 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Grounding from Generative Vision and Language Model
Jul 18, 2024



Visual grounding tasks aim to localize image regions based on natural language references. In this work, we explore whether generative VLMs predominantly trained on image-text data could be leveraged to scale up the text annotation of visual grounding data. We find that grounding knowledge already exists in generative VLM and can be elicited by proper prompting. We thus prompt a VLM to generate object-level descriptions by feeding it object regions from existing object detection datasets. We further propose attribute modeling to explicitly capture the important object attributes, and spatial relation modeling to capture inter-object relationship, both of which are common linguistic pattern in referring expression. Our constructed dataset (500K images, 1M objects, 16M referring expressions) is one of the largest grounding datasets to date, and the first grounding dataset with purely model-generated queries and human-annotated objects. To verify the quality of this data, we conduct zero-shot transfer experiments to the popular RefCOCO benchmarks for both referring expression comprehension (REC) and segmentation (RES) tasks. On both tasks, our model significantly outperform the state-of-the-art approaches without using human annotated visual grounding data. Our results demonstrate the promise of generative VLM to scale up visual grounding in the real world. Code and models will be released.
MaskConver: Revisiting Pure Convolution Model for Panoptic Segmentation
Dec 11, 2023In recent years, transformer-based models have dominated panoptic segmentation, thanks to their strong modeling capabilities and their unified representation for both semantic and instance classes as global binary masks. In this paper, we revisit pure convolution model and propose a novel panoptic architecture named MaskConver. MaskConver proposes to fully unify things and stuff representation by predicting their centers. To that extent, it creates a lightweight class embedding module that can break the ties when multiple centers co-exist in the same location. Furthermore, our study shows that the decoder design is critical in ensuring that the model has sufficient context for accurate detection and segmentation. We introduce a powerful ConvNeXt-UNet decoder that closes the performance gap between convolution- and transformerbased models. With ResNet50 backbone, our MaskConver achieves 53.6% PQ on the COCO panoptic val set, outperforming the modern convolution-based model, Panoptic FCN, by 9.3% as well as transformer-based models such as Mask2Former (+1.7% PQ) and kMaX-DeepLab (+0.6% PQ). Additionally, MaskConver with a MobileNet backbone reaches 37.2% PQ, improving over Panoptic-DeepLab by +6.4% under the same FLOPs/latency constraints. A further optimized version of MaskConver achieves 29.7% PQ, while running in real-time on mobile devices. The code and model weights will be publicly available
Person Re-identification Using Visual Attention
Jun 25, 2018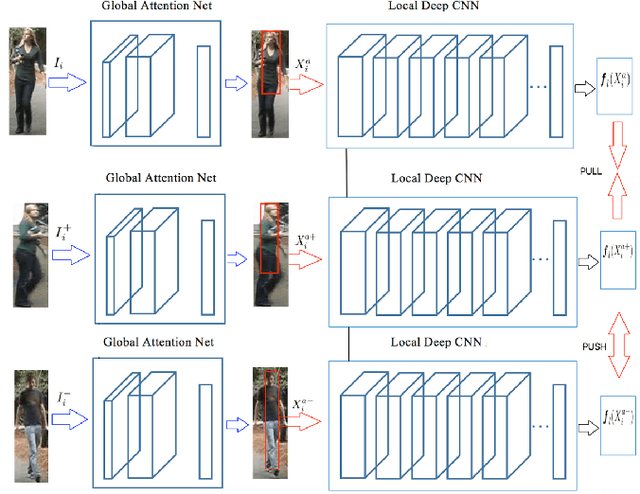
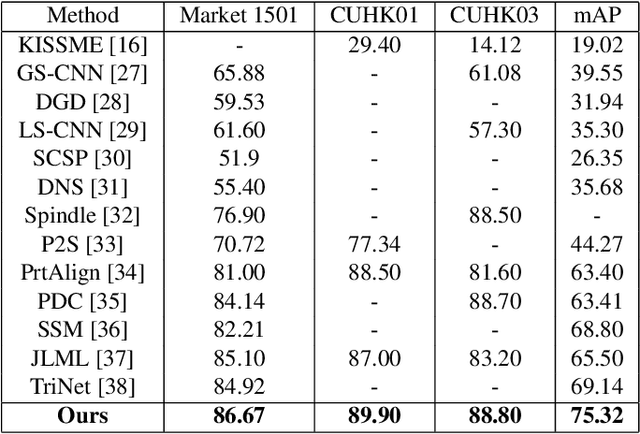


Despite recent attempts for solving the person re-identification problem, it remains a challenging task since a person's appearance can vary significantly when large variations in view angle, human pose and illumination are involved. The concept of attention is one of the most interesting recent architectural innovations in neural networks. Inspired by that, in this paper we propose a novel approach based on using a gradient-based attention mechanism in deep convolution neural network for solving the person re-identification problem. Our model learns to focus selectively on parts of the input image for which the networks' output is most sensitive to. Extensive comparative evaluations demonstrate that the proposed method outperforms state-of-the-art approaches, including both traditional and deep neural network-based methods on the challenging CUHK01, CUHK03, and Market1501 datasets.
Feature Encoding in Band-limited Distributed Surveillance Systems
Jun 06, 2017

