 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetrical Joint Learning Support-query Prototypes for Few-shot Segmentation
Jul 27, 2024



We propose Sym-Net, a novel framework for Few-Shot Segmentation (FSS) that addresses the critical issue of intra-class variation by jointly learning both query and support prototypes in a symmetrical manner. Unlike previous methods that generate query prototypes solely by matching query features to support prototypes, which is a form of bias learning towards the few-shot support samples, Sym-Net leverages a balanced symmetrical learning approach for both query and support prototypes, ensuring that the learning process does not favor one set (support or query) over the other. One of main modules of Sym-Net is the visual-text alignment-based prototype aggregation module, which is not just query-guided prototype refinement, it is a jointly learning from both support and query samples, which makes the model beneficial for handling intra-class discrepancies and allows it to generalize better to new, unseen classes. Specifically, a parameter-free prior mask generation module is designed to accurately localize both local and global regions of the query object by using sliding windows of different sizes and a self-activation kernel to suppress incorrect background matches. Additionally, to address the information loss caused by spatial pooling during prototype learning, a top-down hyper-correlation module is integrated to capture multi-scale spatial relationships between support and query images. This approach is further jointly optimized by implementing a co-optimized hard triplet mining strategy. Experimental results show that the proposed Sym-Net outperforms state-of-the-art models, which demonstrates that jointly learning support-query prototypes in a symmetrical manner for FSS offers a promising direction to enhance segmentation performance with limited annotated data.
RepSGG: Novel Representations of Entities and Relationships for Scene Graph Generation
Sep 06, 2023Scene Graph Generation (SGG) has achieved significant progress recently. However, most previous works rely heavily on fixed-size entity representations based on bounding box proposals, anchors, or learnable queries. As each representation's cardinality has different trade-offs between performance and computation overhead, extracting highly representative features efficiently and dynamically is both challenging and crucial for SGG. In this work, a novel architecture called RepSGG is proposed to address the aforementioned challenges, formulating a subject as queries, an object as keys, and their relationship as the maximum attention weight between pairwise queries and keys. With more fine-grained and flexible representation power for entities and relationships, RepSGG learns to sample semantically discriminative and representative points for relationship inference. Moreover, the long-tailed distribution also poses a significant challenge for generalization of SGG. A run-time performance-guided logit adjustment (PGLA) strategy is proposed such that the relationship logits are modified via affine transformations based on run-time performance during training. This strategy encourages a more balanced performance between dominant and rare classes. Experimental results show that RepSGG achieves the state-of-the-art or comparable performance on the Visual Genome and Open Images V6 datasets with fast inference speed, demonstrating the efficacy and efficiency of the proposed methods.
RECLIP: Resource-efficient CLIP by Training with Small Images
Apr 12, 2023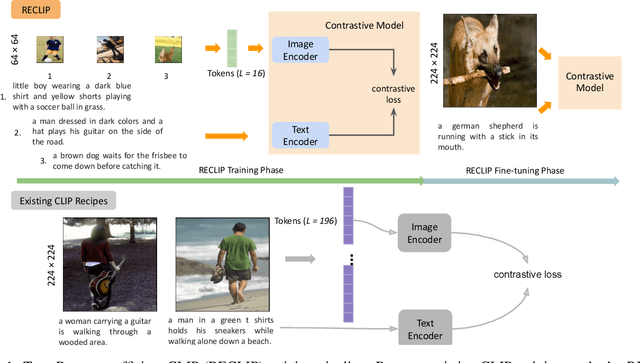
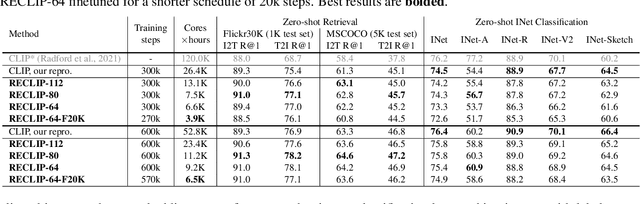


We present RECLIP (Resource-efficient CLIP), a simple method that minimizes computational resource footprint for CLIP (Contrastive Language Image Pretraining). Inspired by the notion of coarse-to-fine in computer vision, we leverage small images to learn from large-scale language supervision efficiently, and finetune the model with high-resolution data in the end. Since the complexity of the vision transformer heavily depends on input image size, our approach significantly reduces the training resource requirements both in theory and in practice. Using the same batch size and training epoch, RECLIP achieves highly competitive zero-shot classification and image text retrieval accuracy with 6 to 8$\times$ less computational resources and 7 to 9$\times$ fewer FLOPs than the baseline. Compared to the state-of-the-art contrastive learning methods, RECLIP demonstrates 5 to 59$\times$ training resource savings while maintaining highly competitive zero-shot classification and retrieval performance. We hope this work will pave the path for the broader research community to explore language supervised pretraining in more resource-friendly settings.
