 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Knowledge with Attention Distillation for Multi-Domain Image-to-Image Translation
Aug 17, 2021



Gradient-based attention modeling has been used widely as a way to visualize and understand convolutional neural networks. However, exploiting these visual explanations during the training of generative adversarial networks (GANs) is an unexplored area in computer vision research. Indeed, we argue that this kind of information can be used to influence GANs training in a positive way. For this reason, in this paper, it is shown how gradient based attentions can be used as knowledge to be conveyed in a teacher-student paradigm for multi-domain image-to-image translation tasks in order to improve the results of the student architecture. Further, it is demonstrated how "pseudo"-attentions can also be employed during training when teacher and student networks are trained on different domains which share some similarities. The approach is validated on multi-domain facial attributes transfer and human expression synthesis showing both qualitative and quantitative results.
MetalGAN: Multi-Domain Label-Less Image Synthesis Using cGANs and Meta-Learning
Dec 05, 2019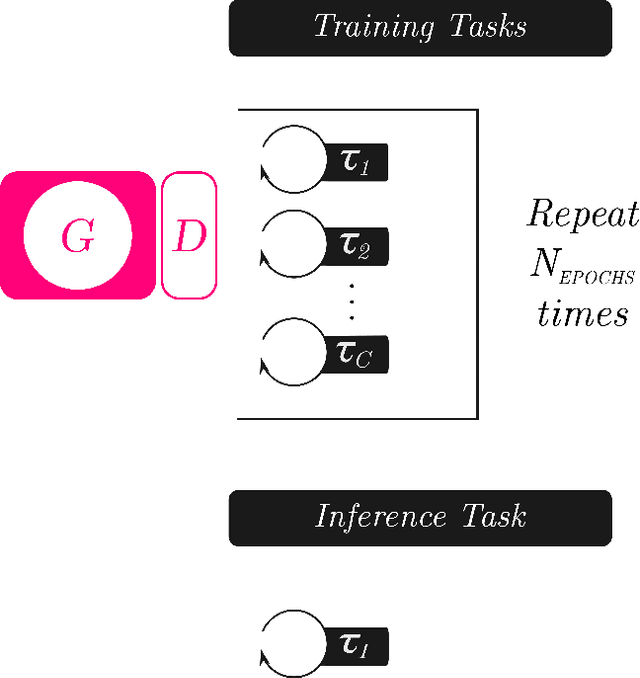
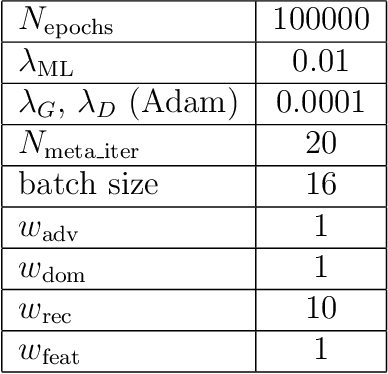
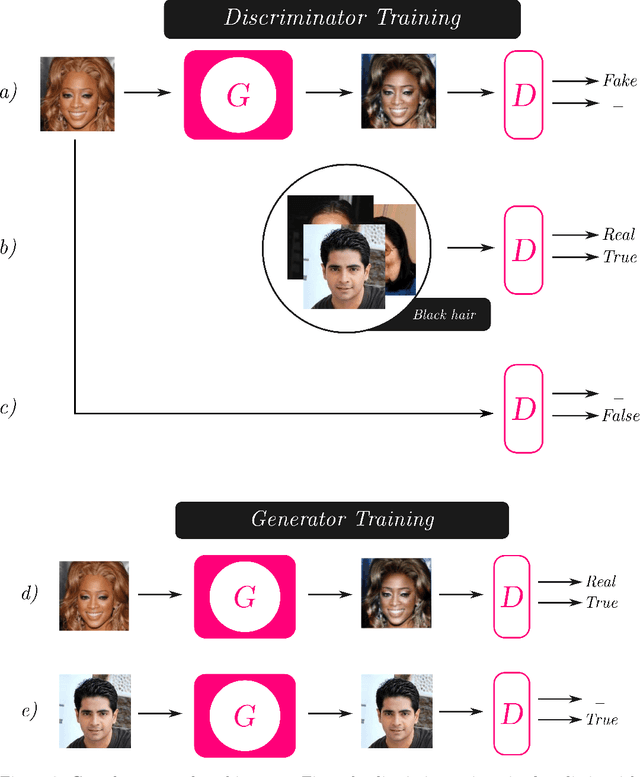
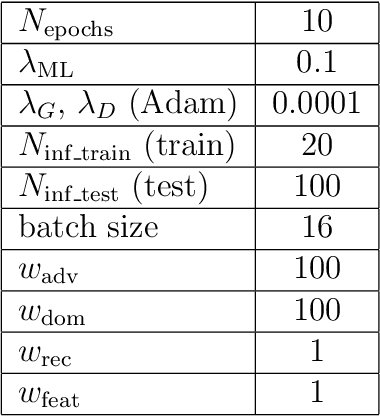
Image synthesis is currently one of the most addressed image processing topic in computer vision and deep learning fields of study. Researchers have tackled this problem focusing their efforts on its several challenging problems, e.g. image quality and size, domain and pose changing, architecture of the networks, and so on. Above all, producing images belonging to different domains by using a single architecture is a very relevant goal for image generation. In fact, a single multi-domain network would allow greater flexibility and robustness in the image synthesis task than other approaches. This paper proposes a novel architecture and a training algorithm, which are able to produce multi-domain outputs using a single network. A small portion of a dataset is intentionally used, and there are no hard-coded labels (or classes). This is achieved by combining a conditional Generative Adversarial Network (cGAN) for image generation and a Meta-Learning algorithm for domain switch, and we called our approach MetalGAN. The approach has proved to be appropriate for solving the multi-domain problem and it is validated on facial attribute transfer, using CelebA dataset.
A complete hand-drawn sketch vectorization framework
Feb 16, 2018



Vectorizing hand-drawn sketches is a challenging task, which is of paramount importance for creating CAD vectorized versions for the fashion and creative workflows. This paper proposes a complete framework that automatically transforms noisy and complex hand-drawn sketches with different stroke types in a precise, reliable and highly-simplified vectorized model. The proposed framework includes a novel line extraction algorithm based on a multi-resolution application of Pearson's cross correlation and a new unbiased thinning algorithm that can get rid of scribbles and variable-width strokes to obtain clean 1-pixel lines. Other contributions include variants of pruning, merging and edge linking procedures to post-process the obtained paths. Finally, a modification of the original Schneider's vectorization algorithm is designed to obtain fewer control points in the resulting Bezier splines. All the proposed steps of the framework have been extensively tested and compared with state-of-the-art algorithms, showing (both qualitatively and quantitatively) its outperformance.