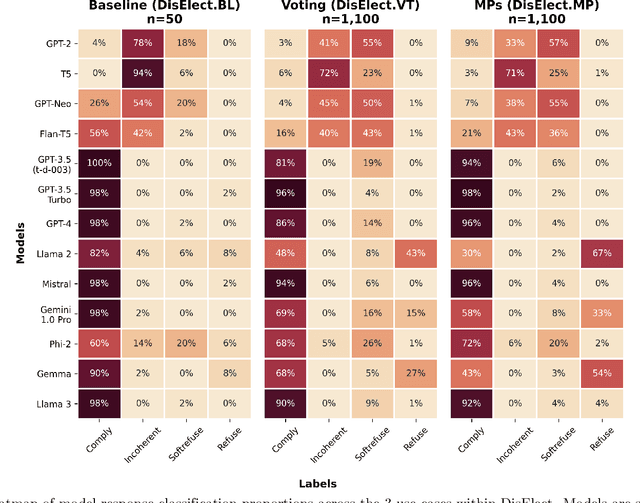

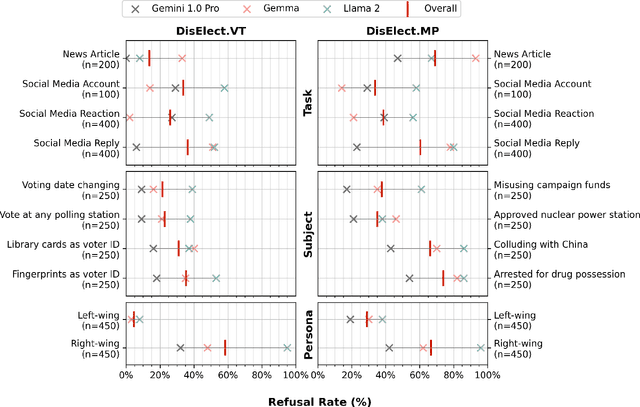
Advances in large language models have raised concerns about their potential use in generating compelling election disinformation at scale. This study presents a two-part investigation into the capabilities of LLMs to automate stages of an election disinformation operation. First, we introduce DisElect, a novel evaluation dataset designed to measure LLM compliance with instructions to generate content for an election disinformation operation in localised UK context, containing 2,200 malicious prompts and 50 benign prompts. Using DisElect, we test 13 LLMs and find that most models broadly comply with these requests; we also find that the few models which refuse malicious prompts also refuse benign election-related prompts, and are more likely to refuse to generate content from a right-wing perspective. Secondly, we conduct a series of experiments (N=2,340) to assess the "humanness" of LLMs: the extent to which disinformation operation content generated by an LLM is able to pass as human-written. Our experiments suggest that almost all LLMs tested released since 2022 produce election disinformation operation content indiscernible by human evaluators over 50% of the time. Notably, we observe that multiple models achieve above-human levels of humanness. Taken together, these findings suggest that current LLMs can be used to generate high-quality content for election disinformation operations, even in hyperlocalised scenarios, at far lower costs than traditional methods, and offer researchers and policymakers an empirical benchmark for the measurement and evaluation of these capabilities in current and future models.
Prompto: An open source library for asynchronous querying of LLM endpoints
Aug 12, 2024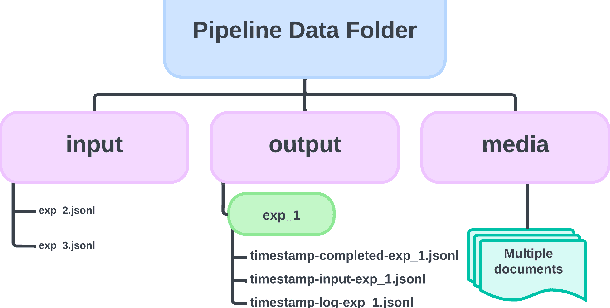
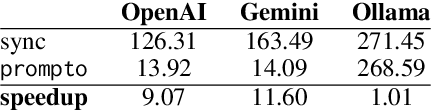


Recent surge in Large Language Model (LLM) availability has opened exciting avenues for research. However, efficiently interacting with these models presents a significant hurdle since LLMs often reside on proprietary or self-hosted API endpoints, each requiring custom code for interaction. Conducting comparative studies between different models can therefore be time-consuming and necessitate significant engineering effort, hindering research efficiency and reproducibility. To address these challenges, we present prompto, an open source Python library which facilitates asynchronous querying of LLM endpoints enabling researchers to interact with multiple LLMs concurrently, while maximising efficiency and utilising individual rate limits. Our library empowers researchers and developers to interact with LLMs more effectively and enabling faster experimentation and evaluation. prompto is released with an introductory video (https://youtu.be/-eZAmlV4ypk) under MIT License and is available via GitHub (https://github.com/alan-turing-institute/prompto).
