 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheta-Resonance: A Single-Step Reinforcement Learning Method for Design Space Exploration
Nov 17, 2022Given an environment (e.g., a simulator) for evaluating samples in a specified design space and a set of weighted evaluation metrics -- one can use Theta-Resonance, a single-step Markov Decision Process (MDP), to train an intelligent agent producing progressively more optimal samples. In Theta-Resonance, a neural network consumes a constant input tensor and produces a policy as a set of conditional probability density functions (PDFs) for sampling each design dimension. We specialize existing policy gradient algorithms in deep reinforcement learning (D-RL) in order to use evaluation feedback (in terms of cost, penalty or reward) to update our policy network with robust algorithmic stability and minimal design evaluations. We study multiple neural architectures (for our policy network) within the context of a simple SoC design space and propose a method of constructing synthetic space exploration problems to compare and improve design space exploration (DSE) algorithms. Although we only present categorical design spaces, we also outline how to use Theta-Resonance in order to explore continuous and mixed continuous-discrete design spaces.
Fully Convolutional Scene Graph Generation
Mar 30, 2021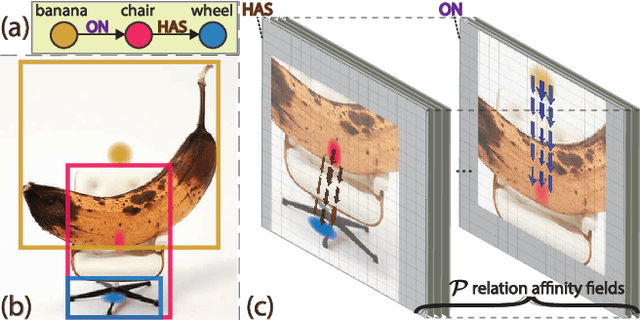
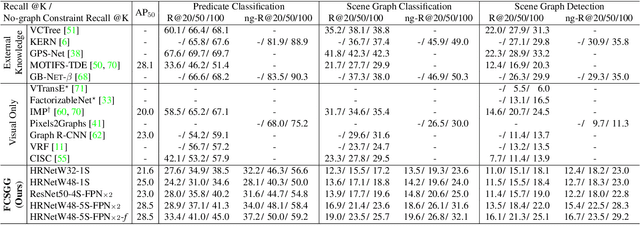
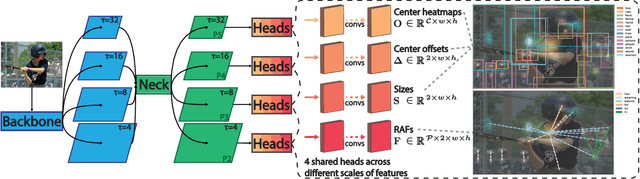
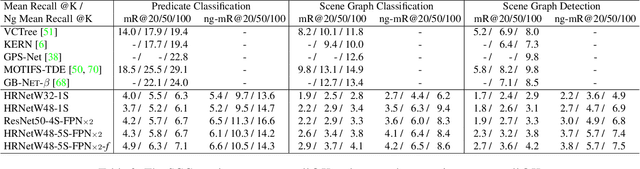
This paper presents a fully convolutional scene graph generation (FCSGG) model that detects objects and relations simultaneously. Most of the scene graph generation frameworks use a pre-trained two-stage object detector, like Faster R-CNN, and build scene graphs using bounding box features. Such pipeline usually has a large number of parameters and low inference speed. Unlike these approaches, FCSGG is a conceptually elegant and efficient bottom-up approach that encodes objects as bounding box center points, and relationships as 2D vector fields which are named as Relation Affinity Fields (RAFs). RAFs encode both semantic and spatial features, and explicitly represent the relationship between a pair of objects by the integral on a sub-region that points from subject to object. FCSGG only utilizes visual features and still generates strong results for scene graph generation. Comprehensive experiments on the Visual Genome dataset demonstrate the efficacy, efficiency, and generalizability of the proposed method. FCSGG achieves highly competitive results on recall and zero-shot recall with significantly reduced inference time.
