 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswer-Me: Multi-Task Open-Vocabulary Visual Question Answering
May 02, 2022
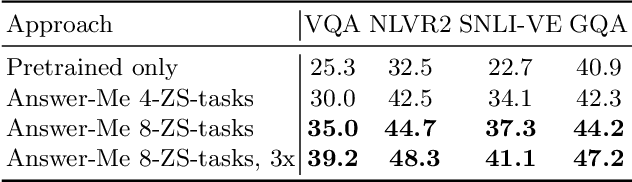
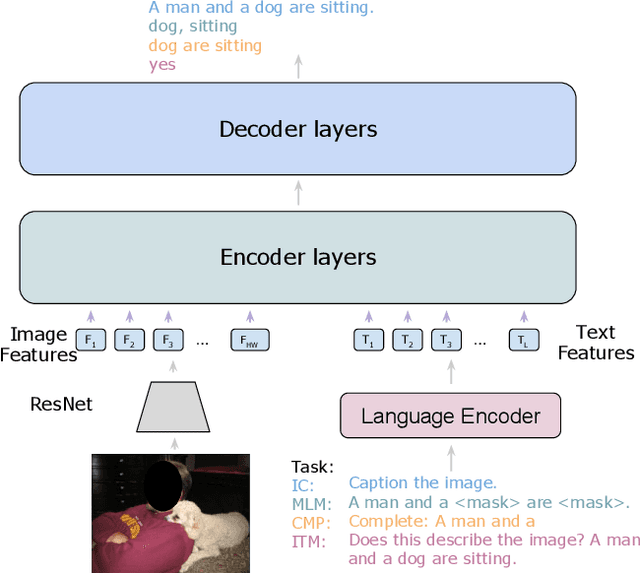
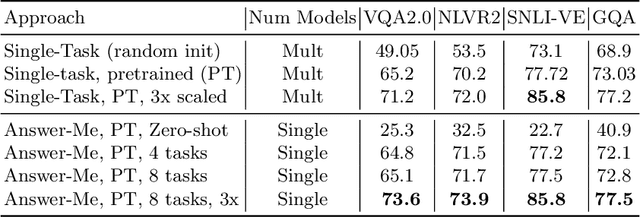
We present Answer-Me, a task-aware multi-task framework which unifies a variety of question answering tasks, such as, visual question answering, visual entailment, visual reasoning. In contrast to previous works using contrastive or generative captioning training, we propose a novel and simple recipe to pre-train a vision-language joint model, which is multi-task as well. The pre-training uses only noisy image captioning data, and is formulated to use the entire architecture end-to-end with both a strong language encoder and decoder. Our results show state-of-the-art performance, zero-shot generalization, robustness to forgetting, and competitive single-task results across a variety of question answering tasks. Our multi-task mixture training learns from tasks of various question intents and thus generalizes better, including on zero-shot vision-language tasks. We conduct experiments in the challenging multi-task and open-vocabulary settings and across a variety of datasets and tasks, such as VQA2.0, SNLI-VE, NLVR2, GQA, VizWiz. We observe that the proposed approach is able to generalize to unseen tasks and that more diverse mixtures lead to higher accuracy in both known and novel tasks.