MonoIndoor++:Towards Better Practice of Self-Supervised Monocular Depth Estimation for Indoor Environments
Jul 18, 2022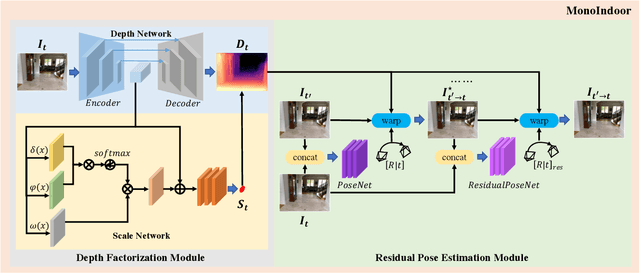
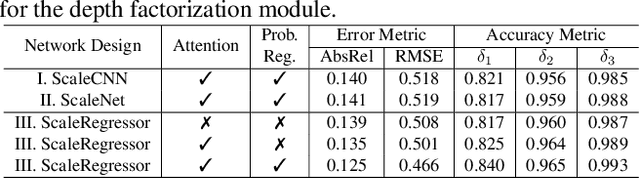
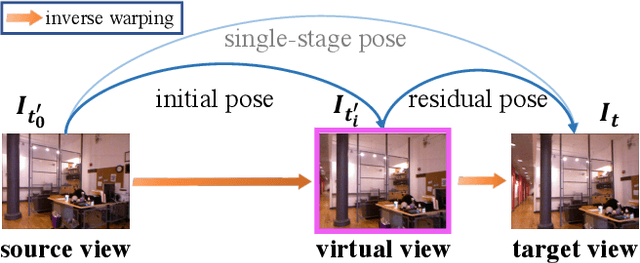
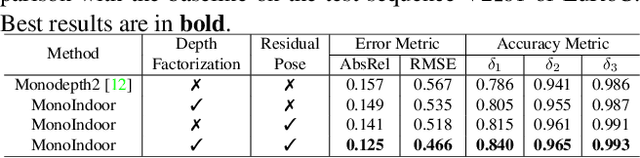
Self-supervised monocular depth estimation has seen significant progress in recent years, especially in outdoor environments. However, depth prediction results are not satisfying in indoor scenes where most of the existing data are captured with hand-held devices. As compared to outdoor environments, estimating depth of monocular videos for indoor environments, using self-supervised methods, results in two additional challenges: (i) the depth range of indoor video sequences varies a lot across different frames, making it difficult for the depth network to induce consistent depth cues for training; (ii) the indoor sequences recorded with handheld devices often contain much more rotational motions, which cause difficulties for the pose network to predict accurate relative camera poses. In this work, we propose a novel framework-MonoIndoor++ by giving special considerations to those challenges and consolidating a set of good practices for improving the performance of self-supervised monocular depth estimation for indoor environments. First, a depth factorization module with transformer-based scale regression network is proposed to estimate a global depth scale factor explicitly, and the predicted scale factor can indicate the maximum depth values. Second, rather than using a single-stage pose estimation strategy as in previous methods, we propose to utilize a residual pose estimation module to estimate relative camera poses across consecutive frames iteratively. Third, to incorporate extensive coordinates guidance for our residual pose estimation module, we propose to perform coordinate convolutional encoding directly over the inputs to pose networks. The proposed method is validated on a variety of benchmark indoor datasets, i.e., EuRoC MAV, NYUv2, ScanNet and 7-Scenes, demonstrating the state-of-the-art performance.
