 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDM-GRPO: Stable and Efficient Group Relative Policy Optimization for Uniform Discrete Diffusion Models
Apr 21, 2026Uniform Discrete Diffusion Model (UDM) has recently emerged as a promising paradigm for discrete generative modeling; however, its integration with reinforcement learning remains largely unexplored. We observe that naively applying GRPO to UDM leads to training instability and marginal performance gains. To address this, we propose UDM-GRPO, the first framework to integrate UDM with RL. Our method is guided by two key insights: (i) treating the final clean sample as the action provides more accurate and stable optimization signals; and (ii) reconstructing trajectories via the diffusion forward process better aligns probability paths with the pretraining distribution. Additionally, we introduce two strategies, Reduced-Step and CFG-Free, to further improve training efficiency. UDM-GRPO significantly improves base model performance across multiple T2I tasks. Notably, GenEval accuracy improves from $69\%$ to $96\%$ and PickScore increases from $20.46$ to $23.81$, achieving state-of-the-art performance in both continuous and discrete settings. On the OCR benchmark, accuracy rises from $8\%$ to $57\%$, further validating the generalization ability of our method. Code is available at https://github.com/Yovecent/UDM-GRPO.
3DrawAgent: Teaching LLM to Draw in 3D with Early Contrastive Experience
Apr 09, 2026Sketching in 3D space enables expressive reasoning about shape, structure, and spatial relationships, yet generating 3D sketches through natural language remains a major challenge. In this work, we introduce 3DrawAgent, a training-free, language-driven framework for 3D sketch generation that leverages large language models (LLMs) to sequentially draw 3D Bezier curves under geometric feedback. Unlike prior 2D sketch agents, our method introduces a relative experience optimization strategy that adapts the recently proposed Group Reward Policy Optimization (GRPO) paradigm. Instead of relying on explicit ground-truth supervision, we construct pairwise comparisons among generated sketches, with each pair consisting of a relatively better and a worse result based on CLIP-based perceptual rewards and LLM-based fine-grained qualitative assessment. These experiences are then used to iteratively refine the prior knowledge of 3D drawing, enabling black-box reinforcement of the model's 3D awareness. This design allows our model to self-improve its spatial understanding and drawing quality without parameter updates. Experiments show that 3DrawAgent can generate complex and coherent 3D Bezier sketches from diverse textual prompts, exhibit emergent geometric reasoning, and generalize to novel shapes, establishing a new paradigm for advancing the field of training-free 3D sketch intelligence.
FantasyVLN: Unified Multimodal Chain-of-Thought Reasoning for Vision-Language Navigation
Jan 20, 2026Achieving human-level performance in Vision-and-Language Navigation (VLN) requires an embodied agent to jointly understand multimodal instructions and visual-spatial context while reasoning over long action sequences. Recent works, such as NavCoT and NavGPT-2, demonstrate the potential of Chain-of-Thought (CoT) reasoning for improving interpretability and long-horizon planning. Moreover, multimodal extensions like OctoNav-R1 and CoT-VLA further validate CoT as a promising pathway toward human-like navigation reasoning. However, existing approaches face critical drawbacks: purely textual CoTs lack spatial grounding and easily overfit to sparse annotated reasoning steps, while multimodal CoTs incur severe token inflation by generating imagined visual observations, making real-time navigation impractical. In this work, we propose FantasyVLN, a unified implicit reasoning framework that preserves the benefits of CoT reasoning without explicit token overhead. Specifically, imagined visual tokens are encoded into a compact latent space using a pretrained Visual AutoRegressor (VAR) during CoT reasoning training, and the model jointly learns from textual, visual, and multimodal CoT modes under a unified multi-CoT strategy. At inference, our model performs direct instruction-to-action mapping while still enjoying reasoning-aware representations. Extensive experiments on LH-VLN show that our approach achieves reasoning-aware yet real-time navigation, improving success rates and efficiency while reducing inference latency by an order of magnitude compared to explicit CoT methods.
FantasyPortrait: Enhancing Multi-Character Portrait Animation with Expression-Augmented Diffusion Transformers
Jul 17, 2025Producing expressive facial animations from static images is a challenging task. Prior methods relying on explicit geometric priors (e.g., facial landmarks or 3DMM) often suffer from artifacts in cross reenactment and struggle to capture subtle emotions. Furthermore, existing approaches lack support for multi-character animation, as driving features from different individuals frequently interfere with one another, complicating the task. To address these challenges, we propose FantasyPortrait, a diffusion transformer based framework capable of generating high-fidelity and emotion-rich animations for both single- and multi-character scenarios. Our method introduces an expression-augmented learning strategy that utilizes implicit representations to capture identity-agnostic facial dynamics, enhancing the model's ability to render fine-grained emotions. For multi-character control, we design a masked cross-attention mechanism that ensures independent yet coordinated expression generation, effectively preventing feature interference. To advance research in this area, we propose the Multi-Expr dataset and ExprBench, which are specifically designed datasets and benchmarks for training and evaluating multi-character portrait animations. Extensive experiments demonstrate that FantasyPortrait significantly outperforms state-of-the-art methods in both quantitative metrics and qualitative evaluations, excelling particularly in challenging cross reenactment and multi-character contexts. Our project page is https://fantasy-amap.github.io/fantasy-portrait/.
