 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT5Gemma 2: Seeing, Reading, and Understanding Longer
Dec 23, 2025We introduce T5Gemma 2, the next generation of the T5Gemma family of lightweight open encoder-decoder models, featuring strong multilingual, multimodal and long-context capabilities. T5Gemma 2 follows the adaptation recipe (via UL2) in T5Gemma -- adapting a pretrained decoder-only model into an encoder-decoder model, and extends it from text-only regime to multimodal based on the Gemma 3 models. We further propose two methods to improve the efficiency: tied word embedding that shares all embeddings across encoder and decoder, and merged attention that unifies decoder self- and cross-attention into a single joint module. Experiments demonstrate the generality of the adaptation strategy over architectures and modalities as well as the unique strength of the encoder-decoder architecture on long context modeling. Similar to T5Gemma, T5Gemma 2 yields comparable or better pretraining performance and significantly improved post-training performance than its Gemma 3 counterpart. We release the pretrained models (270M-270M, 1B-1B and 4B-4B) to the community for future research.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Improving Multi-Agent Debate with Sparse Communication Topology
Jun 17, 2024Multi-agent debate has proven effective in improving large language models quality for reasoning and factuality tasks. While various role-playing strategies in multi-agent debates have been explored, in terms of the communication among agents, existing approaches adopt a brute force algorithm -- each agent can communicate with all other agents. In this paper, we systematically investigate the effect of communication connectivity in multi-agent systems. Our experiments on GPT and Mistral models reveal that multi-agent debates leveraging sparse communication topology can achieve comparable or superior performance while significantly reducing computational costs. Furthermore, we extend the multi-agent debate framework to multimodal reasoning and alignment labeling tasks, showcasing its broad applicability and effectiveness. Our findings underscore the importance of communication connectivity on enhancing the efficiency and effectiveness of the "society of minds" approach.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
MaskConver: Revisiting Pure Convolution Model for Panoptic Segmentation
Dec 11, 2023In recent years, transformer-based models have dominated panoptic segmentation, thanks to their strong modeling capabilities and their unified representation for both semantic and instance classes as global binary masks. In this paper, we revisit pure convolution model and propose a novel panoptic architecture named MaskConver. MaskConver proposes to fully unify things and stuff representation by predicting their centers. To that extent, it creates a lightweight class embedding module that can break the ties when multiple centers co-exist in the same location. Furthermore, our study shows that the decoder design is critical in ensuring that the model has sufficient context for accurate detection and segmentation. We introduce a powerful ConvNeXt-UNet decoder that closes the performance gap between convolution- and transformerbased models. With ResNet50 backbone, our MaskConver achieves 53.6% PQ on the COCO panoptic val set, outperforming the modern convolution-based model, Panoptic FCN, by 9.3% as well as transformer-based models such as Mask2Former (+1.7% PQ) and kMaX-DeepLab (+0.6% PQ). Additionally, MaskConver with a MobileNet backbone reaches 37.2% PQ, improving over Panoptic-DeepLab by +6.4% under the same FLOPs/latency constraints. A further optimized version of MaskConver achieves 29.7% PQ, while running in real-time on mobile devices. The code and model weights will be publicly available
Non-Intrusive Adaptation: Input-Centric Parameter-efficient Fine-Tuning for Versatile Multimodal Modeling
Oct 18, 2023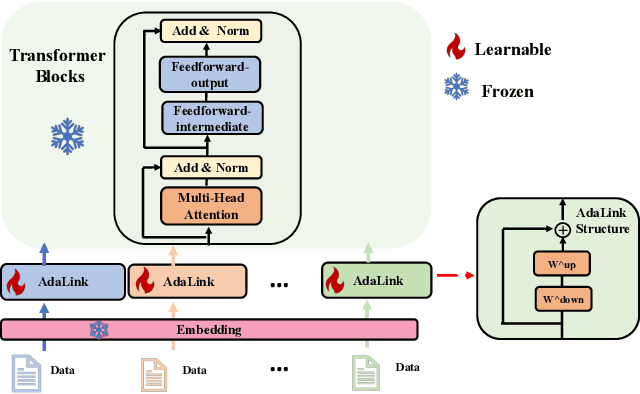



Large language models (LLMs) and vision language models (VLMs) demonstrate excellent performance on a wide range of tasks by scaling up parameter counts from O(10^9) to O(10^{12}) levels and further beyond. These large scales make it impossible to adapt and deploy fully specialized models given a task of interest. Parameter-efficient fine-tuning (PEFT) emerges as a promising direction to tackle the adaptation and serving challenges for such large models. We categorize PEFT techniques into two types: intrusive and non-intrusive. Intrusive PEFT techniques directly change a model's internal architecture. Though more flexible, they introduce significant complexities for training and serving. Non-intrusive PEFT techniques leave the internal architecture unchanged and only adapt model-external parameters, such as embeddings for input. In this work, we describe AdaLink as a non-intrusive PEFT technique that achieves competitive performance compared to SoTA intrusive PEFT (LoRA) and full model fine-tuning (FT) on various tasks. We evaluate using both text-only and multimodal tasks, with experiments that account for both parameter-count scaling and training regime (with and without instruction tuning).