 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetadata Might Make Language Models Better
Nov 18, 2022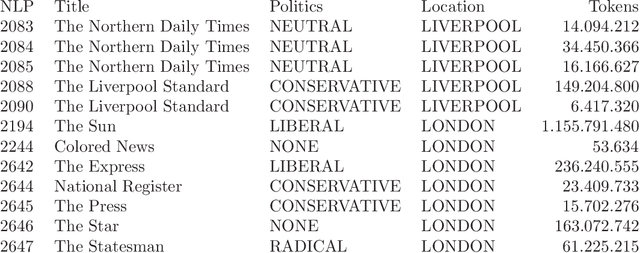

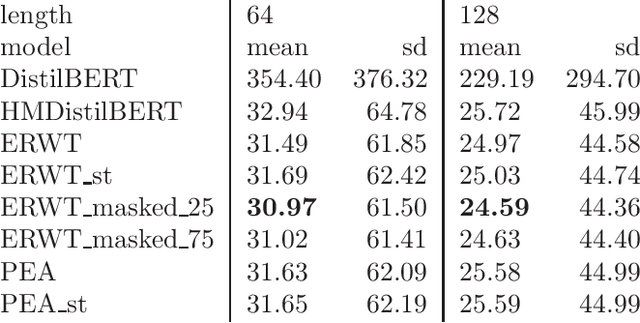

This paper discusses the benefits of including metadata when training language models on historical collections. Using 19th-century newspapers as a case study, we extend the time-masking approach proposed by Rosin et al., 2022 and compare different strategies for inserting temporal, political and geographical information into a Masked Language Model. After fine-tuning several DistilBERT on enhanced input data, we provide a systematic evaluation of these models on a set of evaluation tasks: pseudo-perplexity, metadata mask-filling and supervised classification. We find that showing relevant metadata to a language model has a beneficial impact and may even produce more robust and fairer models.
MapReader: A Computer Vision Pipeline for the Semantic Exploration of Maps at Scale
Nov 30, 2021



We present MapReader, a free, open-source software library written in Python for analyzing large map collections (scanned or born-digital). This library transforms the way historians can use maps by turning extensive, homogeneous map sets into searchable primary sources. MapReader allows users with little or no computer vision expertise to i) retrieve maps via web-servers; ii) preprocess and divide them into patches; iii) annotate patches; iv) train, fine-tune, and evaluate deep neural network models; and v) create structured data about map content. We demonstrate how MapReader enables historians to interpret a collection of $\approx$16K nineteenth-century Ordnance Survey map sheets ($\approx$30.5M patches), foregrounding the challenge of translating visual markers into machine-readable data. We present a case study focusing on British rail infrastructure and buildings as depicted on these maps. We also show how the outputs from the MapReader pipeline can be linked to other, external datasets, which we use to evaluate as well as enrich and interpret the results. We release $\approx$62K manually annotated patches used here for training and evaluating the models.
Neural Language Models for Nineteenth-Century English
May 24, 2021
We present four types of neural language models trained on a large historical dataset of books in English, published between 1760-1900 and comprised of ~5.1 billion tokens. The language model architectures include static (word2vec and fastText) and contextualized models (BERT and Flair). For each architecture, we trained a model instance using the whole dataset. Additionally, we trained separate instances on text published before 1850 for the two static models, and four instances considering different time slices for BERT. Our models have already been used in various downstream tasks where they consistently improved performance. In this paper, we describe how the models have been created and outline their reuse potential.
Living Machines: A study of atypical animacy
May 22, 2020
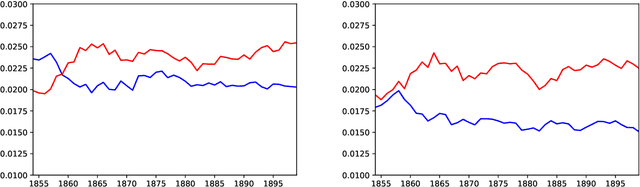


