 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Grounding from Generative Vision and Language Model
Jul 18, 2024



Visual grounding tasks aim to localize image regions based on natural language references. In this work, we explore whether generative VLMs predominantly trained on image-text data could be leveraged to scale up the text annotation of visual grounding data. We find that grounding knowledge already exists in generative VLM and can be elicited by proper prompting. We thus prompt a VLM to generate object-level descriptions by feeding it object regions from existing object detection datasets. We further propose attribute modeling to explicitly capture the important object attributes, and spatial relation modeling to capture inter-object relationship, both of which are common linguistic pattern in referring expression. Our constructed dataset (500K images, 1M objects, 16M referring expressions) is one of the largest grounding datasets to date, and the first grounding dataset with purely model-generated queries and human-annotated objects. To verify the quality of this data, we conduct zero-shot transfer experiments to the popular RefCOCO benchmarks for both referring expression comprehension (REC) and segmentation (RES) tasks. On both tasks, our model significantly outperform the state-of-the-art approaches without using human annotated visual grounding data. Our results demonstrate the promise of generative VLM to scale up visual grounding in the real world. Code and models will be released.
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Jan 04, 2024



3D panoptic segmentation is a challenging perception task, which aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing to novel categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not achieve good performance due to poor per-mask classification quality on novel categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms strong baselines by a large margin.
Detection-Oriented Image-Text Pretraining for Open-Vocabulary Detection
Sep 29, 2023



We present a new open-vocabulary detection approach based on detection-oriented image-text pretraining to bridge the gap between image-level pretraining and open-vocabulary object detection. At the pretraining phase, we replace the commonly used classification architecture with the detector architecture, which better serves the region-level recognition needs of detection by enabling the detector heads to learn from noisy image-text pairs. Using only standard contrastive loss and no pseudo-labeling, our approach is a simple yet effective extension of the contrastive learning method to learn emergent object-semantic cues. In addition, we propose a shifted-window learning approach upon window attention to make the backbone representation more robust, translation-invariant, and less biased by the window pattern. On the popular LVIS open-vocabulary detection benchmark, our approach sets a new state of the art of 40.4 mask AP$_r$ using the common ViT-L backbone, significantly outperforming the best existing approach by +6.5 mask AP$_r$ at system level. On the COCO benchmark, we achieve very competitive 40.8 novel AP without pseudo labeling or weak supervision. In addition, we evaluate our approach on the transfer detection setup, where ours outperforms the baseline significantly. Visualization reveals emerging object locality from the pretraining recipes compared to the baseline. Code and models will be publicly released.
Contrastive Feature Masking Open-Vocabulary Vision Transformer
Sep 02, 2023