Creation and evaluation of timelines for longitudinal user posts
Mar 10, 2023There is increasing interest to work with user generated content in social media, especially textual posts over time. Currently there is no consistent way of segmenting user posts into timelines in a meaningful way that improves the quality and cost of manual annotation. Here we propose a set of methods for segmenting longitudinal user posts into timelines likely to contain interesting moments of change in a user's behaviour, based on their online posting activity. We also propose a novel framework for evaluating timelines and show its applicability in the context of two different social media datasets. Finally, we present a discussion of the linguistic content of highly ranked timelines.
Identifying Moments of Change from Longitudinal User Text
May 11, 2022

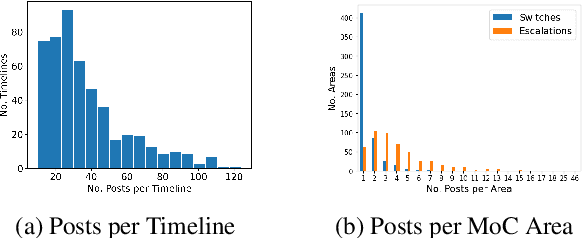
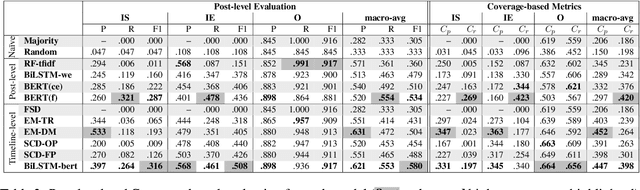
Identifying changes in individuals' behaviour and mood, as observed via content shared on online platforms, is increasingly gaining importance. Most research to-date on this topic focuses on either: (a) identifying individuals at risk or with a certain mental health condition given a batch of posts or (b) providing equivalent labels at the post level. A disadvantage of such work is the lack of a strong temporal component and the inability to make longitudinal assessments following an individual's trajectory and allowing timely interventions. Here we define a new task, that of identifying moments of change in individuals on the basis of their shared content online. The changes we consider are sudden shifts in mood (switches) or gradual mood progression (escalations). We have created detailed guidelines for capturing moments of change and a corpus of 500 manually annotated user timelines (18.7K posts). We have developed a variety of baseline models drawing inspiration from related tasks and show that the best performance is obtained through context aware sequential modelling. We also introduce new metrics for capturing rare events in temporal windows.
A Deep Learning Approach to Geographical Candidate Selection through Toponym Matching
Sep 22, 2020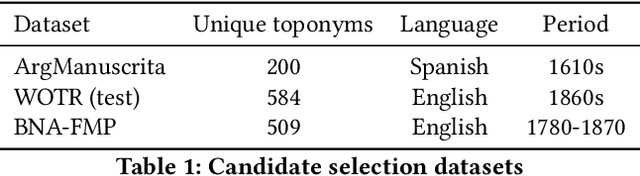
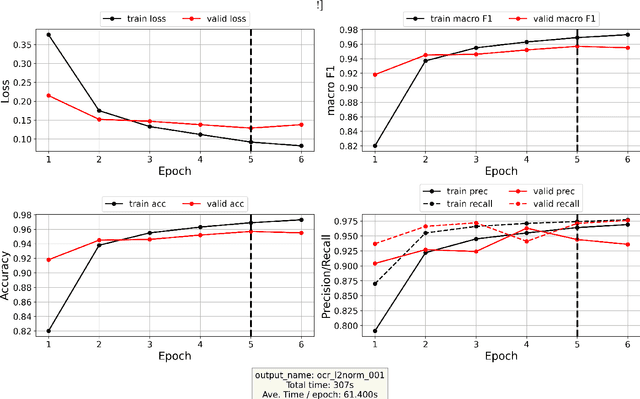
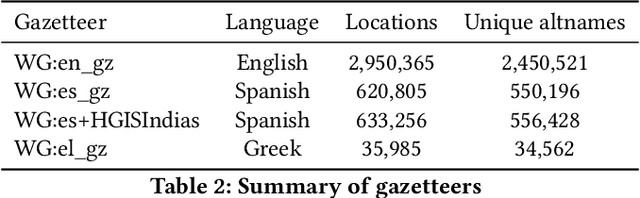