Dite-HRNet: Dynamic Lightweight High-Resolution Network for Human Pose Estimation
Apr 22, 2022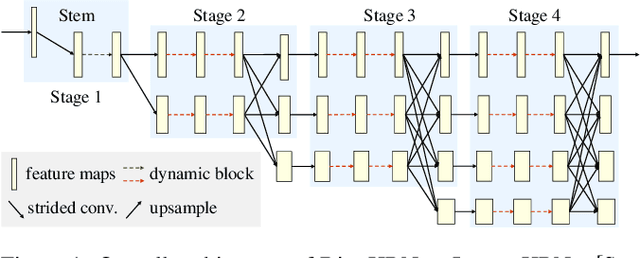
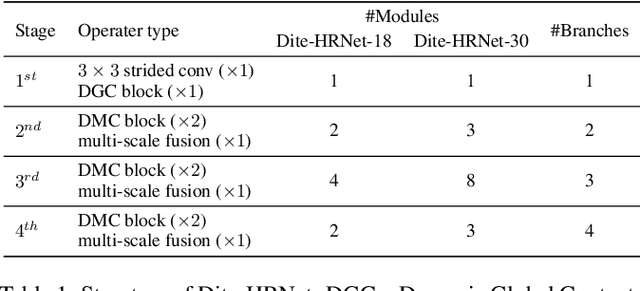
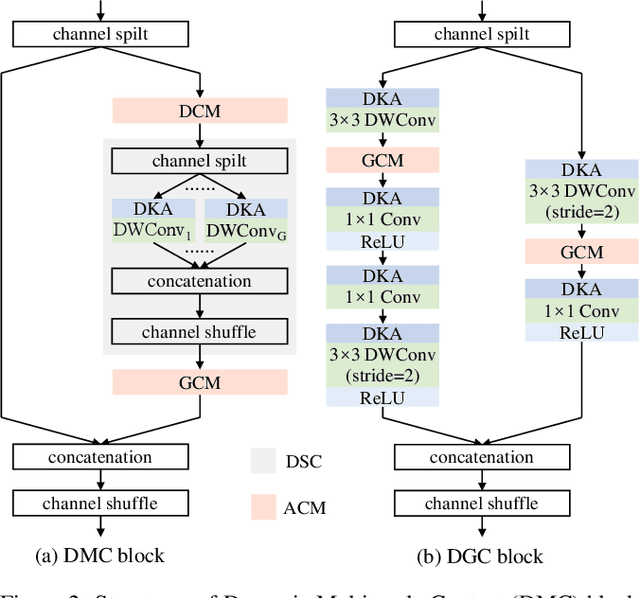
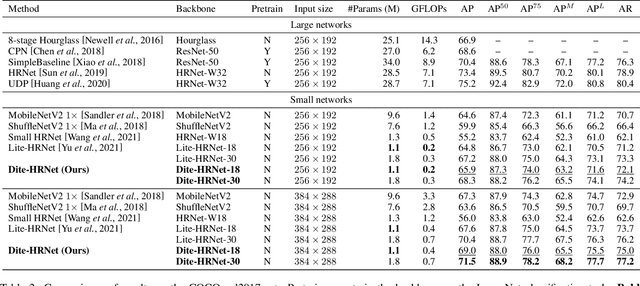
A high-resolution network exhibits remarkable capability in extracting multi-scale features for human pose estimation, but fails to capture long-range interactions between joints and has high computational complexity. To address these problems, we present a Dynamic lightweight High-Resolution Network (Dite-HRNet), which can efficiently extract multi-scale contextual information and model long-range spatial dependency for human pose estimation. Specifically, we propose two methods, dynamic split convolution and adaptive context modeling, and embed them into two novel lightweight blocks, which are named dynamic multi-scale context block and dynamic global context block. These two blocks, as the basic component units of our Dite-HRNet, are specially designed for the high-resolution networks to make full use of the parallel multi-resolution architecture. Experimental results show that the proposed network achieves superior performance on both COCO and MPII human pose estimation datasets, surpassing the state-of-the-art lightweight networks. Code is available at: \url{https://github.com/ZiyiZhang27/Dite-HRNet}.
Transferring Knowledge with Attention Distillation for Multi-Domain Image-to-Image Translation
Aug 17, 2021



Gradient-based attention modeling has been used widely as a way to visualize and understand convolutional neural networks. However, exploiting these visual explanations during the training of generative adversarial networks (GANs) is an unexplored area in computer vision research. Indeed, we argue that this kind of information can be used to influence GANs training in a positive way. For this reason, in this paper, it is shown how gradient based attentions can be used as knowledge to be conveyed in a teacher-student paradigm for multi-domain image-to-image translation tasks in order to improve the results of the student architecture. Further, it is demonstrated how "pseudo"-attentions can also be employed during training when teacher and student networks are trained on different domains which share some similarities. The approach is validated on multi-domain facial attributes transfer and human expression synthesis showing both qualitative and quantitative results.