We present Contrastive Feature Masking Vision Transformer (CFM-ViT) - an image-text pretraining methodology that achieves simultaneous learning of image- and region-level representation for open-vocabulary object detection (OVD). Our approach combines the masked autoencoder (MAE) objective into the contrastive learning objective to improve the representation for localization tasks. Unlike standard MAE, we perform reconstruction in the joint image-text embedding space, rather than the pixel space as is customary with the classical MAE method, which causes the model to better learn region-level semantics. Moreover, we introduce Positional Embedding Dropout (PED) to address scale variation between image-text pretraining and detection finetuning by randomly dropping out the positional embeddings during pretraining. PED improves detection performance and enables the use of a frozen ViT backbone as a region classifier, preventing the forgetting of open-vocabulary knowledge during detection finetuning. On LVIS open-vocabulary detection benchmark, CFM-ViT achieves a state-of-the-art 33.9 AP$r$, surpassing the best approach by 7.6 points and achieves better zero-shot detection transfer. Finally, CFM-ViT acquires strong image-level representation, outperforming the state of the art on 8 out of 12 metrics on zero-shot image-text retrieval benchmarks.
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model
Jun 02, 2023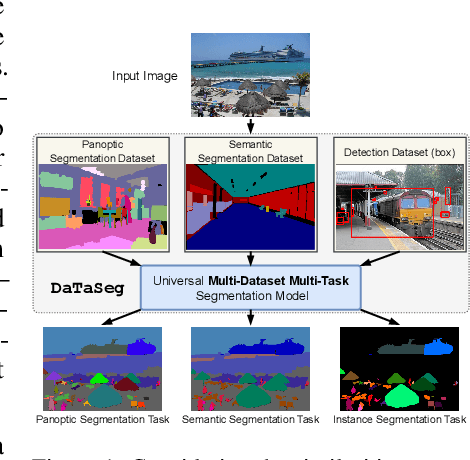
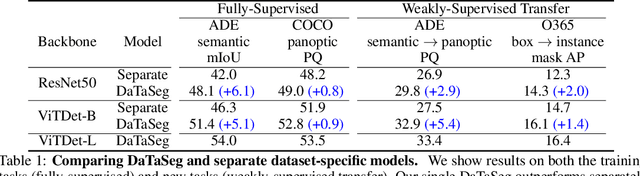
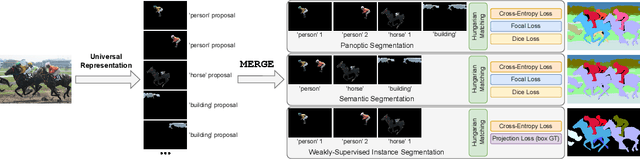
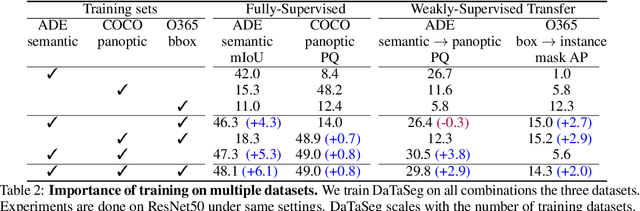
Observing the close relationship among panoptic, semantic and instance segmentation tasks, we propose to train a universal multi-dataset multi-task segmentation model: DaTaSeg.We use a shared representation (mask proposals with class predictions) for all tasks. To tackle task discrepancy, we adopt different merge operations and post-processing for different tasks. We also leverage weak-supervision, allowing our segmentation model to benefit from cheaper bounding box annotations. To share knowledge across datasets, we use text embeddings from the same semantic embedding space as classifiers and share all network parameters among datasets. We train DaTaSeg on ADE semantic, COCO panoptic, and Objects365 detection datasets. DaTaSeg improves performance on all datasets, especially small-scale datasets, achieving 54.0 mIoU on ADE semantic and 53.5 PQ on COCO panoptic. DaTaSeg also enables weakly-supervised knowledge transfer on ADE panoptic and Objects365 instance segmentation. Experiments show DaTaSeg scales with the number of training datasets and enables open-vocabulary segmentation through direct transfer. In addition, we annotate an Objects365 instance segmentation set of 1,000 images and will release it as a public benchmark.
Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers
May 11, 2023



We present Region-aware Open-vocabulary Vision Transformers (RO-ViT) - a contrastive image-text pretraining recipe to bridge the gap between image-level pretraining and open-vocabulary object detection. At the pretraining phase, we propose to randomly crop and resize regions of positional embeddings instead of using the whole image positional embeddings. This better matches the use of positional embeddings at region-level in the detection finetuning phase. In addition, we replace the common softmax cross entropy loss in contrastive learning with focal loss to better learn the informative yet difficult examples. Finally, we leverage recent advances in novel object proposals to improve open-vocabulary detection finetuning. We evaluate our full model on the LVIS and COCO open-vocabulary detection benchmarks and zero-shot transfer. RO-ViT achieves a state-of-the-art 32.1 $AP_r$ on LVIS, surpassing the best existing approach by +5.8 points in addition to competitive zero-shot transfer detection. Surprisingly, RO-ViT improves the image-level representation as well and achieves the state of the art on 9 out of 12 metrics on COCO and Flickr image-text retrieval benchmarks, outperforming competitive approaches with larger models.
RECLIP: Resource-efficient CLIP by Training with Small Images
Apr 12, 2023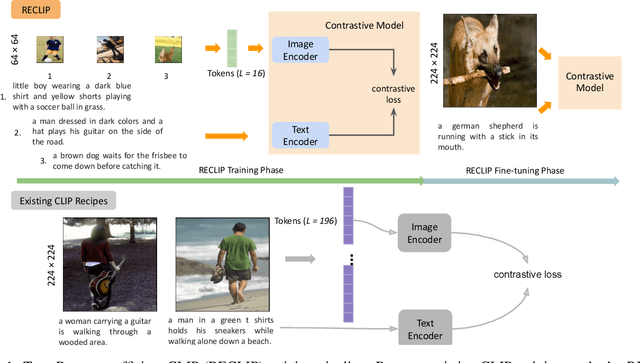
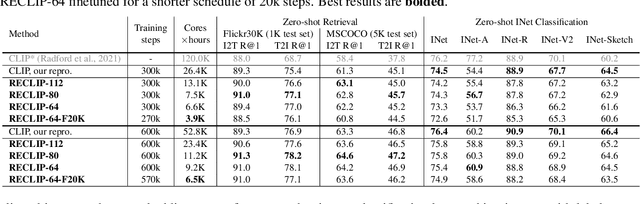


