 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Topic Pages for Scientific Concepts Using Scientific Publications
Apr 24, 2023In this paper, we describe Topic Pages, an inventory of scientific concepts and information around them extracted from a large collection of scientific books and journals. The main aim of Topic Pages is to provide all the necessary information to the readers to understand scientific concepts they come across while reading scholarly content in any scientific domain. Topic Pages are a collection of automatically generated information pages using NLP and ML, each corresponding to a scientific concept. Each page contains three pieces of information: a definition, related concepts, and the most relevant snippets, all extracted from scientific peer-reviewed publications. In this paper, we discuss the details of different components to extract each of these elements. The collection of pages in production contains over 360,000 Topic Pages across 20 different scientific domains with an average of 23 million unique visits per month, constituting it a popular source for scientific information.
HiTR: Hierarchical Topic Model Re-estimation for Measuring Topical Diversity of Documents
Oct 12, 2018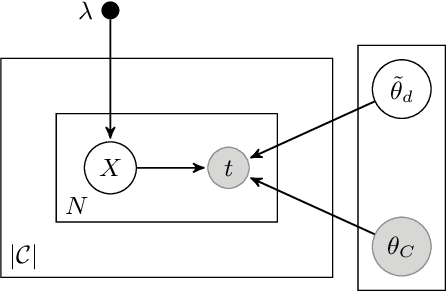

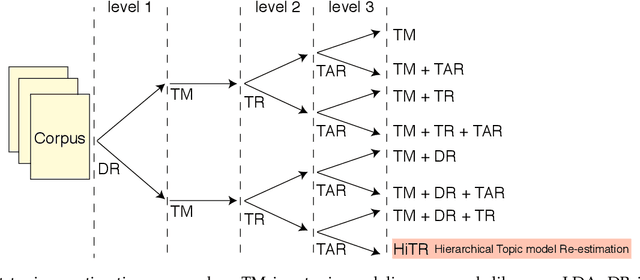
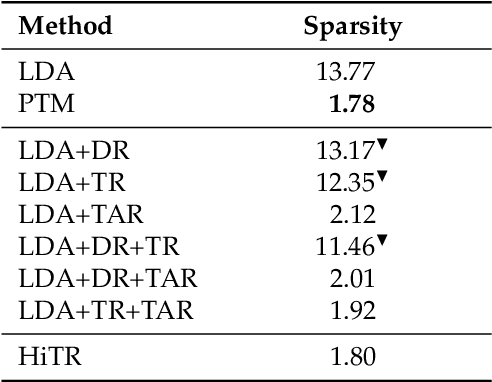
A high degree of topical diversity is often considered to be an important characteristic of interesting text documents. A recent proposal for measuring topical diversity identifies three distributions for assessing the diversity of documents: distributions of words within documents, words within topics, and topics within documents. Topic models play a central role in this approach and, hence, their quality is crucial to the efficacy of measuring topical diversity. The quality of topic models is affected by two causes: generality and impurity of topics. General topics only include common information of a background corpus and are assigned to most of the documents. Impure topics contain words that are not related to the topic. Impurity lowers the interpretability of topic models. Impure topics are likely to get assigned to documents erroneously. We propose a hierarchical re-estimation process aimed at removing generality and impurity. Our approach has three re-estimation components: (1) document re-estimation, which removes general words from the documents; (2) topic re-estimation, which re-estimates the distribution over words of each topic; and (3) topic assignment re-estimation, which re-estimates for each document its distributions over topics. For measuring topical diversity of text documents, our HiTR approach improves over the state-of-the-art measured on PubMed dataset.
