 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe most general manner to injectively align true and predicted segments
Dec 27, 2022Kirilov et al (2019) develop a metric, called Panoptic Quality (PQ), to evaluate image segmentation methods. The metric is based on a confusion table, and compares a predicted to a ground truth segmentation. The only non straightforward part in this comparison is to align the segments in the two segmentations. A metric only works well if that alignment is a partial bijection. Kirilov et al (2019) list 3 desirable properties for a definition of alignment: it should be simple, interpretable and effectively computable. There are many definitions guaranteeing a partial bijection and these 3 properties. We present the weakest: one that is both sufficient and necessary to guarantee that the alignment is a partial bijection. This new condition is effectively computable and natural. It simply says that the number of correctly predicted elements (in image segmentation, the pixels) should be larger than the number of missed, and larger than the number of spurious elements. This is strictly weaker than the proposal in Kirilov et al (2019). In formulas, instead of |TP|> |FN\textbar| + |FP|, the weaker condition requires that |TP|> |FN| and |TP| > |FP|. We evaluate the new alignment condition theoretically and empirically.
HiTR: Hierarchical Topic Model Re-estimation for Measuring Topical Diversity of Documents
Oct 12, 2018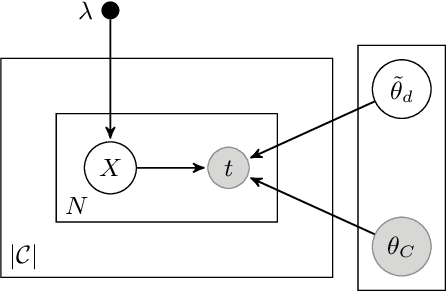

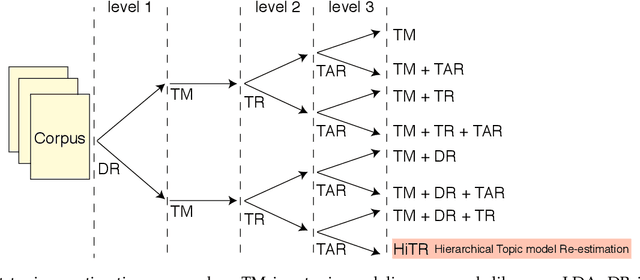
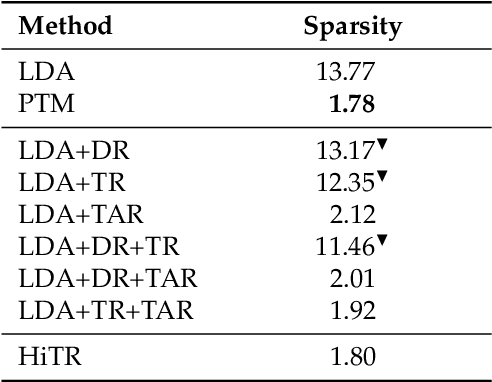
A high degree of topical diversity is often considered to be an important characteristic of interesting text documents. A recent proposal for measuring topical diversity identifies three distributions for assessing the diversity of documents: distributions of words within documents, words within topics, and topics within documents. Topic models play a central role in this approach and, hence, their quality is crucial to the efficacy of measuring topical diversity. The quality of topic models is affected by two causes: generality and impurity of topics. General topics only include common information of a background corpus and are assigned to most of the documents. Impure topics contain words that are not related to the topic. Impurity lowers the interpretability of topic models. Impure topics are likely to get assigned to documents erroneously. We propose a hierarchical re-estimation process aimed at removing generality and impurity. Our approach has three re-estimation components: (1) document re-estimation, which removes general words from the documents; (2) topic re-estimation, which re-estimates the distribution over words of each topic; and (3) topic assignment re-estimation, which re-estimates for each document its distributions over topics. For measuring topical diversity of text documents, our HiTR approach improves over the state-of-the-art measured on PubMed dataset.
Words are Malleable: Computing Semantic Shifts in Political and Media Discourse
Nov 15, 2017

