 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Task-Driven Recognition in Visual Sensor Networks
Paper and Code
May 31, 2017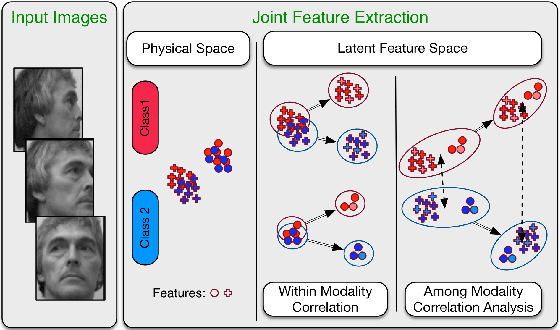



Nowadays, distributed smart cameras are deployed for a wide set of tasks in several application scenarios, ranging from object recognition, image retrieval, and forensic applications. Due to limited bandwidth in distributed systems, efficient coding of local visual features has in fact been an active topic of research. In this paper, we propose a novel approach to obtain a compact representation of high-dimensional visual data using sensor fusion techniques. We convert the problem of visual analysis in resource-limited scenarios to a multi-view representation learning, and we show that the key to finding properly compressed representation is to exploit the position of cameras with respect to each other as a norm-based regularization in the particular signal representation of sparse coding. Learning the representation of each camera is viewed as an individual task and a multi-task learning with joint sparsity for all nodes is employed. The proposed representation learning scheme is referred to as the multi-view task-driven learning for visual sensor network (MT-VSN). We demonstrate that MT-VSN outperforms state-of-the-art in various surveillance recognition tasks.