 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Jan 04, 2024



3D panoptic segmentation is a challenging perception task, which aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing to novel categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not achieve good performance due to poor per-mask classification quality on novel categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms strong baselines by a large margin.
Superpixel Transformers for Efficient Semantic Segmentation
Oct 02, 2023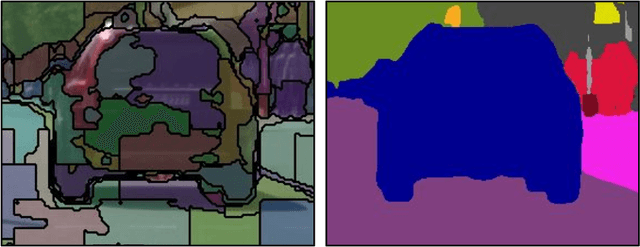
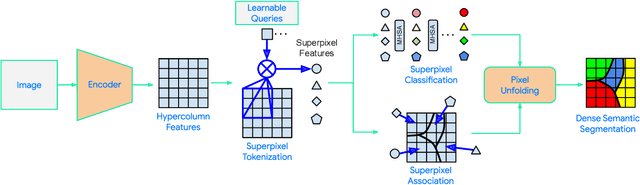


Semantic segmentation, which aims to classify every pixel in an image, is a key task in machine perception, with many applications across robotics and autonomous driving. Due to the high dimensionality of this task, most existing approaches use local operations, such as convolutions, to generate per-pixel features. However, these methods are typically unable to effectively leverage global context information due to the high computational costs of operating on a dense image. In this work, we propose a solution to this issue by leveraging the idea of superpixels, an over-segmentation of the image, and applying them with a modern transformer framework. In particular, our model learns to decompose the pixel space into a spatially low dimensional superpixel space via a series of local cross-attentions. We then apply multi-head self-attention to the superpixels to enrich the superpixel features with global context and then directly produce a class prediction for each superpixel. Finally, we directly project the superpixel class predictions back into the pixel space using the associations between the superpixels and the image pixel features. Reasoning in the superpixel space allows our method to be substantially more computationally efficient compared to convolution-based decoder methods. Yet, our method achieves state-of-the-art performance in semantic segmentation due to the rich superpixel features generated by the global self-attention mechanism. Our experiments on Cityscapes and ADE20K demonstrate that our method matches the state of the art in terms of accuracy, while outperforming in terms of model parameters and latency.
Instance Segmentation with Cross-Modal Consistency
Oct 14, 2022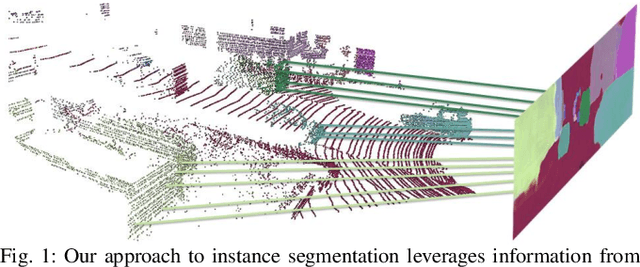
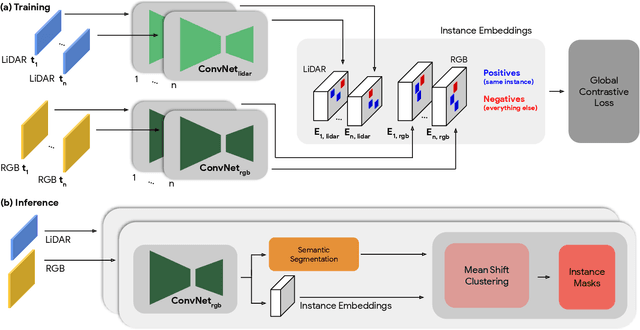

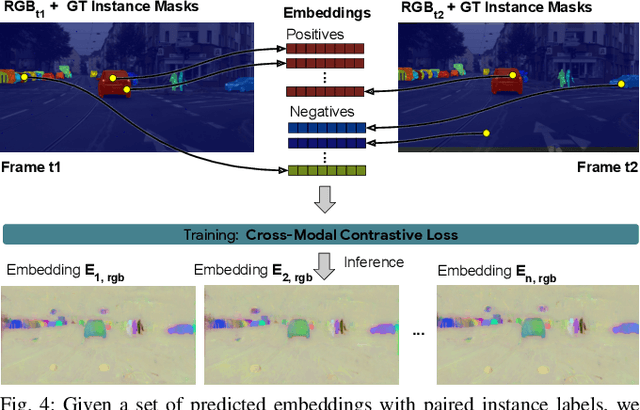