We present RECLIP (Resource-efficient CLIP), a simple method that minimizes computational resource footprint for CLIP (Contrastive Language Image Pretraining). Inspired by the notion of coarse-to-fine in computer vision, we leverage small images to learn from large-scale language supervision efficiently, and finetune the model with high-resolution data in the end. Since the complexity of the vision transformer heavily depends on input image size, our approach significantly reduces the training resource requirements both in theory and in practice. Using the same batch size and training epoch, RECLIP achieves highly competitive zero-shot classification and image text retrieval accuracy with 6 to 8$\times$ less computational resources and 7 to 9$\times$ fewer FLOPs than the baseline. Compared to the state-of-the-art contrastive learning methods, RECLIP demonstrates 5 to 59$\times$ training resource savings while maintaining highly competitive zero-shot classification and retrieval performance. We hope this work will pave the path for the broader research community to explore language supervised pretraining in more resource-friendly settings.
MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
Mar 30, 2023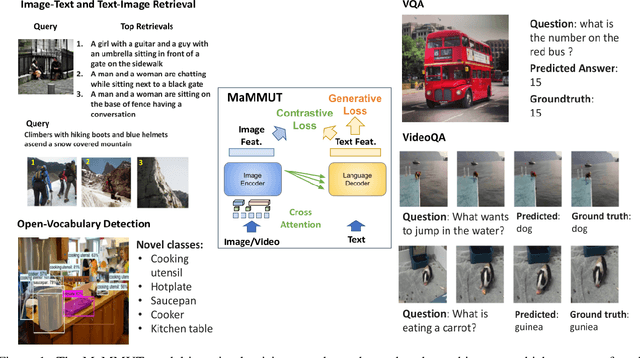
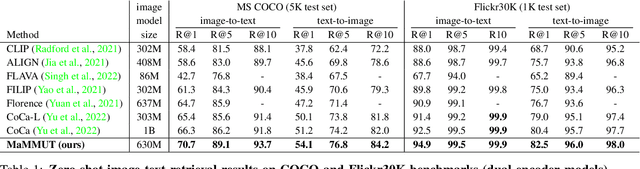
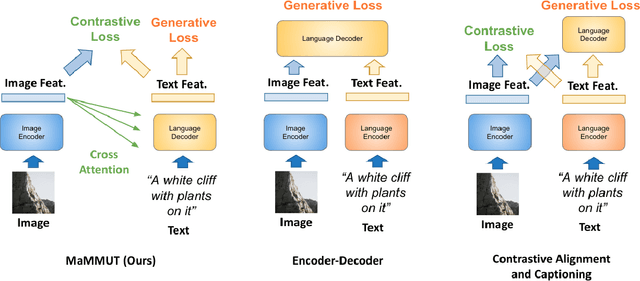
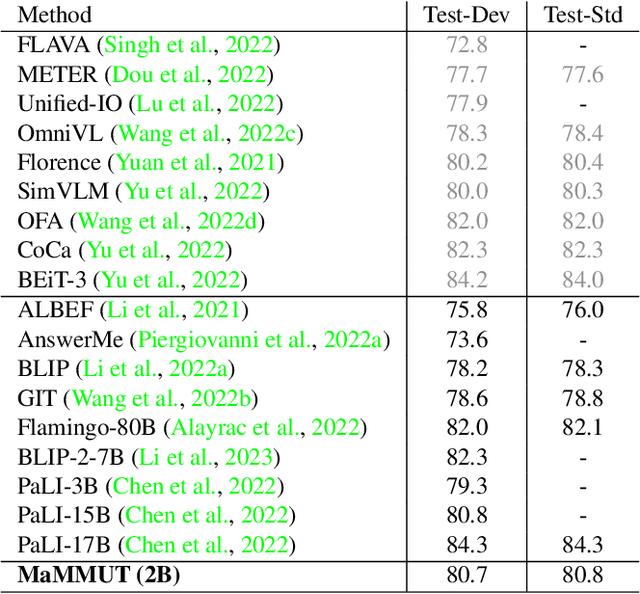
The development of language models have moved from encoder-decoder to decoder-only designs. In addition, the common knowledge has it that the two most popular multimodal tasks, the generative and contrastive tasks, tend to conflict with one another, are hard to accommodate in one architecture, and further need complex adaptations for downstream tasks. We propose a novel paradigm of training with a decoder-only model for multimodal tasks, which is surprisingly effective in jointly learning of these disparate vision-language tasks. This is done with a simple model, called MaMMUT. It consists of a single vision encoder and a text decoder, and is able to accommodate contrastive and generative learning by a novel two-pass approach on the text decoder. We demonstrate that joint learning of these diverse objectives is