 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Transformers
Jul 10, 2018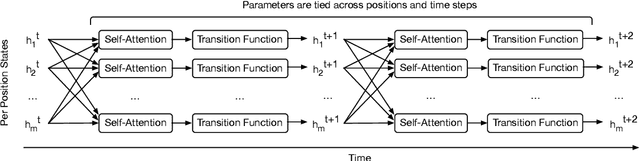
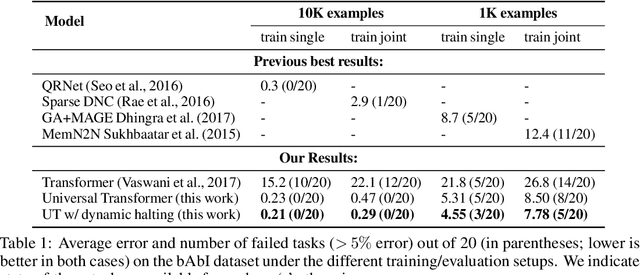
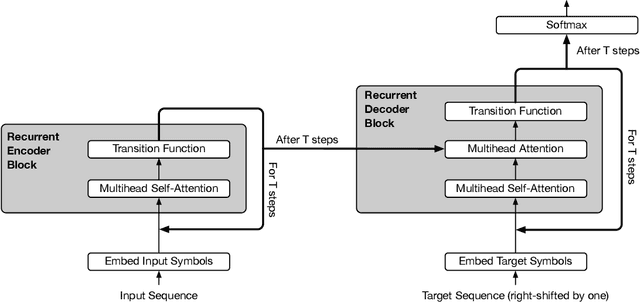
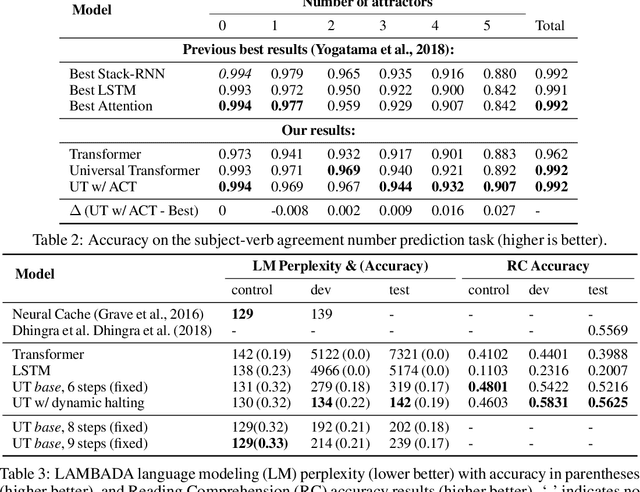
Self-attentive feed-forward sequence models have been shown to achieve impressive results on sequence modeling tasks, thereby presenting a compelling alternative to recurrent neural networks (RNNs) which has remained the de-facto standard architecture for many sequence modeling problems to date. Despite these successes, however, feed-forward sequence models like the Transformer fail to generalize in many tasks that recurrent models handle with ease (e.g. copying when the string lengths exceed those observed at training time). Moreover, and in contrast to RNNs, the Transformer model is not computationally universal, limiting its theoretical expressivity. In this paper we propose the Universal Transformer which addresses these practical and theoretical shortcomings and we show that it leads to improved performance on several tasks. Instead of recurring over the individual symbols of sequences like RNNs, the Universal Transformer repeatedly revises its representations of all symbols in the sequence with each recurrent step. In order to combine information from different parts of a sequence, it employs a self-attention mechanism in every recurrent step. Assuming sufficient memory, its recurrence makes the Universal Transformer computationally universal. We further employ an adaptive computation time (ACT) mechanism to allow the model to dynamically adjust the number of times the representation of each position in a sequence is revised. Beyond saving computation, we show that ACT can improve the accuracy of the model. Our experiments show that on various algorithmic tasks and a diverse set of large-scale language understanding tasks the Universal Transformer generalizes significantly better and outperforms both a vanilla Transformer and an LSTM in machine translation, and achieves a new state of the art on the bAbI linguistic reasoning task and the challenging LAMBADA language modeling task.
XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings
Jul 10, 2018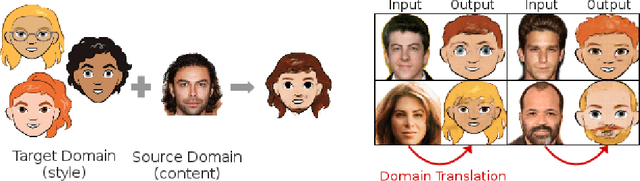

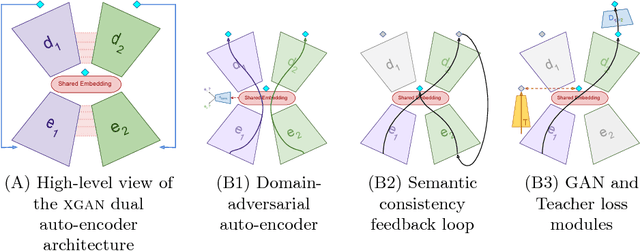

Style transfer usually refers to the task of applying color and texture information from a specific style image to a given content image while preserving the structure of the latter. Here we tackle the more generic problem of semantic style transfer: given two unpaired collections of images, we aim to learn a mapping between the corpus-level style of each collection, while preserving semantic content shared across the two domains. We introduce XGAN ("Cross-GAN"), a dual adversarial autoencoder, which captures a shared representation of the common domain semantic content in an unsupervised way, while jointly learning the domain-to-domain image translations in both directions. We exploit ideas from the domain adaptation literature and define a semantic consistency loss which encourages the model to preserve semantics in the learned embedding space. We report promising qualitative results for the task of face-to-cartoon translation. The cartoon dataset, CartoonSet, we collected for this purpose is publicly available at google.github.io/cartoonset/ as a new benchmark for semantic style transfer.
Fidelity-Weighted Learning
May 23, 2018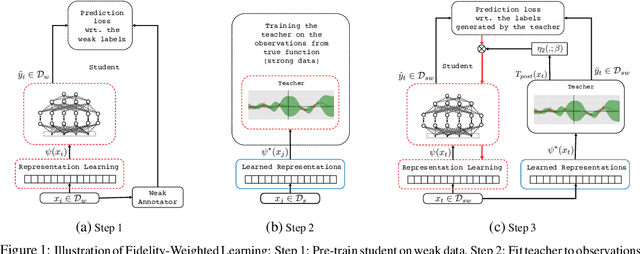
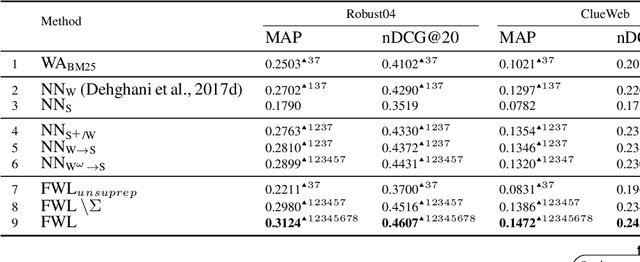
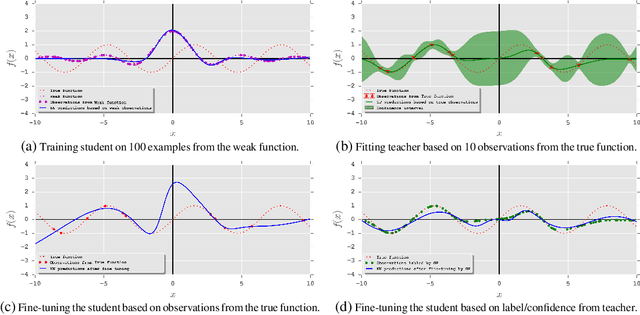
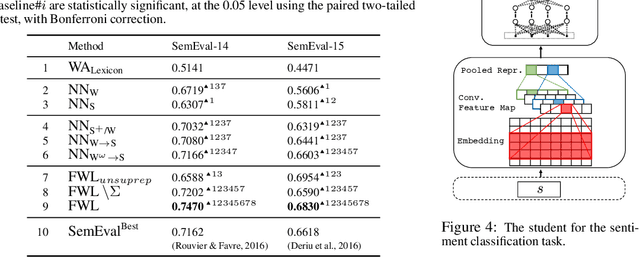
Training deep neural networks requires many training samples, but in practice training labels are expensive to obtain and may be of varying quality, as some may be from trusted expert labelers while others might be from heuristics or other sources of weak supervision such as crowd-sourcing. This creates a fundamental quality versus-quantity trade-off in the learning process. Do we learn from the small amount of high-quality data or the potentially large amount of weakly-labeled data? We argue that if the learner could somehow know and take the label-quality into account when learning the data representation, we could get the best of both worlds. To this end, we propose "fidelity-weighted learning" (FWL), a semi-supervised student-teacher