Segmenting object instances is a key task in machine perception, with safety-critical applications in robotics and autonomous driving. We introduce a novel approach to instance segmentation that jointly leverages measurements from multiple sensor modalities, such as cameras and LiDAR. Our method learns to predict embeddings for each pixel or point that give rise to a dense segmentation of the scene. Specifically, our technique applies contrastive learning to points in the scene both across sensor modalities and the temporal domain. We demonstrate that this formulation encourages the models to learn embeddings that are invariant to viewpoint variations and consistent across sensor modalities. We further demonstrate that the embeddings are stable over time as objects move around the scene. This not only provides stable instance masks, but can also provide valuable signals to downstream tasks, such as object tracking. We evaluate our method on the Cityscapes and KITTI-360 datasets. We further conduct a number of ablation studies, demonstrating benefits when applying additional inputs for the contrastive loss.
Waymo Open Dataset: Panoramic Video Panoptic Segmentation
Jun 15, 2022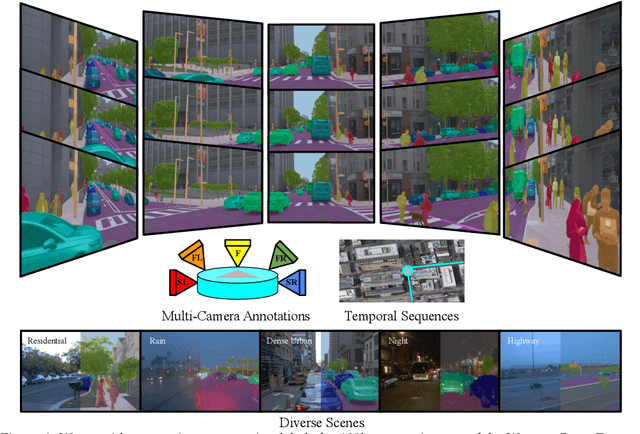

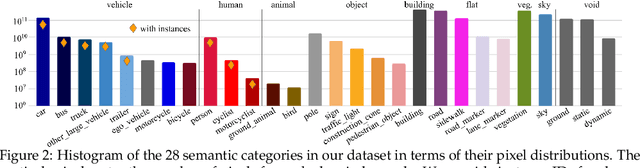
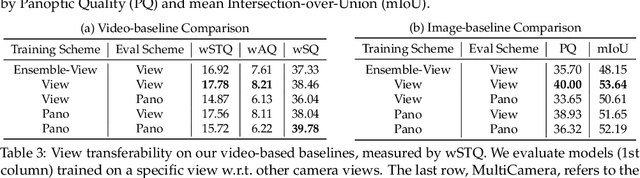
Panoptic image segmentation is the computer vision task of finding groups of pixels in an image and assigning semantic classes and object instance identifiers to them. Research in image segmentation has become increasingly popular due to its critical applications in robotics and autonomous driving. The research community thereby relies on publicly available benchmark dataset to advance the state-of-the-art in computer vision. Due to the high costs of densely labeling the images, however, there is a shortage of publicly available ground truth labels that are suitable for panoptic segmentation. The high labeling costs also make it challenging to extend existing datasets to the video domain and to multi-camera setups. We therefore present the Waymo Open Dataset: Panoramic Video Panoptic Segmentation Dataset, a large-scale dataset that offers high-quality panoptic segmentation labels for autonomous driving. We generate our dataset using the publicly available Waymo Open Dataset, leveraging the diverse set of camera images. Our labels are consistent over time for video processing and consistent across multiple cameras mounted on the vehicles for full panoramic scene understanding. Specifically, we offer labels for 28 semantic categories and 2,860 temporal sequences that were captured by five cameras mounted on autonomous vehicles driving in three different geographical locations, leading to a total of 100k labeled camera images. To the best of our knowledge, this makes our dataset an order of magnitude larger than existing datasets that offer video panoptic segmentation labels. We further propose a new benchmark for Panoramic Video Panoptic Segmentation and establish a number of strong baselines based on the DeepLab family of models. We will make the benchmark and the code publicly available. Find the dataset at https://waymo.com/open.
