 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoIndoor: Towards Good Practice of Self-Supervised Monocular Depth Estimation for Indoor Environments
Paper and Code
Jul 28, 2021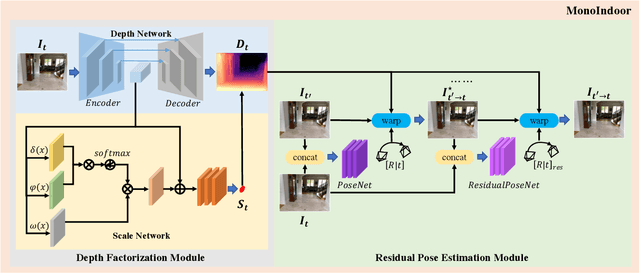
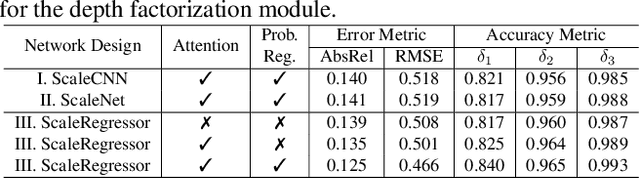
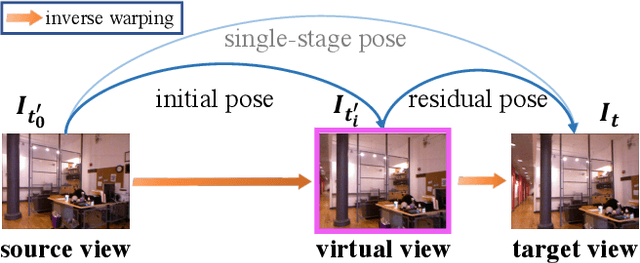
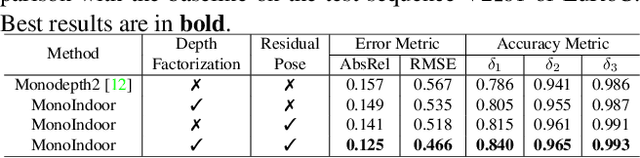
Self-supervised depth estimation for indoor environments is more challenging than its outdoor counterpart in at least the following two aspects: (i) the depth range of indoor sequences varies a lot across different frames, making it difficult for the depth network to induce consistent depth cues, whereas the maximum distance in outdoor scenes mostly stays the same as the camera usually sees the sky; (ii) the indoor sequences contain much more rotational motions, which cause difficulties for the pose network, while the motions of outdoor sequences are pre-dominantly translational, especially for driving datasets such as KITTI. In this paper, special considerations are given to those challenges and a set of good practices are consolidated for improving the performance of self-supervised monocular depth estimation in indoor environments. The proposed method mainly consists of two novel modules, \ie, a depth factorization module and a residual pose estimation module, each of which is designed to respectively tackle the aforementioned challenges. The effectiveness of each module is shown through a carefully conducted ablation study and the demonstration of the state-of-the-art performance on three indoor datasets, \ie, EuRoC, NYUv2, and 7-scenes.