FindIt: Generalized Localization with Natural Language Queries
Mar 31, 2022

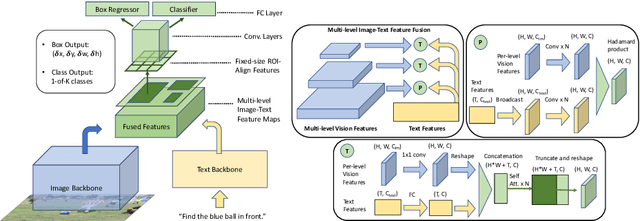
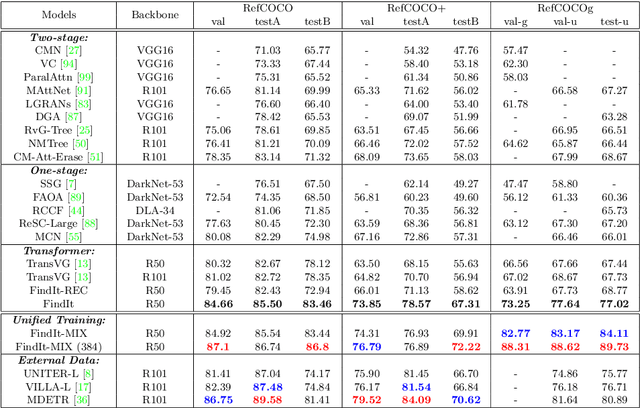
We propose FindIt, a simple and versatile framework that unifies a variety of visual grounding and localization tasks including referring expression comprehension, text-based localization, and object detection. Key to our architecture is an efficient multi-scale fusion module that unifies the disparate localization requirements across the tasks. In addition, we discover that a standard object detector is surprisingly effective in unifying these tasks without a need for task-specific design, losses, or pre-computed detections. Our end-to-end trainable framework responds flexibly and accurately to a wide range of referring expression, localization or detection queries for zero, one, or multiple objects. Jointly trained on these tasks, FindIt outperforms the state of the art on both referring expression and text-based localization, and shows competitive performance on object detection. Finally, FindIt generalizes better to out-of-distribution data and novel categories compared to strong single-task baselines. All of these are accomplished by a single, unified and efficient model. The code will be released.
SyntheticFur dataset for neural rendering
May 13, 2021

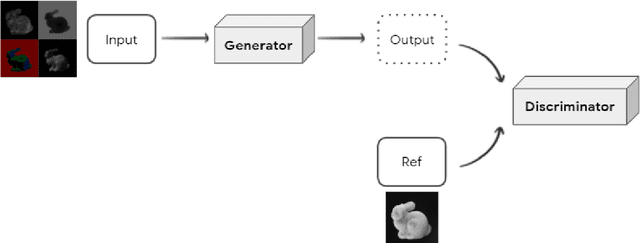

We introduce a new dataset called SyntheticFur built specifically for machine learning training. The dataset consists of ray traced synthetic fur renders with corresponding rasterized input buffers and simulation data files. We procedurally generated approximately 140,000 images and 15 simulations with Houdini. The images consist of fur groomed with different skin primitives and move with various motions in a predefined set of lighting environments. We also demonstrated how the dataset could be used with neural rendering to significantly improve fur graphics using inexpensive input buffers by training a conditional generative adversarial network with perceptual loss. We hope the availability of such high fidelity fur renders will encourage new advances with neural rendering for a variety of applications.
Learning via social awareness: Improving a deep generative sketching model with facial feedback
Aug 27, 2018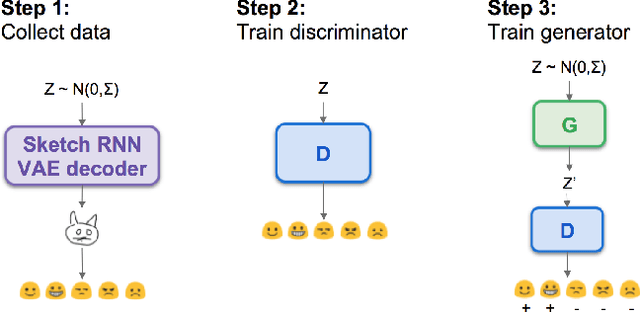
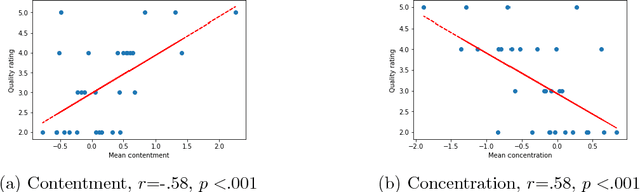
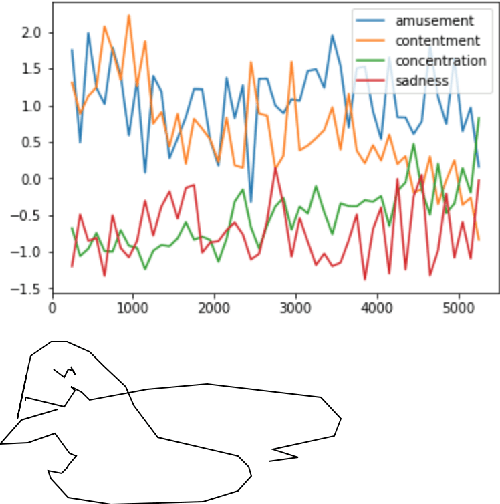
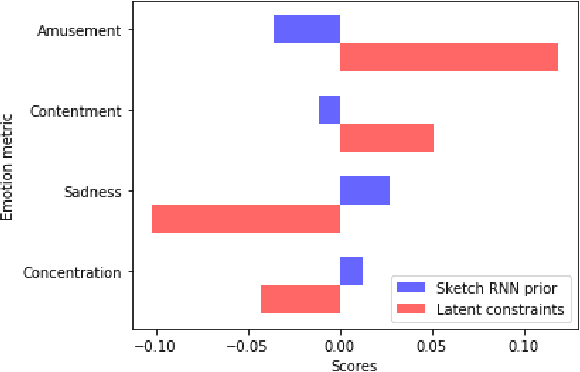