Spike-FlowNet: Event-based Optical Flow Estimation with Energy-Efficient Hybrid Neural Networks
Mar 14, 2020
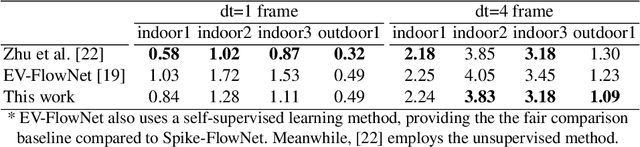

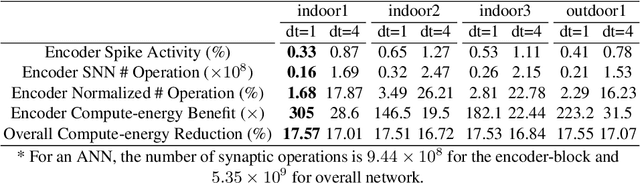
Event-based cameras display great potential for a variety of conditions such as high-speed motion detection and enabling navigation in low-light environments where conventional frame-based cameras suffer critically. This is attributed to their high temporal resolution, high dynamic range, and low-power consumption. However, conventional computer vision methods as well as deep Analog Neural Networks (ANNs) are not suited to work well with the asynchronous and discrete nature of event camera outputs. Spiking Neural Networks (SNNs) serve as ideal paradigms to handle event camera outputs, but deep SNNs suffer in terms of performance due to spike vanishing phenomenon. To overcome these issues, we present Spike-FlowNet, a deep hybrid neural network architecture integrating SNNs and ANNs for efficiently estimating optical flow from sparse event camera outputs without sacrificing the performance. The network is end-to-end trained with self-supervised learning on Multi-Vehicle Stereo Event Camera (MVSEC) dataset. Spike-FlowNet outperforms its corresponding ANN-based method in terms of the optical flow prediction capability while providing significant computational efficiency.
EventGAN: Leveraging Large Scale Image Datasets for Event Cameras
Dec 19, 2019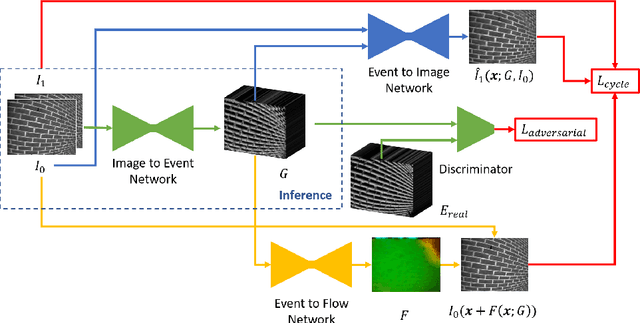



Event cameras provide a number of benefits over traditional cameras, such as the ability to track incredibly fast motions, high dynamic range, and low power consumption. However, their application into computer vision problems, many of which are primarily dominated by deep learning solutions, has been limited by the lack of labeled training data for events. In this work, we propose a method which leverages the existing labeled data for images by simulating events from a pair of temporal image frames, using a convolutional neural network. We train this network on pairs of images and events, using an adversarial discriminator loss and a pair of cycle consistency losses. The cycle consistency losses utilize a pair of pre-trained self-supervised networks which perform optical flow estimation and image reconstruction from events, and constrain our network to generate events which result in accurate outputs from both of these networks. Trained fully end to end, our network learns a generative model for events from images without the need for accurate modeling of the motion in the scene, exhibited by modeling based methods, while also implicitly modeling event noise. Using this simulator, we train a pair of downstream networks on object detection and 2D human pose estimation from events, using simulated data from large scale image datasets, and demonstrate the networks' abilities to generalize to datasets with real events.