Ada-VSR: Adaptive Video Super-Resolution with Meta-Learning
Aug 05, 2021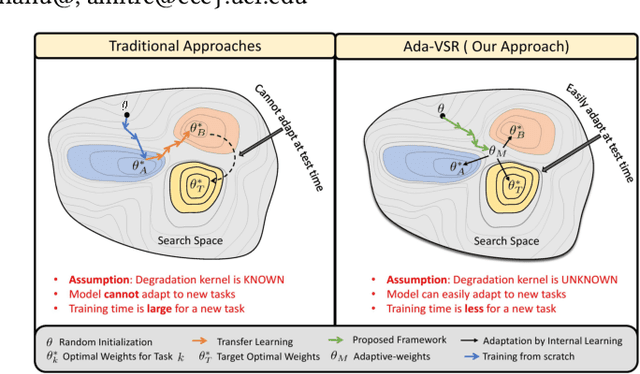
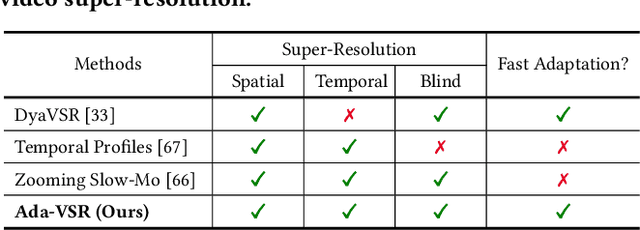
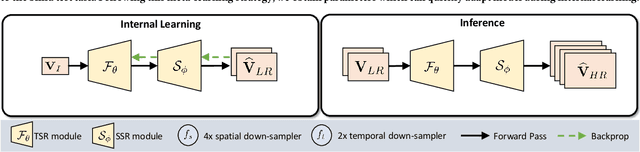
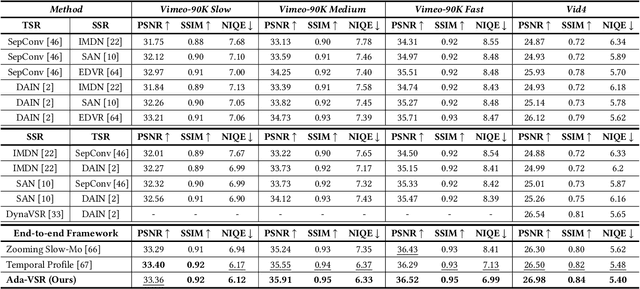
Most of the existing works in supervised spatio-temporal video super-resolution (STVSR) heavily rely on a large-scale external dataset consisting of paired low-resolution low-frame rate (LR-LFR)and high-resolution high-frame-rate (HR-HFR) videos. Despite their remarkable performance, these methods make a prior assumption that the low-resolution video is obtained by down-scaling the high-resolution video using a known degradation kernel, which does not hold in practical settings. Another problem with these methods is that they cannot exploit instance-specific internal information of video at testing time. Recently, deep internal learning approaches have gained attention due to their ability to utilize the instance-specific statistics of a video. However, these methods have a large inference time as they require thousands of gradient updates to learn the intrinsic structure of the data. In this work, we presentAdaptiveVideoSuper-Resolution (Ada-VSR) which leverages external, as well as internal, information through meta-transfer learning and internal learning, respectively. Specifically, meta-learning is employed to obtain adaptive parameters, using a large-scale external dataset, that can adapt quickly to the novel condition (degradation model) of the given test video during the internal learning task, thereby exploiting external and internal information of a video for super-resolution. The model trained using our approach can quickly adapt to a specific video condition with only a few gradient updates, which reduces the inference time significantly. Extensive experiments on standard datasets demonstrate that our method performs favorably against various state-of-the-art approaches.
MonoIndoor: Towards Good Practice of Self-Supervised Monocular Depth Estimation for Indoor Environments
Jul 28, 2021Self-supervised depth estimation for indoor environments is more challenging than its outdoor counterpart in at least the following two aspects: (i) the depth range of indoor sequences varies a lot across different frames, making it difficult for the depth network to induce consistent depth cues, whereas the maximum distance in outdoor scenes mostly stays the same as the camera usually sees the sky; (ii) the indoor sequences contain much more rotational motions, which cause difficulties for the pose network, while the motions of outdoor sequences are pre-dominantly translational, especially for driving datasets such as KITTI. In this paper, special considerations are given to those challenges and a set of good practices are consolidated for improving the performance of self-supervised monocular depth estimation in indoor environments. The proposed method mainly consists of two novel modules, \ie, a depth factorization module and a residual pose estimation module, each of which is designed to respectively tackle the aforementioned challenges. The effectiveness of each module is shown through a carefully conducted ablation study and the demonstration of the state-of-the-art performance on three indoor datasets, \ie, EuRoC, NYUv2, and 7-scenes.