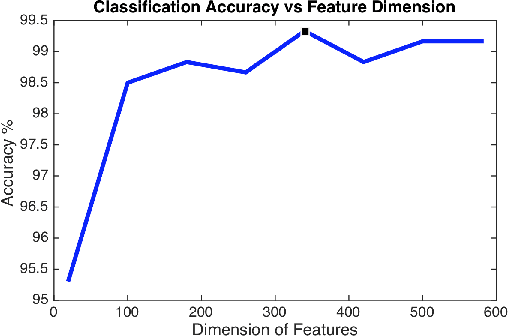
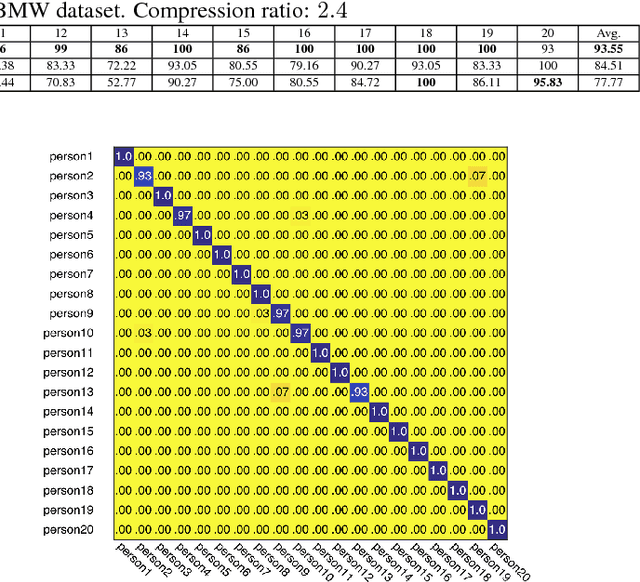
Distributed surveillance systems have become popular in recent years due to security concerns. However, transmitting high dimensional data in bandwidth-limited distributed systems becomes a major challenge. In this paper, we address this issue by proposing a novel probabilistic algorithm based on the divergence between the probability distributions of the visual features in order to reduce their dimensionality and thus save the network bandwidth in distributed wireless smart camera networks. We demonstrate the effectiveness of the proposed approach through extensive experiments on two surveillance recognition tasks.
End-to-end Binary Representation Learning via Direct Binary Embedding
Jun 04, 2017
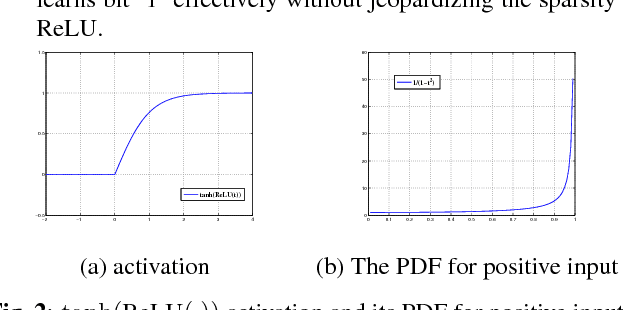

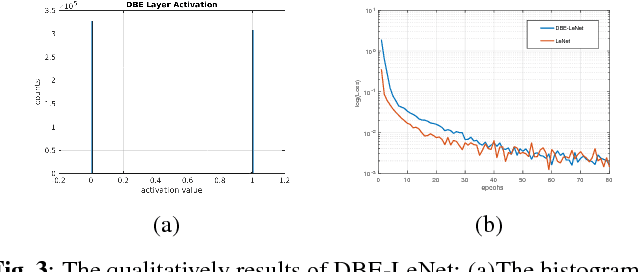
Learning binary representation is essential to large-scale computer vision tasks. Most existing algorithms require a separate quantization constraint to learn effective hashing functions. In this work, we present Direct Binary Embedding (DBE), a simple yet very effective algorithm to learn binary representation in an end-to-end fashion. By appending an ingeniously designed DBE layer to the deep convolutional neural network (DCNN), DBE learns binary code directly from the continuous DBE layer activation without quantization error. By employing the deep residual network (ResNet) as DCNN component, DBE captures rich semantics from images. Furthermore, in the effort of handling multilabel images, we design a joint cross entropy loss that includes both softmax cross entropy and weighted binary cross entropy in consideration of the correlation and independence of labels, respectively. Extensive experiments demonstrate the significant superiority of DBE over state-of-the-art methods on tasks of natural object recognition, image retrieval and image annotation.
Multi-View Task-Driven Recognition in Visual Sensor Networks
May 31, 2017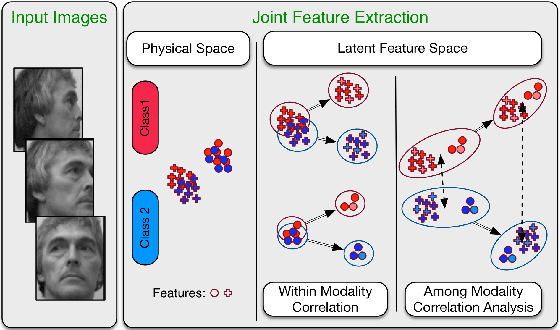