FantasyTalking: Realistic Talking Portrait Generation via Coherent Motion Synthesis
Apr 07, 2025Creating a realistic animatable avatar from a single static portrait remains challenging. Existing approaches often struggle to capture subtle facial expressions, the associated global body movements, and the dynamic background. To address these limitations, we propose a novel framework that leverages a pretrained video diffusion transformer model to generate high-fidelity, coherent talking portraits with controllable motion dynamics. At the core of our work is a dual-stage audio-visual alignment strategy. In the first stage, we employ a clip-level training scheme to establish coherent global motion by aligning audio-driven dynamics across the entire scene, including the reference portrait, contextual objects, and background. In the second stage, we refine lip movements at the frame level using a lip-tracing mask, ensuring precise synchronization with audio signals. To preserve identity without compromising motion flexibility, we replace the commonly used reference network with a facial-focused cross-attention module that effectively maintains facial consistency throughout the video. Furthermore, we integrate a motion intensity modulation module that explicitly controls expression and body motion intensity, enabling controllable manipulation of portrait movements beyond mere lip motion. Extensive experimental results show that our proposed approach achieves higher quality with better realism, coherence, motion intensity, and identity preservation. Ours project page: https://fantasy-amap.github.io/fantasy-talking/.
FantasyID: Face Knowledge Enhanced ID-Preserving Video Generation
Feb 19, 2025



Tuning-free approaches adapting large-scale pre-trained video diffusion models for identity-preserving text-to-video generation (IPT2V) have gained popularity recently due to their efficacy and scalability. However, significant challenges remain to achieve satisfied facial dynamics while keeping the identity unchanged. In this work, we present a novel tuning-free IPT2V framework by enhancing face knowledge of the pre-trained video model built on diffusion transformers (DiT), dubbed FantasyID. Essentially, 3D facial geometry prior is incorporated to ensure plausible facial structures during video synthesis. To prevent the model from learning copy-paste shortcuts that simply replicate reference face across frames, a multi-view face augmentation strategy is devised to capture diverse 2D facial appearance features, hence increasing the dynamics over the facial expressions and head poses. Additionally, after blending the 2D and 3D features as guidance, instead of naively employing cross-attention to inject guidance cues into DiT layers, a learnable layer-aware adaptive mechanism is employed to selectively inject the fused features into each individual DiT layers, facilitating balanced modeling of identity preservation and motion dynamics. Experimental results validate our model's superiority over the current tuning-free IPT2V methods.
Autoregressive Video Generation without Vector Quantization
Dec 18, 2024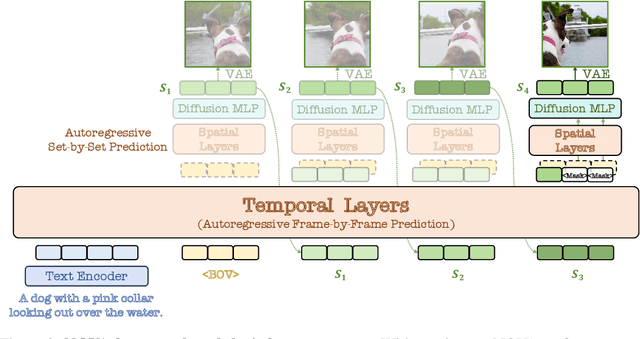
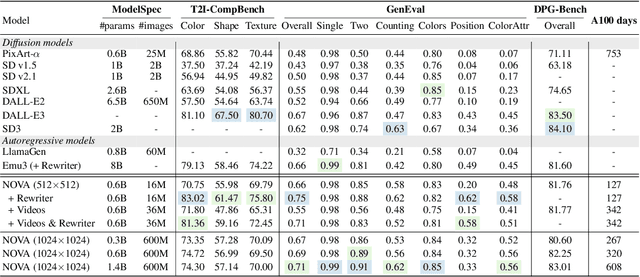
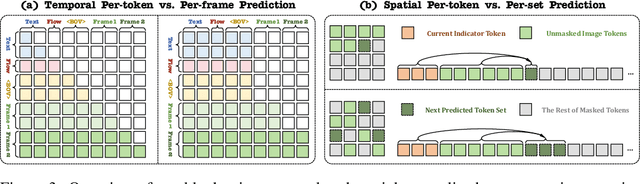
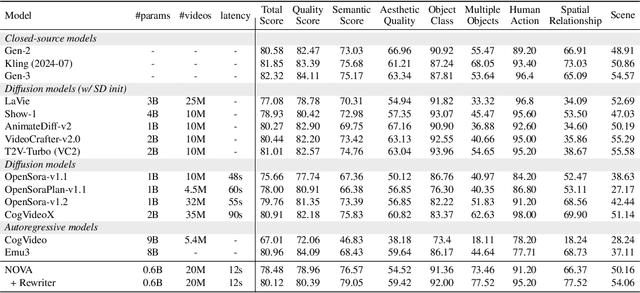
This paper presents a novel approach that enables autoregressive video generation with high efficiency. We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction. Unlike raster-scan prediction in prior autoregressive models or joint distribution modeling of fixed-length tokens in diffusion models, our approach maintains the causal property of GPT-style models for flexible in-context capabilities, while leveraging bidirectional modeling within individual frames for efficiency. With the proposed approach, we train a novel video autoregressive model without vector quantization, termed NOVA. Our results demonstrate that NOVA surpasses prior autoregressive video models in data efficiency, inference speed, visual fidelity, and video fluency, even with a much smaller model capacity, i.e., 0.6B parameters. NOVA also outperforms state-of-the-art image diffusion models in text-to-image generation tasks, with a significantly lower training cost. Additionally, NOVA generalizes well across extended video durations and enables diverse zero-shot applications in one unified model. Code and models are publicly available at https://github.com/baaivision/NOVA.