This paper proposes a new approach to animacy detection, the task of determining whether an entity is represented as animate in a text. In particular, this work is focused on atypical animacy and examines the scenario in which typically inanimate objects, specifically machines, are given animate attributes. To address it, we have created the first dataset for atypical animacy detection, based on nineteenth-century sentences in English, with machines represented as either animate or inanimate. Our method builds upon recent innovations in language modeling, specifically BERT contextualized word embeddings, to better capture fine-grained contextual properties of words. We present a fully unsupervised pipeline, which can be easily adapted to different contexts, and report its performance on an established animacy dataset and our newly introduced resource. We show that our method provides a substantially more accurate characterization of atypical animacy, especially when applied to highly complex forms of language use.
Words are Malleable: Computing Semantic Shifts in Political and Media Discourse
Nov 15, 2017

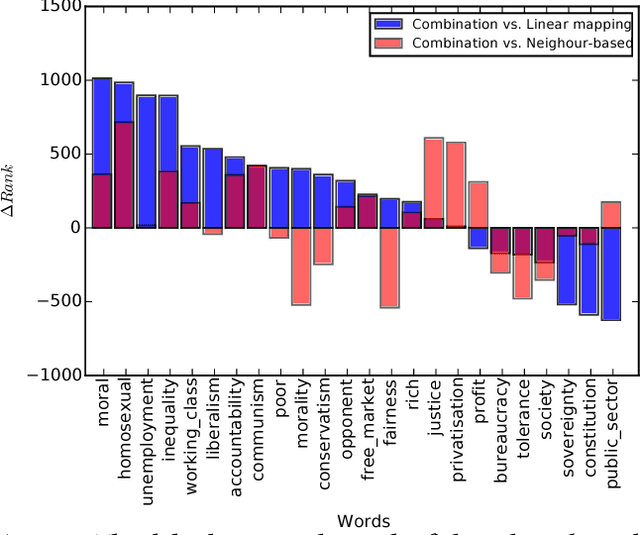
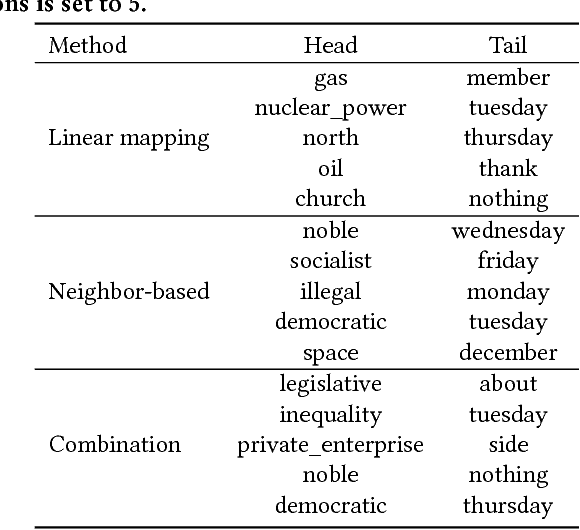
Recently, researchers started to pay attention to the detection of temporal shifts in the meaning of words. However, most (if not all) of these approaches restricted their efforts to uncovering change over time, thus neglecting other valuable dimensions such as social or political variability. We propose an approach for detecting semantic shifts between different viewpoints--broadly defined as a set of texts that share a specific metadata feature, which can be a time-period, but also a social entity such as a political party. For each viewpoint, we learn a semantic space in which each word is represented as a low dimensional neural embedded vector. The challenge is to compare the meaning of a word in one space to its meaning in another space and measure the size of the semantic shifts. We compare the effectiveness of a measure based on optimal transformations between the two spaces with a measure based on the similarity of the neighbors of the word in the respective spaces. Our experiments demonstrate that the combination of these two performs best. We show that the semantic shifts not only occur over time, but also along different viewpoints in a short period of time. For evaluation, we demonstrate how this approach captures meaningful semantic shifts and can help improve other tasks such as the contrastive viewpoint summarization and ideology detection (measured as classification accuracy) in political texts. We also show that the two laws of semantic change which were empirically shown to hold for temporal shifts also hold for shifts across viewpoints. These laws state that frequent words are less likely to shift meaning while words with many senses are more likely to do so.