approach for training deep neural networks using weakly-labeled data. FWL modulates the parameter updates to a student network (trained on the task we care about) on a per-sample basis according to the posterior confidence of its label-quality estimated by a teacher (who has access to the high-quality labels). Both student and teacher are learned from the data. We evaluate FWL on two tasks in information retrieval and natural language processing where we outperform state-of-the-art alternative semi-supervised methods, indicating that our approach makes better use of strong and weak labels, and leads to better task-dependent data representations.
Tensor2Tensor for Neural Machine Translation
Mar 16, 2018
Tensor2Tensor is a library for deep learning models that is well-suited for neural machine translation and includes the reference implementation of the state-of-the-art Transformer model.
Generating High-Quality and Informative Conversation Responses with Sequence-to-Sequence Models
Jul 31, 2017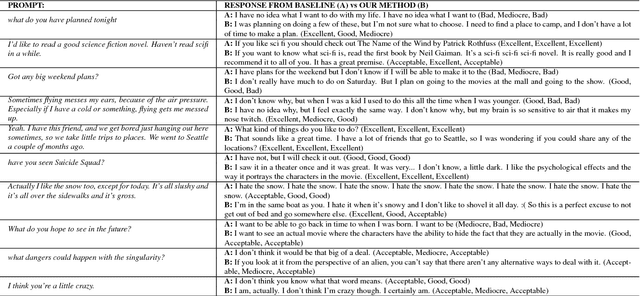

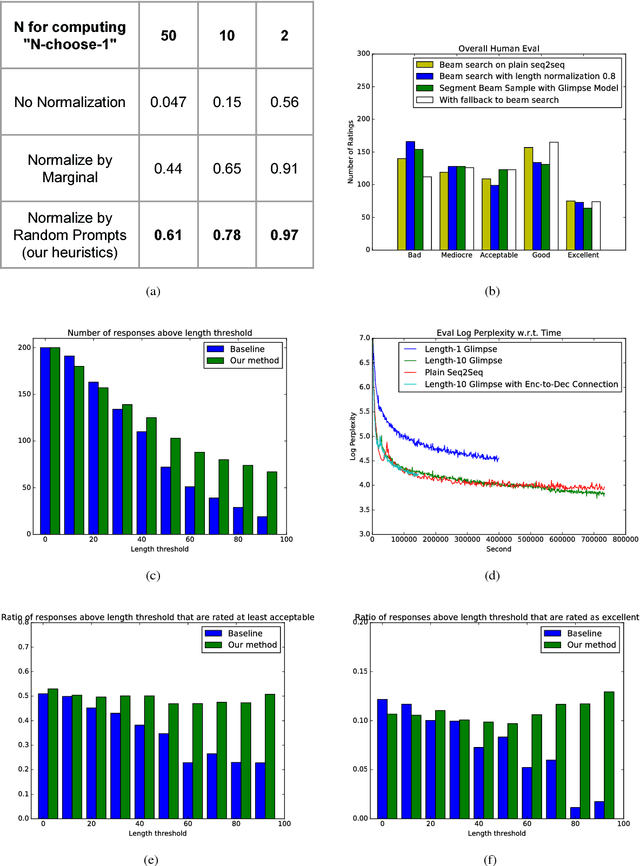
Sequence-to-sequence models have been applied to the conversation response generation problem where the source sequence is the conversation history and the target sequence is the response. Unlike translation, conversation responding is inherently creative. The generation of long, informative, coherent, and diverse responses remains a hard task. In this work, we focus on the single turn setting. We add self-attention to the decoder to maintain coherence in longer responses, and we propose a practical approach, called the glimpse-model, for scaling to large datasets. We introduce a stochastic beam-search algorithm with segment-by-segment reranking which lets us inject diversity earlier in the generation process. We trained on a combined data set of over 2.3B conversation messages mined from the web. In human evaluation studies, our method produces longer responses overall, with a higher proportion rated as acceptable and excellent as length increases, compared to baseline sequence-to-sequence models with explicit length-promotion. A back-off strategy produces better responses overall, in the full spectrum of lengths.