Speech-Image Semantic Alignment Does Not Depend on Any Prior Classification Tasks
Oct 29, 2020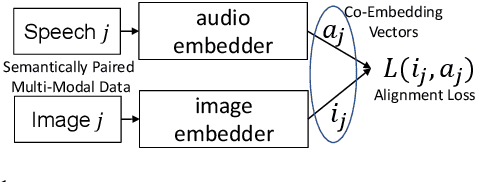
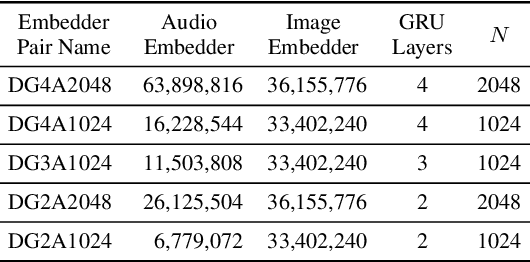


Semantically-aligned $(speech, image)$ datasets can be used to explore "visually-grounded speech". In a majority of existing investigations, features of an image signal are extracted using neural networks "pre-trained" on other tasks (e.g., classification on ImageNet). In still others, pre-trained networks are used to extract audio features prior to semantic embedding. Without "transfer learning" through pre-trained initialization or pre-trained feature extraction, previous results have tended to show low rates of recall in $speech \rightarrow image$ and $image \rightarrow speech$ queries. Choosing appropriate neural architectures for encoders in the speech and image branches and using large datasets, one can obtain competitive recall rates without any reliance on any pre-trained initialization or feature extraction: $(speech,image)$ semantic alignment and $speech \rightarrow image$ and $image \rightarrow speech$ retrieval are canonical tasks worthy of independent investigation of their own and allow one to explore other questions---e.g., the size of the audio embedder can be reduced significantly with little loss of recall rates in $speech \rightarrow image$ and $image \rightarrow speech$ queries.
The Impact of Hole Geometry on Relative Robustness of In-Painting Networks: An Empirical Study
Mar 04, 2020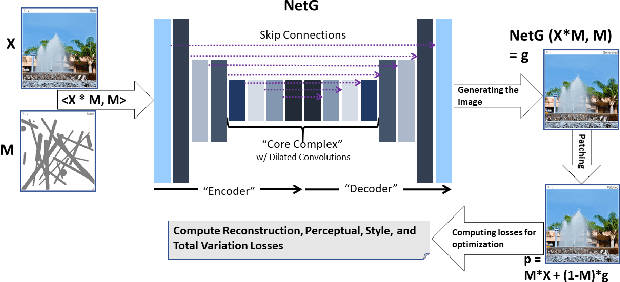


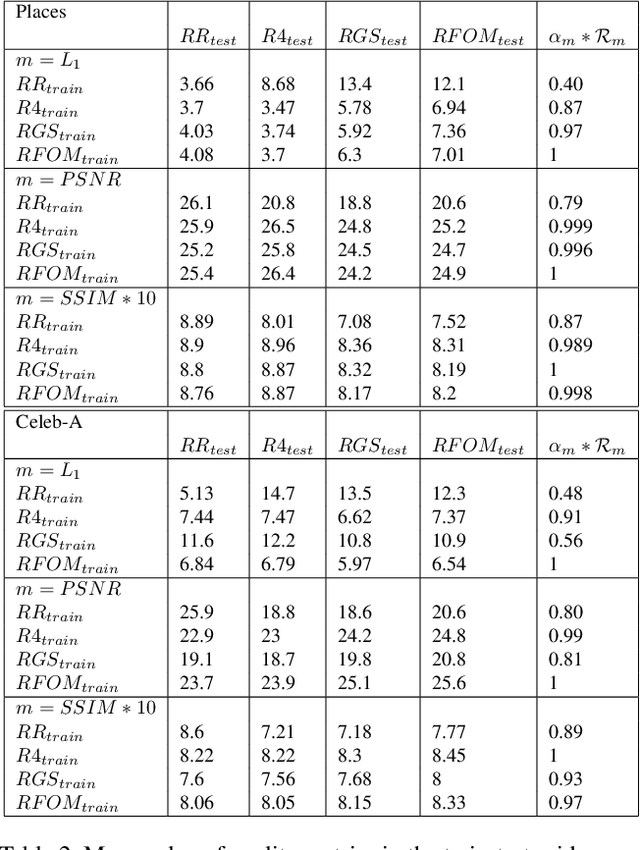
In-painting networks use existing pixels to generate appropriate pixels to fill "holes" placed on parts of an image. A 2-D in-painting network's input usually consists of (1) a three-channel 2-D image, and (2) an additional channel for the "holes" to be in-painted in that image. In this paper, we study the robustness of a given in-painting neural network against variations in hole geometry distributions. We observe that the robustness of an in-painting network is dependent on the probability distribution function (PDF) of the hole geometry presented to it during its training even if the underlying image dataset used (in training and testing) does not alter. We develop an experimental methodology for testing and evaluating relative robustness of in-painting networks against four different kinds of hole geometry PDFs. We examine a number of hypothesis regarding (1) the natural bias of in-painting networks to the hole distribution used for their training, (2) the underlying dataset's ability to differentiate relative robustness as hole distributions vary in a train-test (cross-comparison) grid, and (3) the impact of the directional distribution of edges in the holes and in the image dataset. We present results for L1, PSNR and SSIM quality metrics and develop a specific measure of relative in-painting robustness to be used in cross-comparison grids based on these quality metrics. (One can incorporate other quality metrics in this relative measure.) The empirical work reported here is an initial step in a broader and deeper investigation of "filling the blank" neural networks' sensitivity, robustness and regularization with respect to hole "geometry" PDFs, and it suggests further research in this domain.