 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindIt: Generalized Localization with Natural Language Queries
Paper and Code


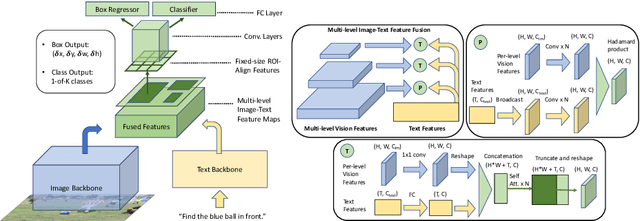
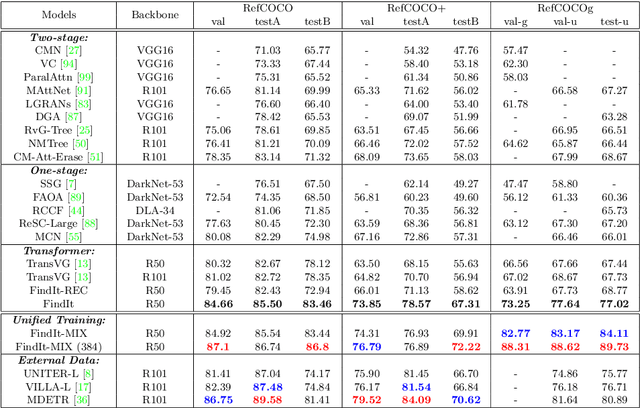
We propose FindIt, a simple and versatile framework that unifies a variety of visual grounding and localization tasks including referring expression comprehension, text-based localization, and object detection. Key to our architecture is an efficient multi-scale fusion module that unifies the disparate localization requirements across the tasks. In addition, we discover that a standard object detector is surprisingly effective in unifying these tasks without a need for task-specific design, losses, or pre-computed detections. Our end-to-end trainable framework responds flexibly and accurately to a wide range of referring expression, localization or detection queries for zero, one, or multiple objects. Jointly trained on these tasks, FindIt outperforms the state of the art on both referring expression and text-based localization, and shows competitive performance on object detection. Finally, FindIt generalizes better to out-of-distribution data and novel categories compared to strong single-task baselines. All of these are accomplished by a single, unified and efficient model. The code will be released.