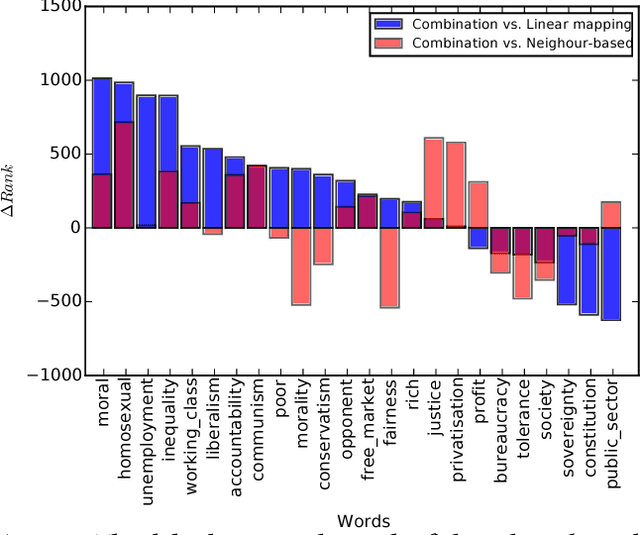
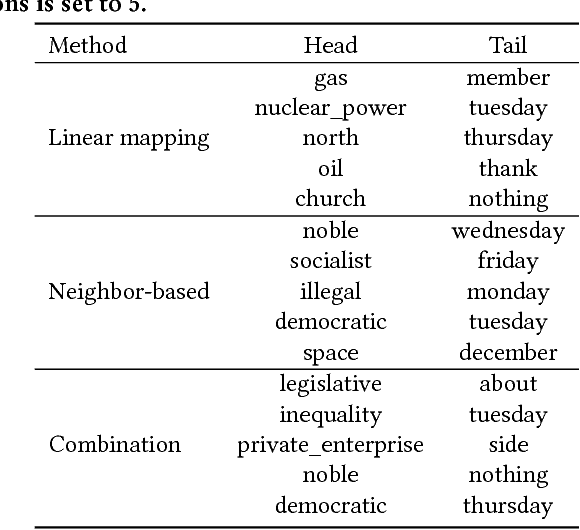
Recently, researchers started to pay attention to the detection of temporal shifts in the meaning of words. However, most (if not all) of these approaches restricted their efforts to uncovering change over time, thus neglecting other valuable dimensions such as social or political variability. We propose an approach for detecting semantic shifts between different viewpoints--broadly defined as a set of texts that share a specific metadata feature, which can be a time-period, but also a social entity such as a political party. For each viewpoint, we learn a semantic space in which each word is represented as a low dimensional neural embedded vector. The challenge is to compare the meaning of a word in one space to its meaning in another space and measure the size of the semantic shifts. We compare the effectiveness of a measure based on optimal transformations between the two spaces with a measure based on the similarity of the neighbors of the word in the respective spaces. Our experiments demonstrate that the combination of these two performs best. We show that the semantic shifts not only occur over time, but also along different viewpoints in a short period of time. For evaluation, we demonstrate how this approach captures meaningful semantic shifts and can help improve other tasks such as the contrastive viewpoint summarization and ideology detection (measured as classification accuracy) in political texts. We also show that the two laws of semantic change which were empirically shown to hold for temporal shifts also hold for shifts across viewpoints. These laws state that frequent words are less likely to shift meaning while words with many senses are more likely to do so.
On Horizontal and Vertical Separation in Hierarchical Text Classification
Sep 02, 2016


Hierarchy is a common and effective way of organizing data and representing their relationships at different levels of abstraction. However, hierarchical data dependencies cause difficulties in the estimation of "separable" models that can distinguish between the entities in the hierarchy. Extracting separable models of hierarchical entities requires us to take their relative position into account and to consider the different types of dependencies in the hierarchy. In this paper, we present an investigation of the effect of separability in text-based entity classification and argue that in hierarchical classification, a separation property should be established between entities not only in the same layer, but also in different layers. Our main findings are the followings. First, we analyse the importance of separability on the data representation in the task of classification and based on that, we introduce a "Strong Separation Principle" for optimizing expected effectiveness of classifiers decision based on separation property. Second, we present Hierarchical Significant Words Language Models (HSWLM) which capture all, and only, the essential features of hierarchical entities according to their relative position in the hierarchy resulting in horizontally and vertically separable models. Third, we validate our claims on real-world data and demonstrate that how HSWLM improves the accuracy of classification and how it provides transferable models over time. Although discussions in this paper focus on the classification problem, the models are applicable to any information access tasks on data that has, or can be mapped to, a hierarchical structure.
A Hybrid Approach to Domain-Specific Entity Linking
Sep 06, 2015
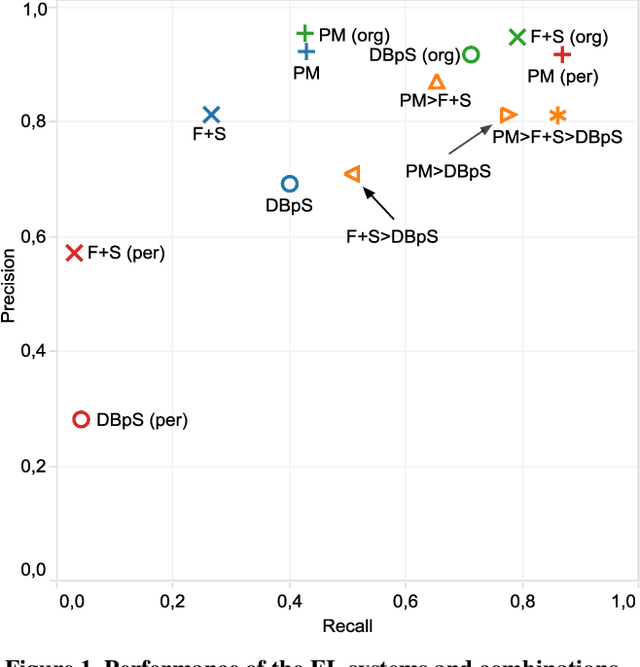
The current state-of-the-art Entity Linking (EL) systems are geared towards corpora that are as heterogeneous as the Web, and therefore perform sub-optimally on domain-specific corpora. A key open problem is how to construct effective EL systems for specific domains, as knowledge of the local context should in principle increase, rather than decrease, effectiveness. In this paper we propose the hybrid use of simple specialist linkers in combination with an existing generalist system to address this problem. Our main findings are the following. First, we construct a new reusable benchmark for EL on a corpus of domain-specific conversations. Second, we test the performance of a range of approaches under the same conditions, and show that specialist linkers obtain high precision in isolation, and high recall when combined with generalist linkers. Hence, we can effectively exploit local context and get the best of both worlds.
* SEM'15