 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability Analysis of Domain Adapted Dense Retrievers
Jan 24, 2025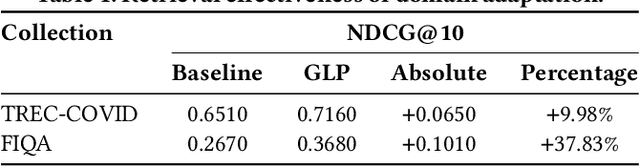



Dense retrievers have demonstrated significant potential for neural information retrieval; however, they exhibit a lack of robustness to domain shifts, thereby limiting their efficacy in zero-shot settings across diverse domains. Previous research has investigated unsupervised domain adaptation techniques to adapt dense retrievers to target domains. However, these studies have not focused on explainability analysis to understand how such adaptations alter the model's behavior. In this paper, we propose utilizing the integrated gradients framework to develop an interpretability method that provides both instance-based and ranking-based explanations for dense retrievers. To generate these explanations, we introduce a novel baseline that reveals both query and document attributions. This method is used to analyze the effects of domain adaptation on input attributions for query and document tokens across two datasets: the financial question answering dataset (FIQA) and the biomedical information retrieval dataset (TREC-COVID). Our visualizations reveal that domain-adapted models focus more on in-domain terminology compared to non-adapted models, exemplified by terms such as "hedge," "gold," "corona," and "disease." This research addresses how unsupervised domain adaptation techniques influence the behavior of dense retrievers when adapted to new domains. Additionally, we demonstrate that integrated gradients are a viable choice for explaining and analyzing the internal mechanisms of these opaque neural models.
Remining Hard Negatives for Generative Pseudo Labeled Domain Adaptation
Jan 24, 2025



Dense retrievers have demonstrated significant potential for neural information retrieval; however, they exhibit a lack of robustness to domain shifts, thereby limiting their efficacy in zero-shot settings across diverse domains. A state-of-the-art domain adaptation technique is Generative Pseudo Labeling (GPL). GPL uses synthetic query generation and initially mined hard negatives to distill knowledge from cross-encoder to dense retrievers in the target domain. In this paper, we analyze the documents retrieved by the domain-adapted model and discover that these are more relevant to the target queries than those of the non-domain-adapted model. We then propose refreshing the hard-negative index during the knowledge distillation phase to mine better hard negatives. Our remining R-GPL approach boosts ranking performance in 13/14 BEIR datasets and 9/12 LoTTe datasets. Our contributions are (i) analyzing hard negatives returned by domain-adapted and non-domain-adapted models and (ii) applying the GPL training with and without hard-negative re-mining in LoTTE and BEIR datasets.
On Correlating Factors for Domain Adaptation Performance
Jan 24, 2025Dense retrievers have demonstrated significant potential for neural information retrieval; however, they lack robustness to domain shifts, limiting their efficacy in zero-shot settings across diverse domains. In this paper, we set out to analyze the possible factors that lead to successful domain adaptation of dense retrievers. We include domain similarity proxies between generated queries to test and source domains. Furthermore, we conduct a case study comparing two powerful domain adaptation techniques. We find that generated query type distribution is an important factor, and generating queries that share a similar domain to the test documents improves the performance of domain adaptation methods. This study further emphasizes the importance of domain-tailored generated queries.
The Role of Complex NLP in Transformers for Text Ranking?
Jul 06, 2022

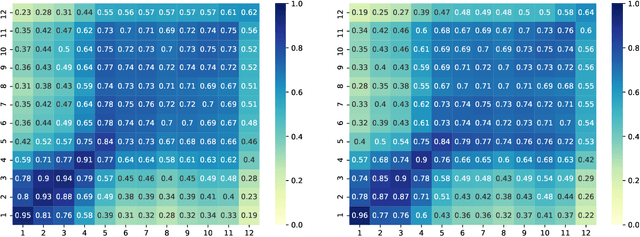
Even though term-based methods such as BM25 provide strong baselines in ranking, under certain conditions they are dominated by large pre-trained masked language models (MLMs) such as BERT. To date, the source of their effectiveness remains unclear. Is it their ability to truly understand the meaning through modeling syntactic aspects? We answer this by manipulating the input order and position information in a way that destroys the natural sequence order of query and passage and shows that the model still achieves comparable performance. Overall, our results highlight that syntactic aspects do not play a critical role in the effectiveness of re-ranking with BERT. We point to other mechanisms such as query-passage cross-attention and richer embeddings that capture word meanings based on aggregated context regardless of the word order for being the main attributions for its superior performance.
How Different are Pre-trained Transformers for Text Ranking?
