 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Image Semantic Alignment Does Not Depend on Any Prior Classification Tasks
Paper and Code
Oct 29, 2020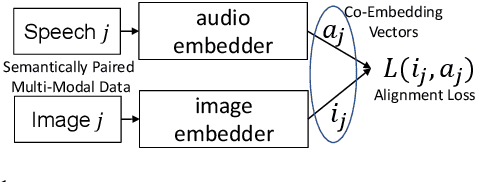
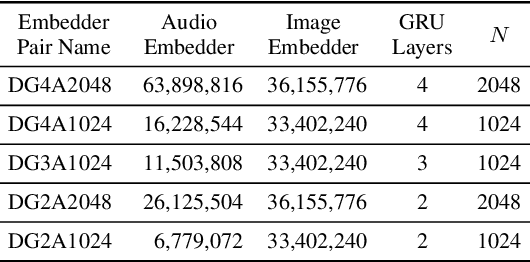


Semantically-aligned $(speech, image)$ datasets can be used to explore "visually-grounded speech". In a majority of existing investigations, features of an image signal are extracted using neural networks "pre-trained" on other tasks (e.g., classification on ImageNet). In still others, pre-trained networks are used to extract audio features prior to semantic embedding. Without "transfer learning" through pre-trained initialization or pre-trained feature extraction, previous results have tended to show low rates of recall in $speech \rightarrow image$ and $image \rightarrow speech$ queries. Choosing appropriate neural architectures for encoders in the speech and image branches and using large datasets, one can obtain competitive recall rates without any reliance on any pre-trained initialization or feature extraction: $(speech,image)$ semantic alignment and $speech \rightarrow image$ and $image \rightarrow speech$ retrieval are canonical tasks worthy of independent investigation of their own and allow one to explore other questions---e.g., the size of the audio embedder can be reduced significantly with little loss of recall rates in $speech \rightarrow image$ and $image \rightarrow speech$ queries.