Words are Malleable: Computing Semantic Shifts in Political and Media Discourse
Nov 15, 2017

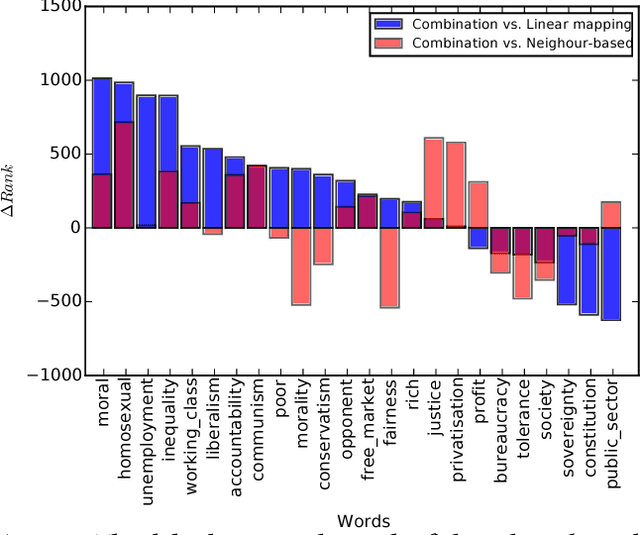
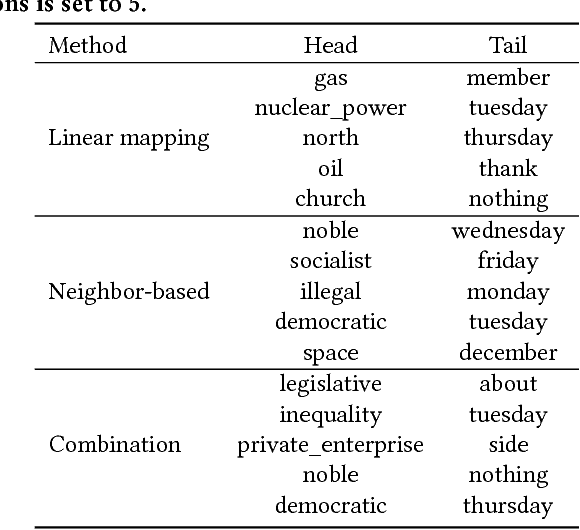
Recently, researchers started to pay attention to the detection of temporal shifts in the meaning of words. However, most (if not all) of these approaches restricted their efforts to uncovering change over time, thus neglecting other valuable dimensions such as social or political variability. We propose an approach for detecting semantic shifts between different viewpoints--broadly defined as a set of texts that share a specific metadata feature, which can be a time-period, but also a social entity such as a political party. For each viewpoint, we learn a semantic space in which each word is represented as a low dimensional neural embedded vector. The challenge is to compare the meaning of a word in one space to its meaning in another space and measure the size of the semantic shifts. We compare the effectiveness of a measure based on optimal transformations between the two spaces with a measure based on the similarity of the neighbors of the word in the respective spaces. Our experiments demonstrate that the combination of these two performs best. We show that the semantic shifts not only occur over time, but also along different viewpoints in a short period of time. For evaluation, we demonstrate how this approach captures meaningful semantic shifts and can help improve other tasks such as the contrastive viewpoint summarization and ideology detection (measured as classification accuracy) in political texts. We also show that the two laws of semantic change which were empirically shown to hold for temporal shifts also hold for shifts across viewpoints. These laws state that frequent words are less likely to shift meaning while words with many senses are more likely to do so.
Share your Model instead of your Data: Privacy Preserving Mimic Learning for Ranking
Jul 24, 2017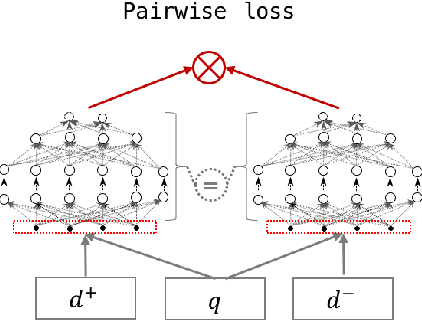

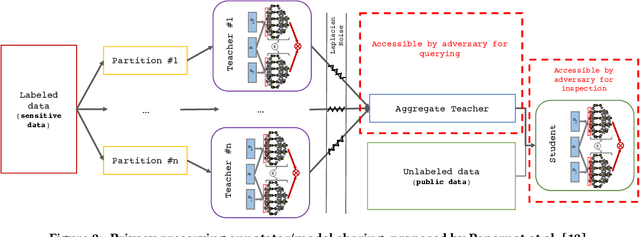
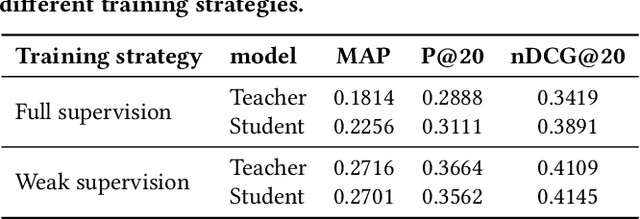
Deep neural networks have become a primary tool for solving problems in many fields. They are also used for addressing information retrieval problems and show strong performance in several tasks. Training these models requires large, representative datasets and for most IR tasks, such data contains sensitive information from users. Privacy and confidentiality concerns prevent many data owners from sharing the data, thus today the research community can only benefit from research on large-scale datasets in a limited manner. In this paper, we discuss privacy preserving mimic learning, i.e., using predictions from a privacy preserving trained model instead of labels from the original sensitive training data as a supervision signal. We present the results of preliminary experiments in which we apply the idea of mimic learning and privacy preserving mimic learning for the task of document re-ranking as one of the core IR tasks. This research is a step toward laying the ground for enabling researchers from data-rich environments to share knowledge learned from actual users' data, which should facilitate research collaborations.
