 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
SyntheticFur dataset for neural rendering
May 13, 2021

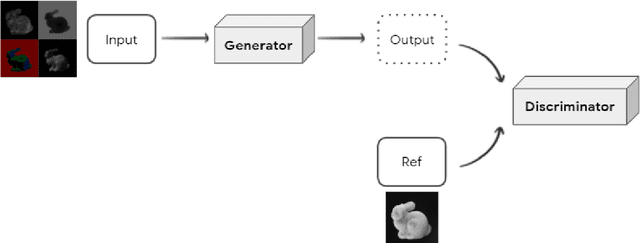

We introduce a new dataset called SyntheticFur built specifically for machine learning training. The dataset consists of ray traced synthetic fur renders with corresponding rasterized input buffers and simulation data files. We procedurally generated approximately 140,000 images and 15 simulations with Houdini. The images consist of fur groomed with different skin primitives and move with various motions in a predefined set of lighting environments. We also demonstrated how the dataset could be used with neural rendering to significantly improve fur graphics using inexpensive input buffers by training a conditional generative adversarial network with perceptual loss. We hope the availability of such high fidelity fur renders will encourage new advances with neural rendering for a variety of applications.
Likelihood Ratios for Out-of-Distribution Detection
Jun 07, 2019
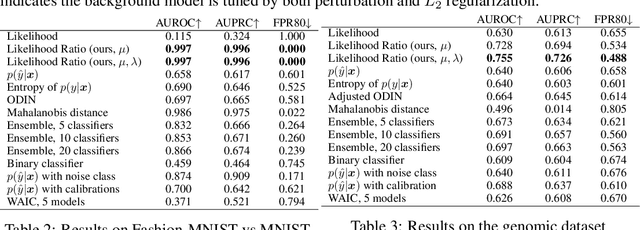

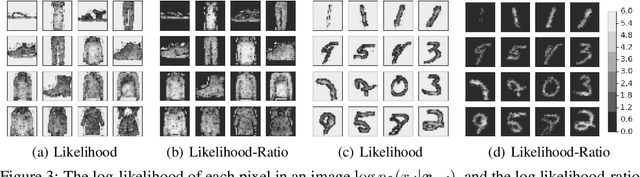
Discriminative neural networks offer little or no performance guarantees when deployed on data not generated by the same process as the training distribution. On such out-of-distribution (OOD) inputs, the prediction may not only be erroneous, but confidently so, limiting the safe deployment of classifiers in real-world applications. One such challenging application is bacteria identification based on genomic sequences, which holds the promise of early detection of diseases, but requires a model that can output low confidence predictions on OOD genomic sequences from new bacteria that were not present in the training data. We introduce a genomics dataset for OOD detection that allows other researchers to benchmark progress on this important problem. We investigate deep generative model based approaches for OOD detection and observe that the likelihood score is heavily affected by population level background statistics. We propose a likelihood ratio method for deep generative models which effectively corrects for these confounding background statistics. We benchmark the OOD detection performance of the proposed method against existing approaches on the genomics dataset and show that our method achieves state-of-the-art performance. We demonstrate the generality of the proposed method by showing that it significantly improves OOD detection when applied to deep generative models of images.
Deep learning for predicting refractive error from retinal fundus images
Dec 21, 2017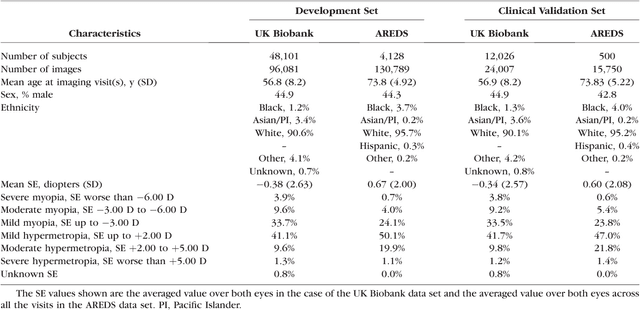
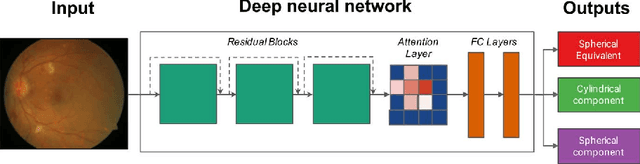
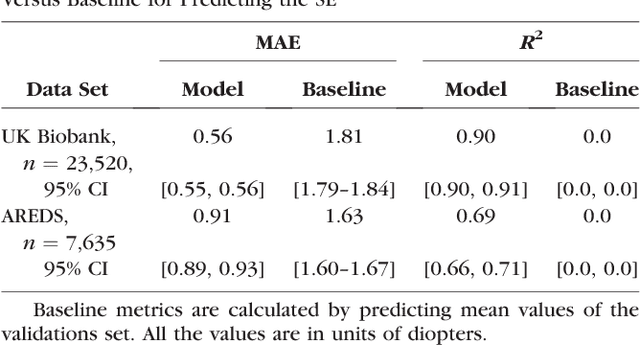
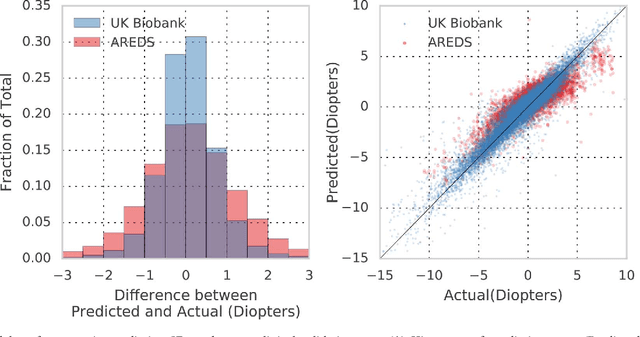
Refractive error, one of the leading cause of visual impairment, can be corrected by simple interventions like prescribing eyeglasses. We trained a deep learning algorithm to predict refractive error from the fundus photographs from participants in the UK Biobank cohort, which were 45 degree field of view images and the AREDS clinical trial, which contained 30 degree field of view images. Our model use the "attention" method to identify features that are correlated with refractive error. Mean absolute error (MAE) of the algorithm's prediction compared to the refractive error obtained in the AREDS and UK Biobank. The resulting algorithm had a MAE of 0.56 diopters (95% CI: 0.55-0.56) for estimating spherical equivalent on the UK Biobank dataset and 0.91 diopters (95% CI: 0.89-0.92) for the AREDS dataset. The baseline expected MAE (obtained by simply predicting the mean of this population) was 1.81 diopters (95% CI: 1.79-1.84) for UK Biobank and 1.63 (95% CI: 1.60-1.67) for AREDS. Attention maps suggested that the foveal region was one of the most important areas used by the algorithm to make this prediction, though other regions also contribute to the prediction. The ability to estimate refractive error with high accuracy from retinal fundus photos has not been previously known and demonstrates that deep learning can be applied to make novel predictions from medical images. Given that several groups have recently shown that it is feasible to obtain retinal fundus photos using mobile phones and inexpensive attachments, this work may be particularly relevant in regions of the world where autorefractors may not be readily available.