simple, effective, and maximizes the weight-sharing of the model across these tasks. Furthermore, the same architecture enables straightforward extensions to open-vocabulary object detection and video-language tasks. The model tackles a diverse range of tasks, while being modest in capacity. Our model achieves the state of the art on image-text and text-image retrieval, video question answering and open-vocabulary detection tasks, outperforming much larger and more extensively trained foundational models. It shows very competitive results on VQA and Video Captioning, especially considering its capacity. Ablations confirm the flexibility and advantages of our approach.
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning
Dec 06, 2022We present a simple approach which can turn a ViT encoder into an efficient video model, which can seamlessly work with both image and video inputs. By sparsely sampling the inputs, the model is able to do training and inference from both inputs. The model is easily scalable and can be adapted to large-scale pre-trained ViTs without requiring full finetuning. The model achieves SOTA results and the code will be open-sourced.
F-VLM: Open-Vocabulary Object Detection upon Frozen Vision and Language Models
Sep 30, 2022
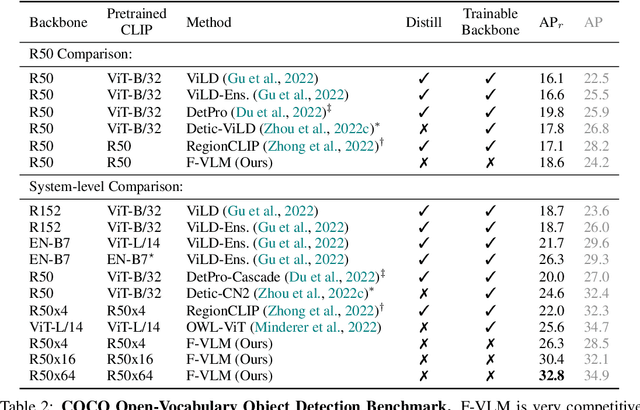


We present F-VLM, a simple open-vocabulary object detection method built upon Frozen Vision and Language Models. F-VLM simplifies the current multi-stage training pipeline by eliminating the need for knowledge distillation or detection-tailored pretraining. Surprisingly, we observe that a frozen VLM: 1) retains the locality-sensitive features necessary for detection, and 2) is a strong region classifier. We finetune only the detector head and combine the detector and VLM outputs for each region at inference time. F-VLM shows compelling scaling behavior and achieves +6.5 mask AP improvement over the previous state of the art on novel categories of LVIS open-vocabulary detection benchmark. In addition, we demonstrate very competitive results on COCO open-vocabulary detection benchmark and cross-dataset transfer detection, in addition to significant training speed-up and compute savings. Code will be released.