Motion Equivariant Networks for Event Cameras with the Temporal Normalization Transform
Feb 18, 2019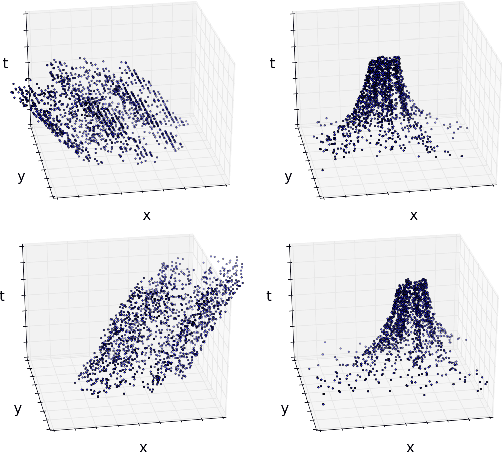
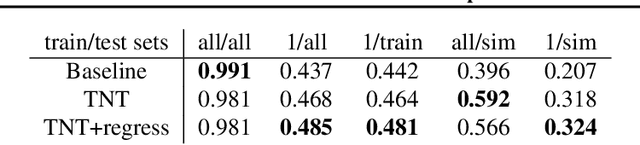
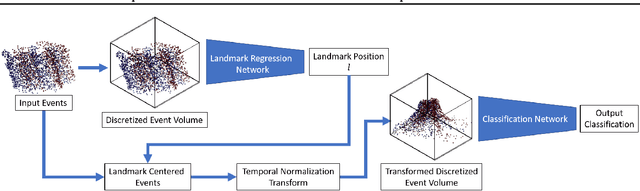
In this work, we propose a novel transformation for events from an event camera that is equivariant to optical flow under convolutions in the 3-D spatiotemporal domain. Events are generated by changes in the image, which are typically due to motion, either of the camera or the scene. As a result, different motions result in a different set of events. For learning based tasks based on a static scene such as classification which directly use the events, we must either rely on the learning method to learn the underlying object distinct from the motion, or to memorize all possible motions for each object with extensive data augmentation. Instead, we propose a novel transformation of the input event data which normalizes the $x$ and $y$ positions by the timestamp of each event. We show that this transformation generates a representation of the events that is equivariant to this motion when the optical flow is constant, allowing a deep neural network to learn the classification task without the need for expensive data augmentation. We test our method on the event based N-MNIST dataset, as well as a novel dataset N-MOVING-MNIST, with significantly more variety in motion compared to the standard N-MNIST dataset. In all sequences, we demonstrate that our transformed network is able to achieve similar or better performance compared to a network with a standard volumetric event input, and performs significantly better when the test set has a larger set of motions than seen at training.
