 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Equivariant Networks for Event Cameras with the Temporal Normalization Transform
Paper and Code
Feb 18, 2019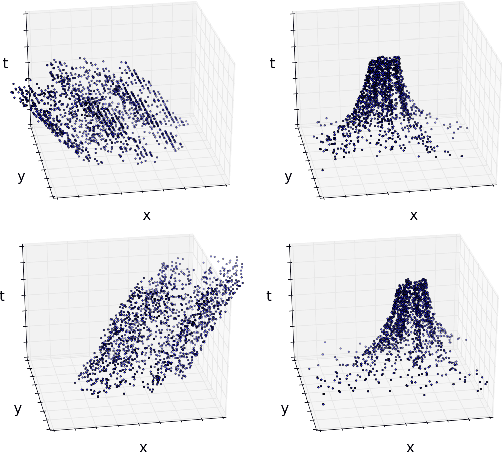
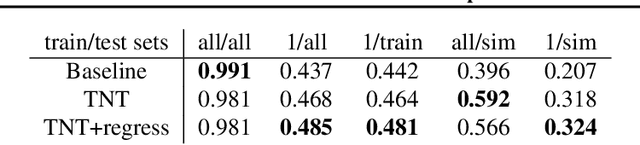
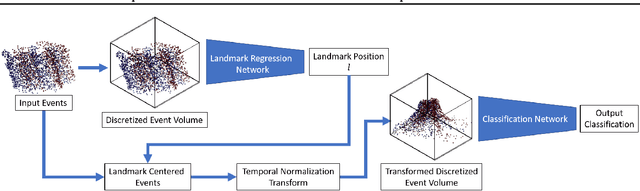
In this work, we propose a novel transformation for events from an event camera that is equivariant to optical flow under convolutions in the 3-D spatiotemporal domain. Events are generated by changes in the image, which are typically due to motion, either of the camera or the scene. As a result, different motions result in a different set of events. For learning based tasks based on a static scene such as classification which directly use the events, we must either rely on the learning method to learn the underlying object distinct from the motion, or to memorize all possible motions for each object with extensive data augmentation. Instead, we propose a novel transformation of the input event data which normalizes the $x$ and $y$ positions by the timestamp of each event. We show that this transformation generates a representation of the events that is equivariant to this motion when the optical flow is constant, allowing a deep neural network to learn the classification task without the need for expensive data augmentation. We test our method on the event based N-MNIST dataset, as well as a novel dataset N-MOVING-MNIST, with significantly more variety in motion compared to the standard N-MNIST dataset. In all sequences, we demonstrate that our transformed network is able to achieve similar or better performance compared to a network with a standard volumetric event input, and performs significantly better when the test set has a larger set of motions than seen at training.