On Horizontal and Vertical Separation in Hierarchical Text Classification
Sep 02, 2016
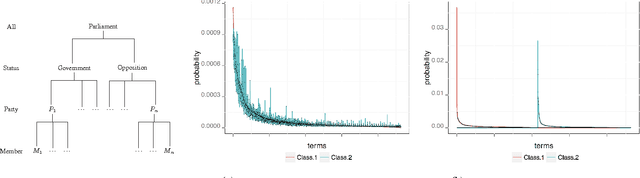


Hierarchy is a common and effective way of organizing data and representing their relationships at different levels of abstraction. However, hierarchical data dependencies cause difficulties in the estimation of "separable" models that can distinguish between the entities in the hierarchy. Extracting separable models of hierarchical entities requires us to take their relative position into account and to consider the different types of dependencies in the hierarchy. In this paper, we present an investigation of the effect of separability in text-based entity classification and argue that in hierarchical classification, a separation property should be established between entities not only in the same layer, but also in different layers. Our main findings are the followings. First, we analyse the importance of separability on the data representation in the task of classification and based on that, we introduce a "Strong Separation Principle" for optimizing expected effectiveness of classifiers decision based on separation property. Second, we present Hierarchical Significant Words Language Models (HSWLM) which capture all, and only, the essential features of hierarchical entities according to their relative position in the hierarchy resulting in horizontally and vertically separable models. Third, we validate our claims on real-world data and demonstrate that how HSWLM improves the accuracy of classification and how it provides transferable models over time. Although discussions in this paper focus on the classification problem, the models are applicable to any information access tasks on data that has, or can be mapped to, a hierarchical structure.
A Genetic Algorithm for solving Quadratic Assignment Problem(QAP)
May 20, 2014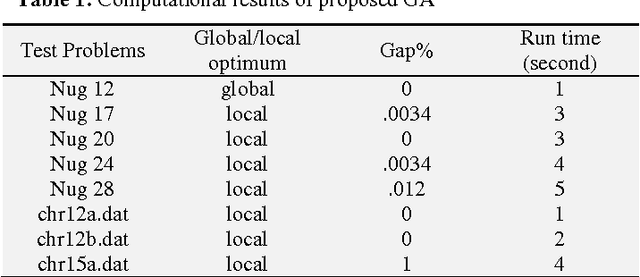
The Quadratic Assignment Problem (QAP) is one of the models used for the multi-row layout problem with facilities of equal area. There are a set of n facilities and a set of n locations. For each pair of locations, a distance is specified and for each pair of facilities a weight or flow is specified (e.g., the amount of supplies transported between the two facilities). The problem is to assign all facilities to different locations with the aim of minimizing the sum of the distances multiplied by the corresponding flows. The QAP is among the most difficult NP-hard combinatorial optimization problems. Because of this, this paper presents an efficient Genetic algorithm (GA) to solve this problem in reasonable time. For validation the proposed GA some examples are selected from QAP library. The obtained results in reasonable time show the efficiency of proposed GA.
* arXiv admin note: text overlap with arXiv:1305.2684 by other authors
Learning to Exploit Different Translation Resources for Cross Language Information Retrieval
May 20, 2014One of the important factors that affects the performance of Cross Language Information Retrieval(CLIR)is the quality of translations being employed in CLIR. In order to improve the quality of translations, it is important to exploit available resources efficiently. Employing different translation resources with different characteristics has many challenges. In this paper, we propose a method for exploiting available translation resources simultaneously. This method employs Learning to Rank(LTR) for exploiting different translation resources. To apply LTR methods for query translation, we define different translation relation based features in addition to context based features. We use the contextual information contained in translation resources for extracting context based features.The proposed method uses LTR to construct a translation ranking model based on defined features. The constructed model is used for ranking translation candidates of query words. To evaluate the proposed method we do English-Persian CLIR, in which we employ the translation ranking model to find translations of English queries and employ the translations to retrieve Persian documents. Experimental results show that our approach significantly outperforms single resource based CLIR methods.