 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Meets Deep Learning: An End-to-End Hybrid Pipeline for Unsupervised Learning of Egomotion
Paper and Code
Dec 21, 2018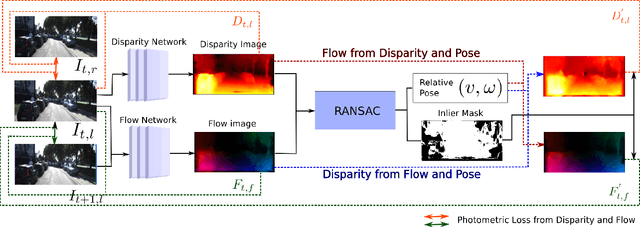

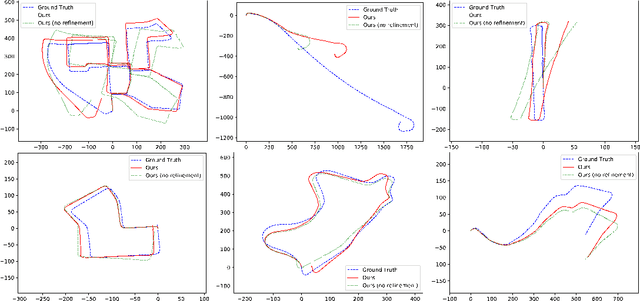

In this work, we propose a method that combines unsupervised deep learning predictions for optical flow and monocular disparity with a model based optimization procedure for camera pose. Given the flow and disparity predictions from the network, we apply a RANSAC outlier rejection scheme to find an inlier set of flows and disparities, which we use to solve for the camera pose in a least squares fashion. We show that this pipeline is fully differentiable, allowing us to combine the pose with the network outputs as an additional unsupervised training loss to further refine the predicted flows and disparities. This method not only allows us to directly regress pose from the network outputs, but also automatically segments away pixels that do not fit the rigid scene assumptions that many unsupervised structure from motion methods apply, such as on independently moving objects. We evaluate our method on the KITTI dataset, and demonstrate state of the art results, even in the presence of challenging independently moving objects.