 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Intrusive Adaptation: Input-Centric Parameter-efficient Fine-Tuning for Versatile Multimodal Modeling
Oct 18, 2023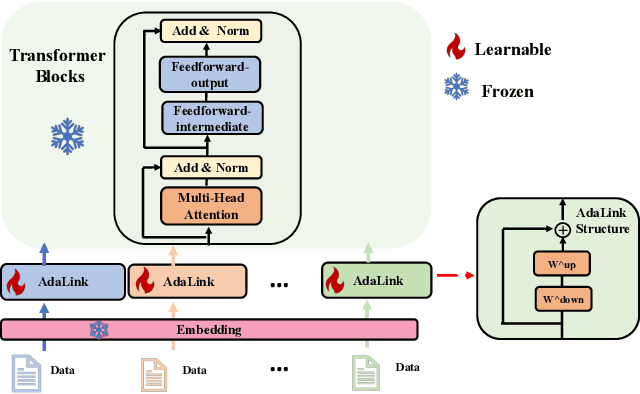



Large language models (LLMs) and vision language models (VLMs) demonstrate excellent performance on a wide range of tasks by scaling up parameter counts from O(10^9) to O(10^{12}) levels and further beyond. These large scales make it impossible to adapt and deploy fully specialized models given a task of interest. Parameter-efficient fine-tuning (PEFT) emerges as a promising direction to tackle the adaptation and serving challenges for such large models. We categorize PEFT techniques into two types: intrusive and non-intrusive. Intrusive PEFT techniques directly change a model's internal architecture. Though more flexible, they introduce significant complexities for training and serving. Non-intrusive PEFT techniques leave the internal architecture unchanged and only adapt model-external parameters, such as embeddings for input. In this work, we describe AdaLink as a non-intrusive PEFT technique that achieves competitive performance compared to SoTA intrusive PEFT (LoRA) and full model fine-tuning (FT) on various tasks. We evaluate using both text-only and multimodal tasks, with experiments that account for both parameter-count scaling and training regime (with and without instruction tuning).