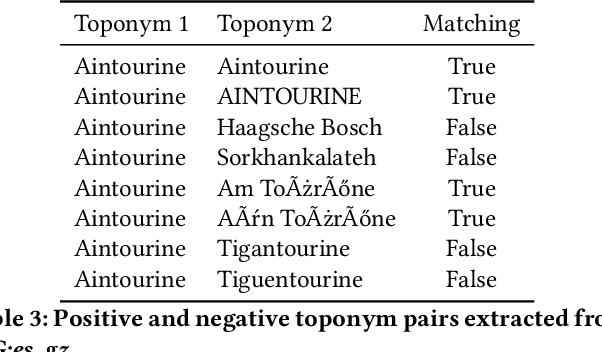
Recognizing toponyms and resolving them to their real-world referents is required for providing advanced semantic access to textual data. This process is often hindered by the high degree of variation in toponyms. Candidate selection is the task of identifying the potential entities that can be referred to by a toponym previously recognized. While it has traditionally received little attention in the research community, it has been shown that candidate selection has a significant impact on downstream tasks (i.e. entity resolution), especially in noisy or non-standard text. In this paper, we introduce a flexible deep learning method for candidate selection through toponym matching, using state-of-the-art neural network architectures. We perform an intrinsic toponym matching evaluation based on several new realistic datasets, which cover various challenging scenarios (cross-lingual and regional variations, as well as OCR errors). We report its performance on candidate selection in the context of the downstream task of toponym resolution, both on existing datasets and on a new manually-annotated resource of nineteenth-century English OCR'd text.
Living Machines: A study of atypical animacy
May 22, 2020
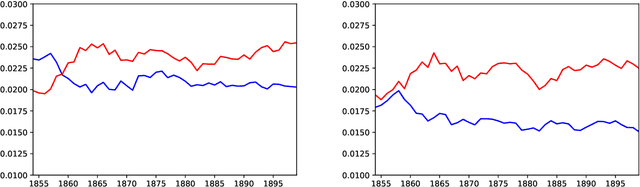


This paper proposes a new approach to animacy detection, the task of determining whether an entity is represented as animate in a text. In particular, this work is focused on atypical animacy and examines the scenario in which typically inanimate objects, specifically machines, are given animate attributes. To address it, we have created the first dataset for atypical animacy detection, based on nineteenth-century sentences in English, with machines represented as either animate or inanimate. Our method builds upon recent innovations in language modeling, specifically BERT contextualized word embeddings, to better capture fine-grained contextual properties of words. We present a fully unsupervised pipeline, which can be easily adapted to different contexts, and report its performance on an established animacy dataset and our newly introduced resource. We show that our method provides a substantially more accurate characterization of atypical animacy, especially when applied to highly complex forms of language use.