Apr 05, 2022


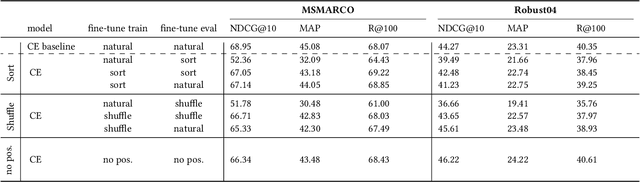
In recent years, large pre-trained transformers have led to substantial gains in performance over traditional retrieval models and feedback approaches. However, these results are primarily based on the MS Marco/TREC Deep Learning Track setup, with its very particular setup, and our understanding of why and how these models work better is fragmented at best. We analyze effective BERT-based cross-encoders versus traditional BM25 ranking for the passage retrieval task where the largest gains have been observed, and investigate two main questions. On the one hand, what is similar? To what extent does the neural ranker already encompass the capacity of traditional rankers? Is the gain in performance due to a better ranking of the same documents (prioritizing precision)? On the other hand, what is different? Can it retrieve effectively documents missed by traditional systems (prioritizing recall)? We discover substantial differences in the notion of relevance identifying strengths and weaknesses of BERT that may inspire research for future improvement. Our results contribute to our understanding of (black-box) neural rankers relative to (well-understood) traditional rankers, help understand the particular experimental setting of MS-Marco-based test collections.
HiTR: Hierarchical Topic Model Re-estimation for Measuring Topical Diversity of Documents
Oct 12, 2018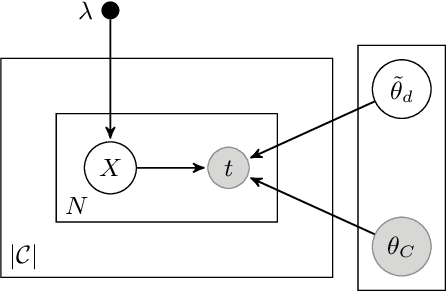

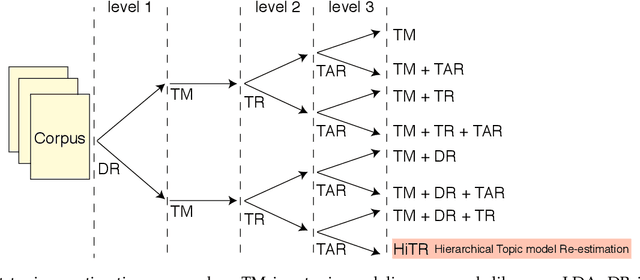
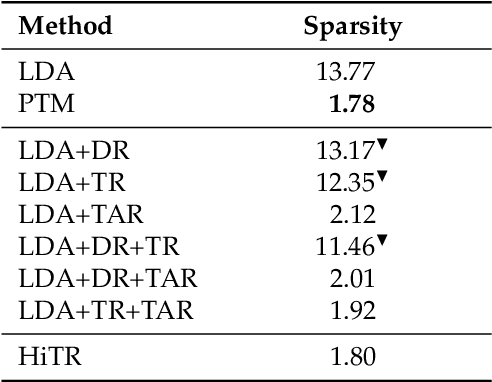
A high degree of topical diversity is often considered to be an important characteristic of interesting text documents. A recent proposal for measuring topical diversity identifies three distributions for assessing the diversity of documents: distributions of words within documents, words within topics, and topics within documents. Topic models play a central role in this approach and, hence, their quality is crucial to the efficacy of measuring topical diversity. The quality of topic models is affected by two causes: generality and impurity of topics. General topics only include common information of a background corpus and are assigned to most of the documents. Impure topics contain words that are not related to the topic. Impurity lowers the interpretability of topic models. Impure topics are likely to get assigned to documents erroneously. We propose a hierarchical re-estimation process aimed at removing generality and impurity. Our approach has three re-estimation components: (1) document re-estimation, which removes general words from the documents; (2) topic re-estimation, which re-estimates the distribution over words of each topic; and (3) topic assignment re-estimation, which re-estimates for each document its distributions over topics. For measuring topical diversity of text documents, our HiTR approach improves over the state-of-the-art measured on PubMed dataset.
Learning to Rank from Samples of Variable Quality
Jun 21, 2018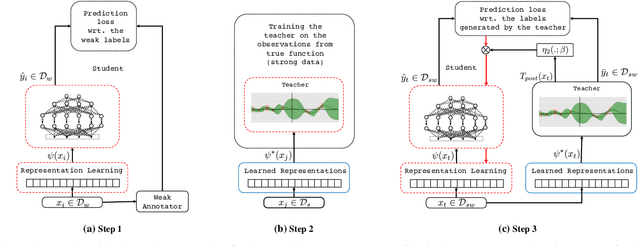
Training deep neural networks requires many training samples, but in practice, training labels are expensive to obtain and may be of varying quality, as some may be from trusted expert labelers while others might be from heuristics or other sources of weak supervision such as crowd-sourcing. This creates a fundamental quality-versus quantity trade-off in the learning process. Do we learn from the small amount of high-quality data or the potentially large amount of weakly-labeled data? We argue that if the learner could somehow know and take the label-quality into account when learning the data representation, we could get the best of both worlds. To this end, we introduce "fidelity-weighted learning" (FWL), a semi-supervised student-teacher approach for training deep neural networks using weakly-labeled data. FWL modulates the parameter updates to a student network (trained on the task we care about) on a per-sample basis according to the posterior confidence of its label-quality estimated by a teacher (who has access to the high-quality labels). Both student and teacher are learned from the data. We evaluate FWL on document ranking where we outperform state-of-the-art alternative semi-supervised methods.