Robustness Meets Deep Learning: An End-to-End Hybrid Pipeline for Unsupervised Learning of Egomotion
Dec 21, 2018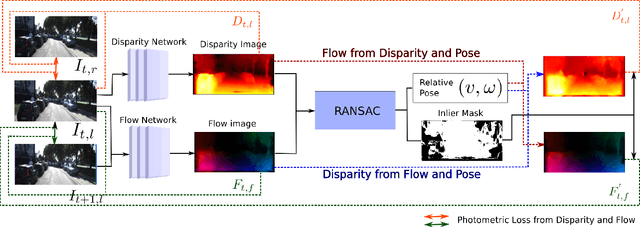

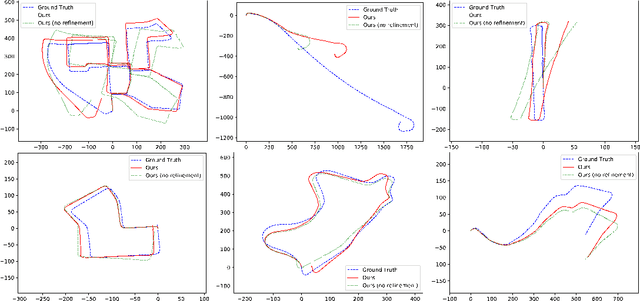

In this work, we propose a method that combines unsupervised deep learning predictions for optical flow and monocular disparity with a model based optimization procedure for camera pose. Given the flow and disparity predictions from the network, we apply a RANSAC outlier rejection scheme to find an inlier set of flows and disparities, which we use to solve for the camera pose in a least squares fashion. We show that this pipeline is fully differentiable, allowing us to combine the pose with the network outputs as an additional unsupervised training loss to further refine the predicted flows and disparities. This method not only allows us to directly regress pose from the network outputs, but also automatically segments away pixels that do not fit the rigid scene assumptions that many unsupervised structure from motion methods apply, such as on independently moving objects. We evaluate our method on the KITTI dataset, and demonstrate state of the art results, even in the presence of challenging independently moving objects.
Unsupervised Event-based Learning of Optical Flow, Depth, and Egomotion
Dec 19, 2018
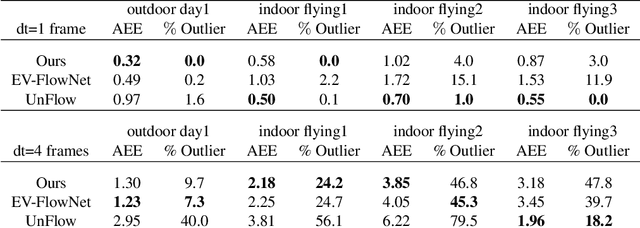
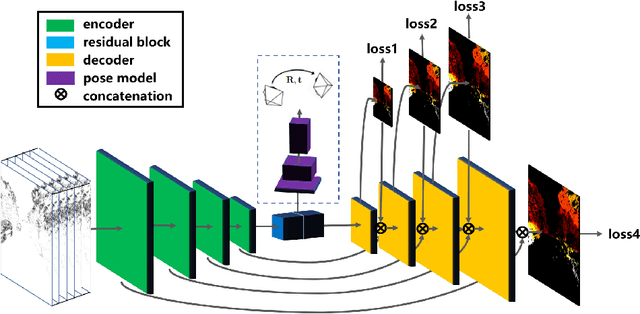
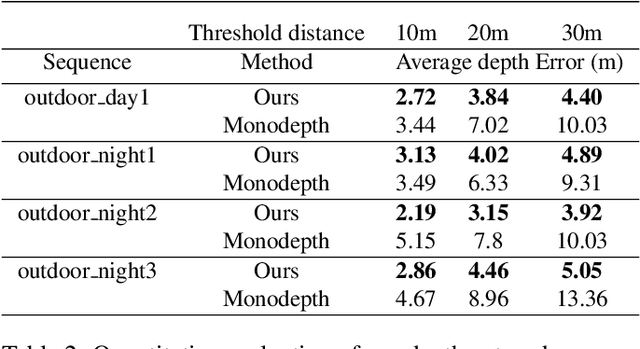
In this work, we propose a novel framework for unsupervised learning for event cameras that learns motion information from only the event stream. In particular, we propose an input representation of the events in the form of a discretized volume that maintains the temporal distribution of the events, which we pass through a neural network to predict the motion of the events. This motion is used to attempt to remove any motion blur in the event image. We then propose a loss function applied to the motion compensated event image that measures the motion blur in this image. We train two networks with this framework, one to predict optical flow, and one to predict egomotion and depths, and evaluate these networks on the Multi Vehicle Stereo Event Camera dataset, along with qualitative results from a variety of different scenes.