Learning Local Recurrent Models for Human Mesh Recovery
Jul 27, 2021



We consider the problem of estimating frame-level full human body meshes given a video of a person with natural motion dynamics. While much progress in this field has been in single image-based mesh estimation, there has been a recent uptick in efforts to infer mesh dynamics from video given its role in alleviating issues such as depth ambiguity and occlusions. However, a key limitation of existing work is the assumption that all the observed motion dynamics can be modeled using one dynamical/recurrent model. While this may work well in cases with relatively simplistic dynamics, inference with in-the-wild videos presents many challenges. In particular, it is typically the case that different body parts of a person undergo different dynamics in the video, e.g., legs may move in a way that may be dynamically different from hands (e.g., a person dancing). To address these issues, we present a new method for video mesh recovery that divides the human mesh into several local parts following the standard skeletal model. We then model the dynamics of each local part with separate recurrent models, with each model conditioned appropriately based on the known kinematic structure of the human body. This results in a structure-informed local recurrent learning architecture that can be trained in an end-to-end fashion with available annotations. We conduct a variety of experiments on standard video mesh recovery benchmark datasets such as Human3.6M, MPI-INF-3DHP, and 3DPW, demonstrating the efficacy of our design of modeling local dynamics as well as establishing state-of-the-art results based on standard evaluation metrics.
Fully Convolutional Scene Graph Generation
Mar 30, 2021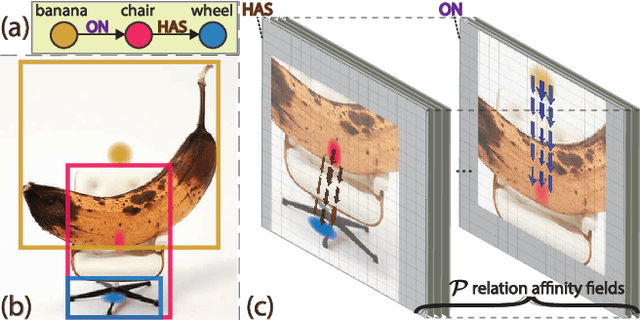
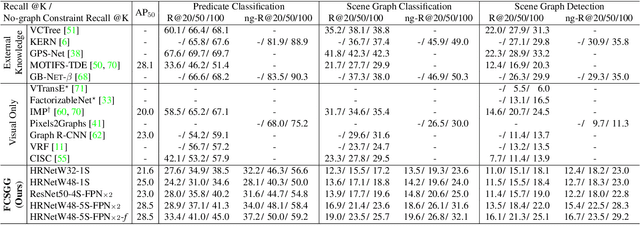
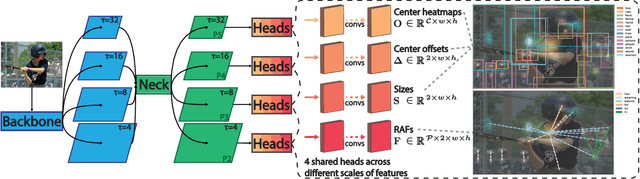
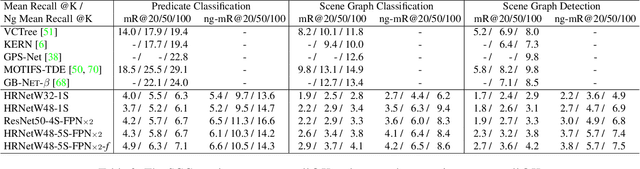
This paper presents a fully convolutional scene graph generation (FCSGG) model that detects objects and relations simultaneously. Most of the scene graph generation frameworks use a pre-trained two-stage object detector, like Faster R-CNN, and build scene graphs using bounding box features. Such pipeline usually has a large number of parameters and low inference speed. Unlike these approaches, FCSGG is a conceptually elegant and efficient bottom-up approach that encodes objects as bounding box center points, and relationships as 2D vector fields which are named as Relation Affinity Fields (RAFs). RAFs encode both semantic and spatial features, and explicitly represent the relationship between a pair of objects by the integral on a sub-region that points from subject to object. FCSGG only utilizes visual features and still generates strong results for scene graph generation. Comprehensive experiments on the Visual Genome dataset demonstrate the efficacy, efficiency, and generalizability of the proposed method. FCSGG achieves highly competitive results on recall and zero-shot recall with significantly reduced inference time.