Fidelity-Weighted Learning
May 23, 2018
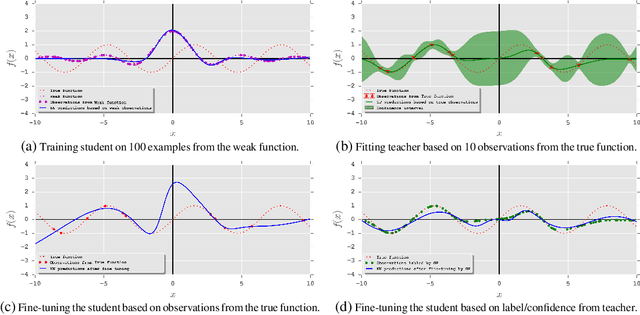
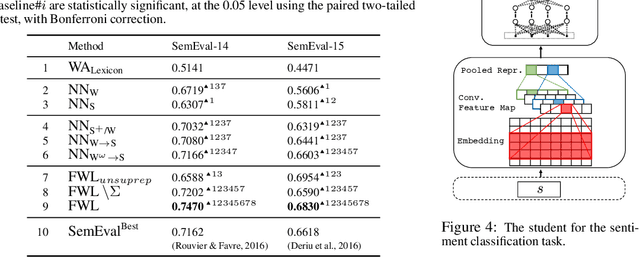
Training deep neural networks requires many training samples, but in practice training labels are expensive to obtain and may be of varying quality, as some may be from trusted expert labelers while others might be from heuristics or other sources of weak supervision such as crowd-sourcing. This creates a fundamental quality versus-quantity trade-off in the learning process. Do we learn from the small amount of high-quality data or the potentially large amount of weakly-labeled data? We argue that if the learner could somehow know and take the label-quality into account when learning the data representation, we could get the best of both worlds. To this end, we propose "fidelity-weighted learning" (FWL), a semi-supervised student-teacher approach for training deep neural networks using weakly-labeled data. FWL modulates the parameter updates to a student network (trained on the task we care about) on a per-sample basis according to the posterior confidence of its label-quality estimated by a teacher (who has access to the high-quality labels). Both student and teacher are learned from the data. We evaluate FWL on two tasks in information retrieval and natural language processing where we outperform state-of-the-art alternative semi-supervised methods, indicating that our approach makes better use of strong and weak labels, and leads to better task-dependent data representations.
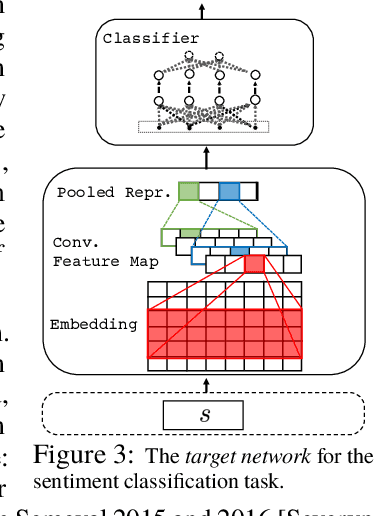
Avoiding Your Teacher's Mistakes: Training Neural Networks with Controlled Weak Supervision
Dec 07, 2017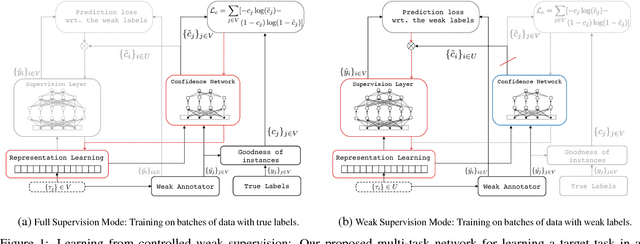
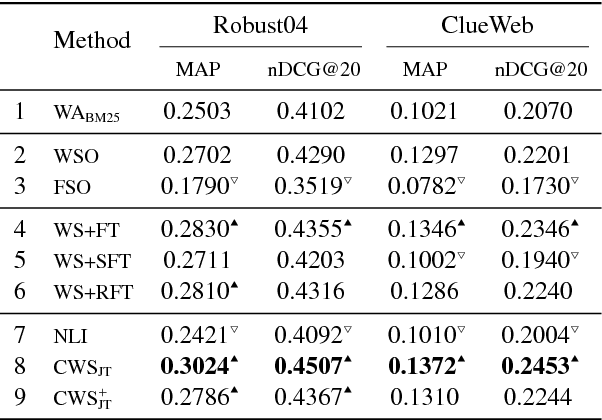
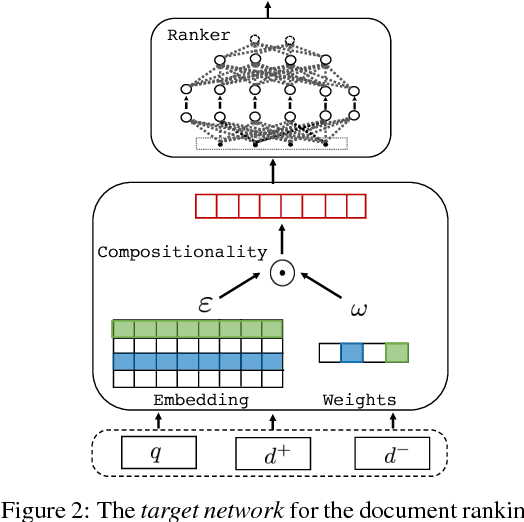
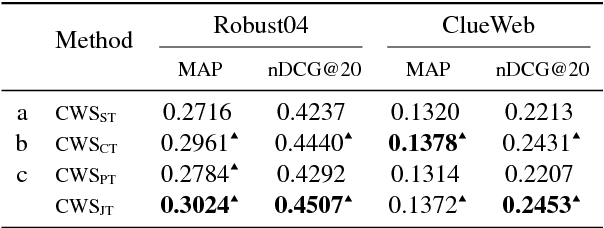