In the quest towards general artificial intelligence (AI), researchers have explored developing loss functions that act as intrinsic motivators in the absence of external rewards. This paper argues that such research has overlooked an important and useful intrinsic motivator: social interaction. We posit that making an AI agent aware of implicit social feedback from humans can allow for faster learning of more generalizable and useful representations, and could potentially impact AI safety. We collect social feedback in the form of facial expression reactions to samples from Sketch RNN, an LSTM-based variational autoencoder (VAE) designed to produce sketch drawings. We use a Latent Constraints GAN (LC-GAN) to learn from the facial feedback of a small group of viewers, by optimizing the model to produce sketches that it predicts will lead to more positive facial expressions. We show in multiple independent evaluations that the model trained with facial feedback produced sketches that are more highly rated, and induce significantly more positive facial expressions. Thus, we establish that implicit social feedback can improve the output of a deep learning model.
XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings
Jul 10, 2018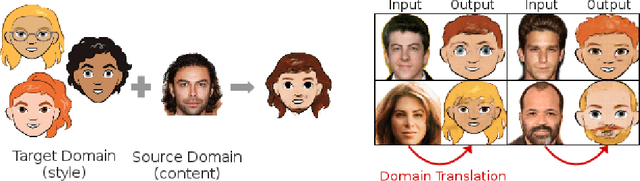

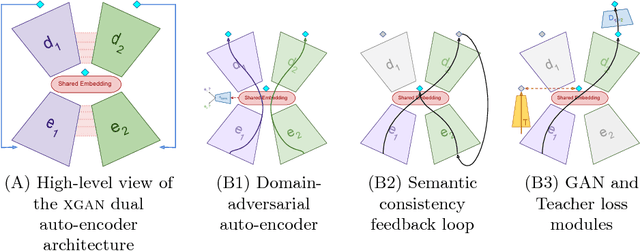

Style transfer usually refers to the task of applying color and texture information from a specific style image to a given content image while preserving the structure of the latter. Here we tackle the more generic problem of semantic style transfer: given two unpaired collections of images, we aim to learn a mapping between the corpus-level style of each collection, while preserving semantic content shared across the two domains. We introduce XGAN ("Cross-GAN"), a dual adversarial autoencoder, which captures a shared representation of the common domain semantic content in an unsupervised way, while jointly learning the domain-to-domain image translations in both directions. We exploit ideas from the domain adaptation literature and define a semantic consistency loss which encourages the model to preserve semantics in the learned embedding space. We report promising qualitative results for the task of face-to-cartoon translation. The cartoon dataset, CartoonSet, we collected for this purpose is publicly available at google.github.io/cartoonset/ as a new benchmark for semantic style transfer.