Realtime Time Synchronized Event-based Stereo
Oct 18, 2018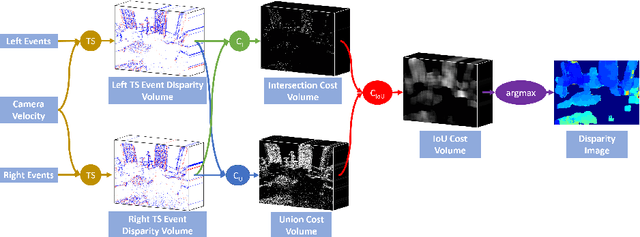
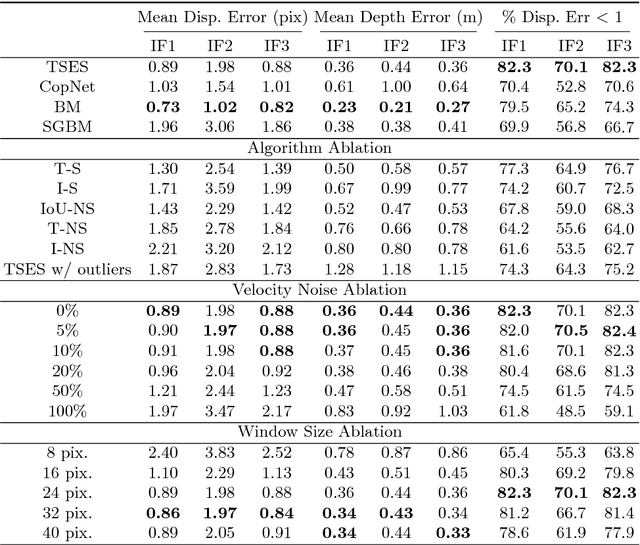

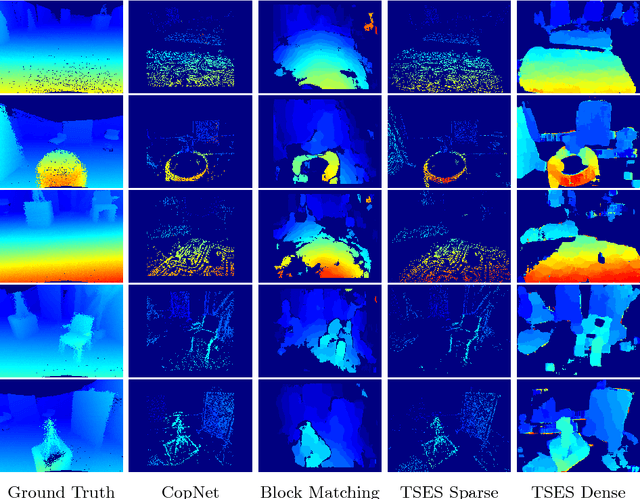
In this work, we propose a novel event based stereo method which addresses the problem of motion blur for a moving event camera. Our method uses the velocity of the camera and a range of disparities to synchronize the positions of the events, as if they were captured at a single point in time. We represent these events using a pair of novel time synchronized event disparity volumes, which we show remove motion blur for pixels at the correct disparity in the volume, while further blurring pixels at the wrong disparity. We then apply a novel matching cost over these time synchronized event disparity volumes, which both rewards similarity between the volumes while penalizing blurriness. We show that our method outperforms more expensive, smoothing based event stereo methods, by evaluating on the Multi Vehicle Stereo Event Camera dataset.
* 13 pages, 3 figures, 1 table. Video: https://youtu.be/4oa7e4hsrYo. Updated with final version with additional experiments