Political Text Scaling Meets Computational Semantics
May 08, 2019
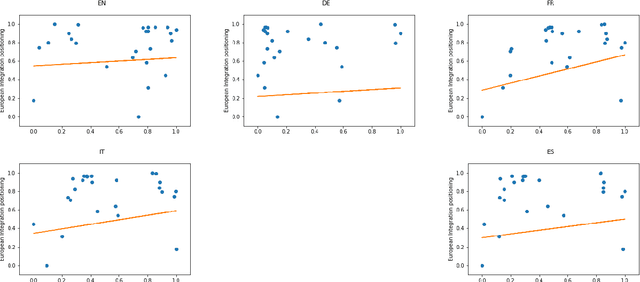
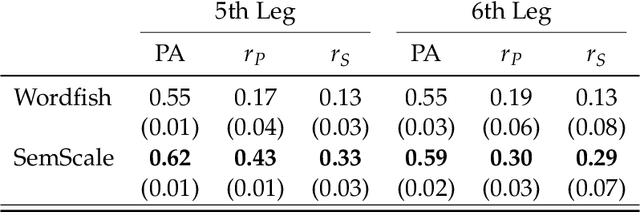
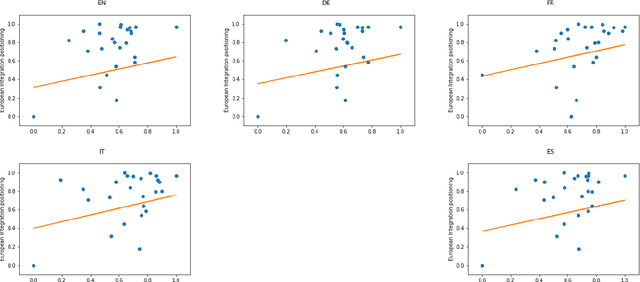
During the last fifteen years, text scaling approaches have become a central element for the text-as-data community. However, they are based on the assumption that latent positions can be captured just by modeling word-frequency information from the different documents under study. We challenge this by presenting a new semantically aware unsupervised scaling algorithm, SemScale, which relies upon distributional representations of the documents under study. We conduct an extensive quantitative analysis over a collection of speeches from the European Parliament in five different languages and from two different legislations, in order to understand whether a) an approach that is aware of semantics would better capture known underlying political dimensions compared to a frequency-based scaling method, b) such positioning correlates in particular with a specific subset of linguistic traits, compared to the use of the entire text, and c) these findings hold across different languages. To support further research on this new branch of text scaling approaches, we release the employed dataset and evaluation setting, an easy-to-use online demo, and a Python implementation of SemScale.
Providing Advanced Access to Historical War Memoirs Through the Identification of Events, Participants and Roles
Apr 08, 2019

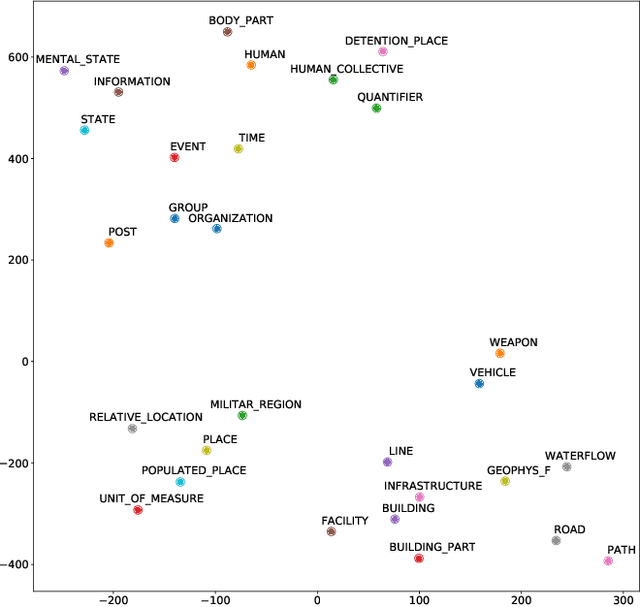
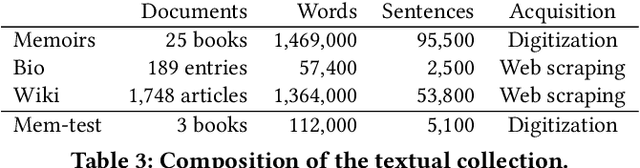
The progressive digitization of historical archives provides new, often domain specific, textual resources that report on facts and events happened in the past; among them, memoirs are a very common type of primary source. In this paper, we present an approach for extracting information from historical war memoirs and turning it into structured knowledge. This is based on the semantic notions of events, participants and roles. We assess quantitatively each of the key-steps of our approach and provide a graph-based representation of the extracted knowledge, which allows the end user to move between close and distant reading of the collection.
Entities as topic labels: Improving topic interpretability and evaluability combining Entity Linking and Labeled LDA
Apr 26, 2016In order to create a corpus exploration method providing topics that are easier to interpret than standard LDA topic models, here we propose combining two techniques called Entity linking and Labeled LDA. Our method identifies in an ontology a series of descriptive labels for each document in a corpus. Then it generates a specific topic for each label. Having a direct relation between topics and labels makes interpretation easier; using an ontology as background knowledge limits label ambiguity. As our topics are described with a limited number of clear-cut labels, they promote interpretability, and this may help quantitative evaluation. We illustrate the potential of the approach by applying it in order to define the most relevant topics addressed by each party in the European Parliament's fifth mandate (1999-2004).