Improving image generative models with human interactions
Sep 29, 2017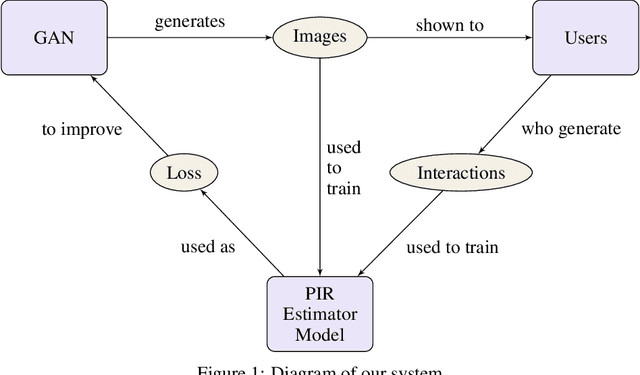
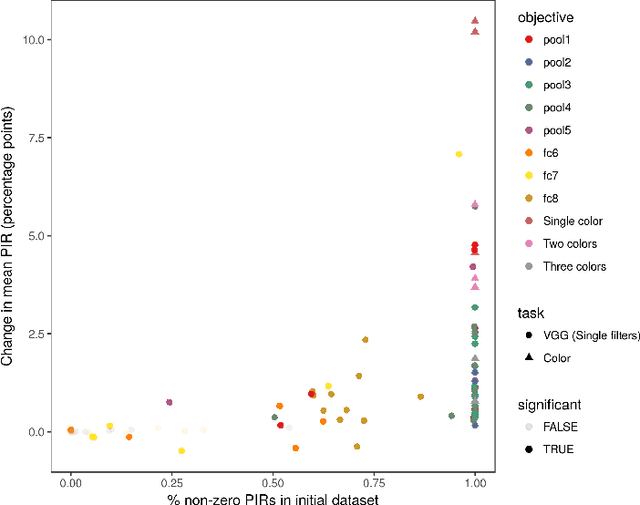
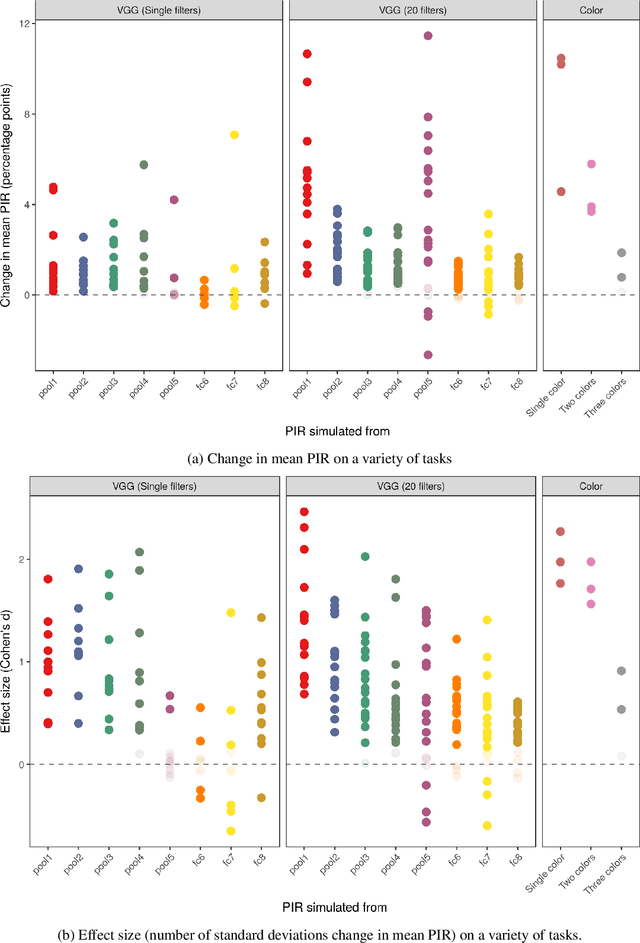

GANs provide a framework for training generative models which mimic a data distribution. However, in many cases we wish to train these generative models to optimize some auxiliary objective function within the data it generates, such as making more aesthetically pleasing images. In some cases, these objective functions are difficult to evaluate, e.g. they may require human interaction. Here, we develop a system for efficiently improving a GAN to target an objective involving human interaction, specifically generating images that increase rates of positive user interactions. To improve the generative model, we build a model of human behavior in the targeted domain from a relatively small set of interactions, and then use this behavioral model as an auxiliary loss function to improve the generative model. We show that this system is successful at improving positive interaction rates, at least on simulated data, and characterize some of the factors that affect its performance.