 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Complex NLP in Transformers for Text Ranking?
Paper and Code

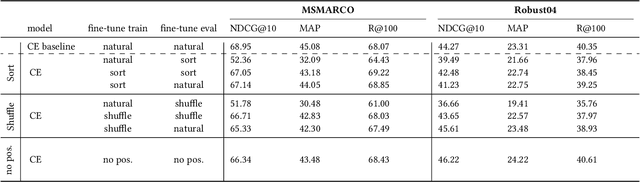
Even though term-based methods such as BM25 provide strong baselines in ranking, under certain conditions they are dominated by large pre-trained masked language models (MLMs) such as BERT. To date, the source of their effectiveness remains unclear. Is it their ability to truly understand the meaning through modeling syntactic aspects? We answer this by manipulating the input order and position information in a way that destroys the natural sequence order of query and passage and shows that the model still achieves comparable performance. Overall, our results highlight that syntactic aspects do not play a critical role in the effectiveness of re-ranking with BERT. We point to other mechanisms such as query-passage cross-attention and richer embeddings that capture word meanings based on aggregated context regardless of the word order for being the main attributions for its superior performance.