 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePQA: Perceptual Question Answering
Paper and Code
Apr 08, 2021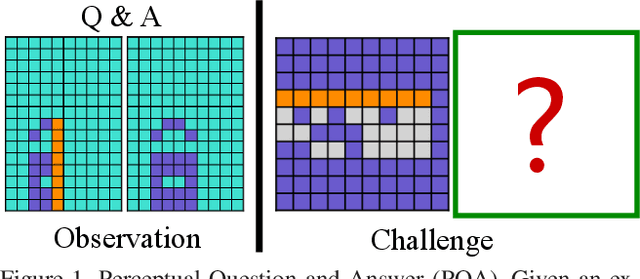



Perceptual organization remains one of the very few established theories on the human visual system. It underpinned many pre-deep seminal works on segmentation and detection, yet research has seen a rapid decline since the preferential shift to learning deep models. Of the limited attempts, most aimed at interpreting complex visual scenes using perceptual organizational rules. This has however been proven to be sub-optimal, since models were unable to effectively capture the visual complexity in real-world imagery. In this paper, we rejuvenate the study of perceptual organization, by advocating two positional changes: (i) we examine purposefully generated synthetic data, instead of complex real imagery, and (ii) we ask machines to synthesize novel perceptually-valid patterns, instead of explaining existing data. Our overall answer lies with the introduction of a novel visual challenge -- the challenge of perceptual question answering (PQA). Upon observing example perceptual question-answer pairs, the goal for PQA is to solve similar questions by generating answers entirely from scratch (see Figure 1). Our first contribution is therefore the first dataset of perceptual question-answer pairs, each generated specifically for a particular Gestalt principle. We then borrow insights from human psychology to design an agent that casts perceptual organization as a self-attention problem, where a proposed grid-to-grid mapping network directly generates answer patterns from scratch. Experiments show our agent to outperform a selection of naive and strong baselines. A human study however indicates that ours uses astronomically more data to learn when compared to an average human, necessitating future research (with or without our dataset).