 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Convolutional Scene Graph Generation
Paper and Code
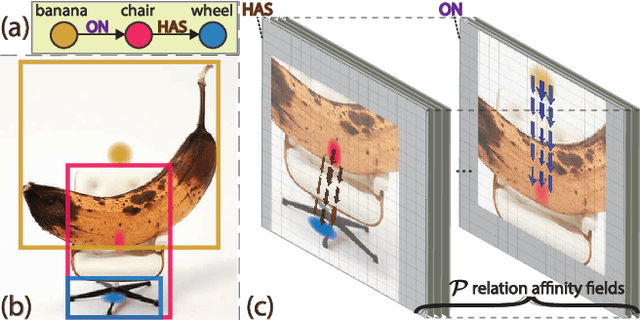
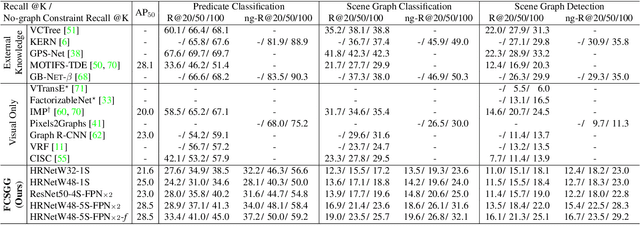
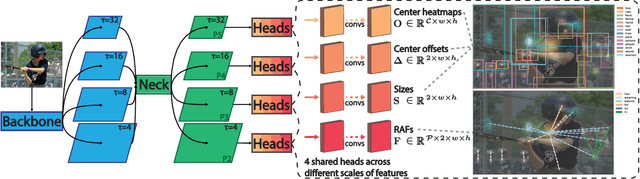
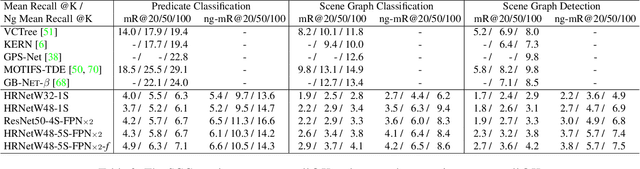
This paper presents a fully convolutional scene graph generation (FCSGG) model that detects objects and relations simultaneously. Most of the scene graph generation frameworks use a pre-trained two-stage object detector, like Faster R-CNN, and build scene graphs using bounding box features. Such pipeline usually has a large number of parameters and low inference speed. Unlike these approaches, FCSGG is a conceptually elegant and efficient bottom-up approach that encodes objects as bounding box center points, and relationships as 2D vector fields which are named as Relation Affinity Fields (RAFs). RAFs encode both semantic and spatial features, and explicitly represent the relationship between a pair of objects by the integral on a sub-region that points from subject to object. FCSGG only utilizes visual features and still generates strong results for scene graph generation. Comprehensive experiments on the Visual Genome dataset demonstrate the efficacy, efficiency, and generalizability of the proposed method. FCSGG achieves highly competitive results on recall and zero-shot recall with significantly reduced inference time.