Nowadays, distributed smart cameras are deployed for a wide set of tasks in several application scenarios, ranging from object recognition, image retrieval, and forensic applications. Due to limited bandwidth in distributed systems, efficient coding of local visual features has in fact been an active topic of research. In this paper, we propose a novel approach to obtain a compact representation of high-dimensional visual data using sensor fusion techniques. We convert the problem of visual analysis in resource-limited scenarios to a multi-view representation learning, and we show that the key to finding properly compressed representation is to exploit the position of cameras with respect to each other as a norm-based regularization in the particular signal representation of sparse coding. Learning the representation of each camera is viewed as an individual task and a multi-task learning with joint sparsity for all nodes is employed. The proposed representation learning scheme is referred to as the multi-view task-driven learning for visual sensor network (MT-VSN). We demonstrate that MT-VSN outperforms state-of-the-art in various surveillance recognition tasks.
Addressing Ambiguity in Multi-target Tracking by Hierarchical Strategy
May 30, 2017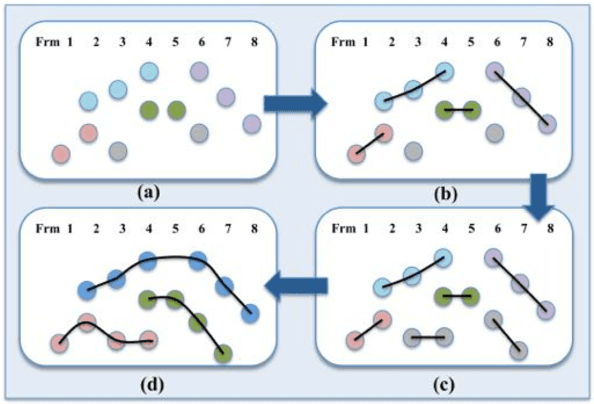
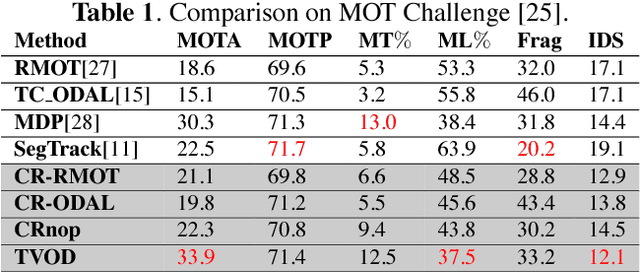
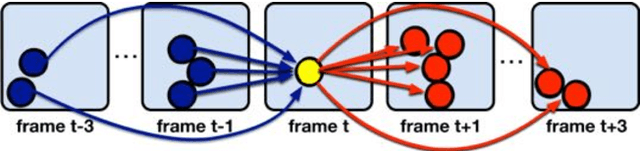
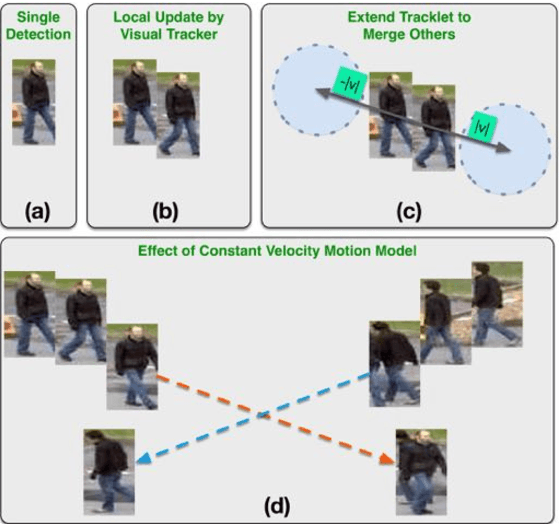
This paper presents a novel hierarchical approach for the simultaneous tracking of multiple targets in a video. We use a network flow approach to link detections in low-level and tracklets in high-level. At each step of the hierarchy, the confidence of candidates is measured by using a new scoring system, ConfRank, that considers the quality and the quantity of its neighborhood. The output of the first stage is a collection of safe tracklets and unlinked high-confidence detections. For each individual detection, we determine if it belongs to an existing or is a new tracklet. We show the effect of our framework to recover missed detections and reduce switch identity. The proposed tracker is referred to as TVOD for multi-target tracking using the visual tracker and generic object detector. We achieve competitive results with lower identity switches on several datasets comparing to state-of-the-art.