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Oct 08, 2016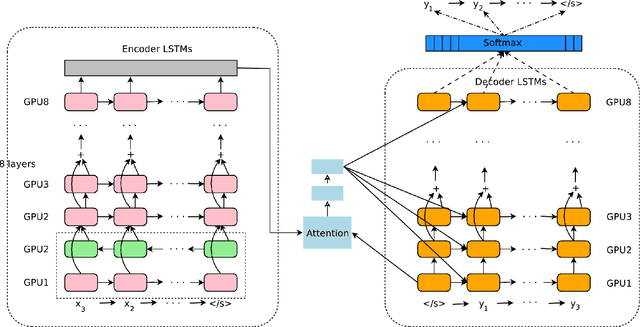

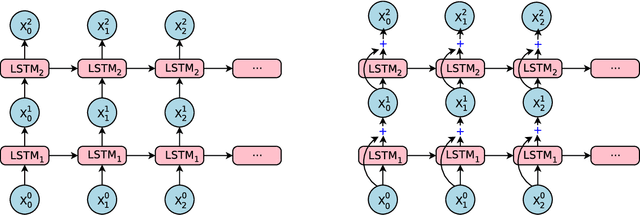
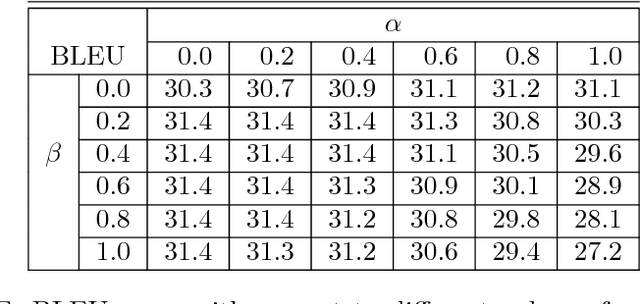
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.
BilBOWA: Fast Bilingual Distributed Representations without Word Alignments
Feb 04, 2016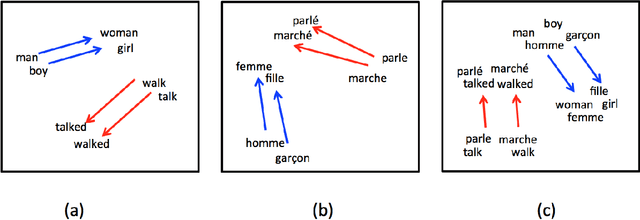



We introduce BilBOWA (Bilingual Bag-of-Words without Alignments), a simple and computationally-efficient model for learning bilingual distributed representations of words which can scale to large monolingual datasets and does not require word-aligned parallel training data. Instead it trains directly on monolingual data and extracts a bilingual signal from a smaller set of raw-text sentence-aligned data. This is achieved using a novel sampled bag-of-words cross-lingual objective, which is used to regularize two noise-contrastive language models for efficient cross-lingual feature learning. We show that bilingual embeddings learned using the proposed model outperform state-of-the-art methods on a cross-lingual document classification task as well as a lexical translation task on WMT11 data.