Training deep neural networks requires massive amounts of training data, but for many tasks only limited labeled data is available. This makes weak supervision attractive, using weak or noisy signals like the output of heuristic methods or user click-through data for training. In a semi-supervised setting, we can use a large set of data with weak labels to pretrain a neural network and then fine-tune the parameters with a small amount of data with true labels. This feels intuitively sub-optimal as these two independent stages leave the model unaware about the varying label quality. What if we could somehow inform the model about the label quality? In this paper, we propose a semi-supervised learning method where we train two neural networks in a multi-task fashion: a "target network" and a "confidence network". The target network is optimized to perform a given task and is trained using a large set of unlabeled data that are weakly annotated. We propose to weight the gradient updates to the target network using the scores provided by the second confidence network, which is trained on a small amount of supervised data. Thus we avoid that the weight updates computed from noisy labels harm the quality of the target network model. We evaluate our learning strategy on two different tasks: document ranking and sentiment classification. The results demonstrate that our approach not only enhances the performance compared to the baselines but also speeds up the learning process from weak labels.
Learning to Learn from Weak Supervision by Full Supervision
Nov 30, 2017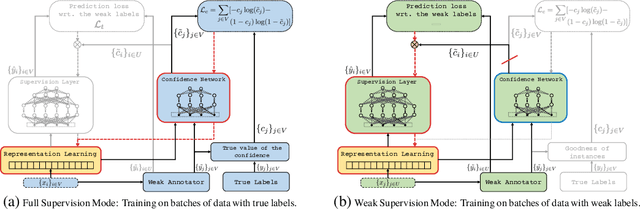
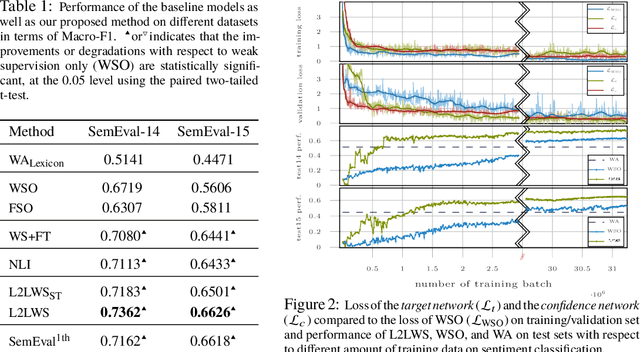
In this paper, we propose a method for training neural networks when we have a large set of data with weak labels and a small amount of data with true labels. In our proposed model, we train two neural networks: a target network, the learner and a confidence network, the meta-learner. The target network is optimized to perform a given task and is trained using a large set of unlabeled data that are weakly annotated. We propose to control the magnitude of the gradient updates to the target network using the scores provided by the second confidence network, which is trained on a small amount of supervised data. Thus we avoid that the weight updates computed from noisy labels harm the quality of the target network model.