VersaGen: Unleashing Versatile Visual Control for Text-to-Image Synthesis
Dec 17, 2024



Despite the rapid advancements in text-to-image (T2I) synthesis, enabling precise visual control remains a significant challenge. Existing works attempted to incorporate multi-facet controls (text and sketch), aiming to enhance the creative control over generated images. However, our pilot study reveals that the expressive power of humans far surpasses the capabilities of current methods. Users desire a more versatile approach that can accommodate their diverse creative intents, ranging from controlling individual subjects to manipulating the entire scene composition. We present VersaGen, a generative AI agent that enables versatile visual control in T2I synthesis. VersaGen admits four types of visual controls: i) single visual subject; ii) multiple visual subjects; iii) scene background; iv) any combination of the three above or merely no control at all. We train an adaptor upon a frozen T2I model to accommodate the visual information into the text-dominated diffusion process. We introduce three optimization strategies during the inference phase of VersaGen to improve generation results and enhance user experience. Comprehensive experiments on COCO and Sketchy validate the effectiveness and flexibility of VersaGen, as evidenced by both qualitative and quantitative results.
SAUGE: Taming SAM for Uncertainty-Aligned Multi-Granularity Edge Detection
Dec 17, 2024Edge labels are typically at various granularity levels owing to the varying preferences of annotators, thus handling the subjectivity of per-pixel labels has been a focal point for edge detection. Previous methods often employ a simple voting strategy to diminish such label uncertainty or impose a strong assumption of labels with a pre-defined distribution, e.g., Gaussian. In this work, we unveil that the segment anything model (SAM) provides strong prior knowledge to model the uncertainty in edge labels. Our key insight is that the intermediate SAM features inherently correspond to object edges at various granularities, which reflects different edge options due to uncertainty. Therefore, we attempt to align uncertainty with granularity by regressing intermediate SAM features from different layers to object edges at multi-granularity levels. In doing so, the model can fully and explicitly explore diverse ``uncertainties'' in a data-driven fashion. Specifically, we inject a lightweight module (~ 1.5% additional parameters) into the frozen SAM to progressively fuse and adapt its intermediate features to estimate edges from coarse to fine. It is crucial to normalize the granularity level of human edge labels to match their innate uncertainty. For this, we simply perform linear blending to the real edge labels at hand to create pseudo labels with varying granularities. Consequently, our uncertainty-aligned edge detector can flexibly produce edges at any desired granularity (including an optimal one). Thanks to SAM, our model uniquely demonstrates strong generalizability for cross-dataset edge detection. Extensive experimental results on BSDS500, Muticue and NYUDv2 validate our model's superiority.
Symmetrical Joint Learning Support-query Prototypes for Few-shot Segmentation
Jul 27, 2024



We propose Sym-Net, a novel framework for Few-Shot Segmentation (FSS) that addresses the critical issue of intra-class variation by jointly learning both query and support prototypes in a symmetrical manner. Unlike previous methods that generate query prototypes solely by matching query features to support prototypes, which is a form of bias learning towards the few-shot support samples, Sym-Net leverages a balanced symmetrical learning approach for both query and support prototypes, ensuring that the learning process does not favor one set (support or query) over the other. One of main modules of Sym-Net is the visual-text alignment-based prototype aggregation module, which is not just query-guided prototype refinement, it is a jointly learning from both support and query samples, which makes the model beneficial for handling intra-class discrepancies and allows it to generalize better to new, unseen classes. Specifically, a parameter-free prior mask generation module is designed to accurately localize both local and global regions of the query object by using sliding windows of different sizes and a self-activation kernel to suppress incorrect background matches. Additionally, to address the information loss caused by spatial pooling during prototype learning, a top-down hyper-correlation module is integrated to capture multi-scale spatial relationships between support and query images. This approach is further jointly optimized by implementing a co-optimized hard triplet mining strategy. Experimental results show that the proposed Sym-Net outperforms state-of-the-art models, which demonstrates that jointly learning support-query prototypes in a symmetrical manner for FSS offers a promising direction to enhance segmentation performance with limited annotated data.