 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Learning from a Physical World Model
Nov 10, 2025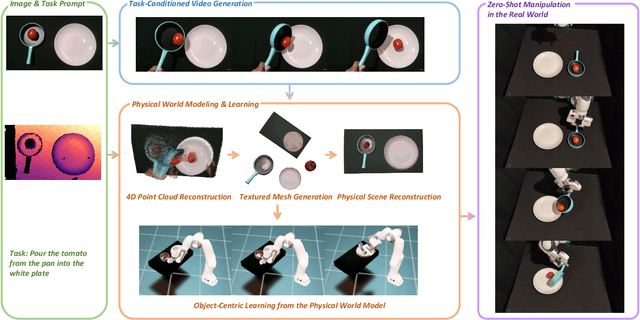

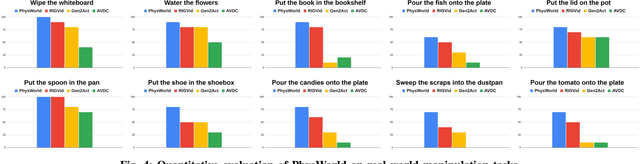

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
ParGANDA: Making Synthetic Pedestrians A Reality For Object Detection
Jul 21, 2023



Object detection is the key technique to a number of Computer Vision applications, but it often requires large amounts of annotated data to achieve decent results. Moreover, for pedestrian detection specifically, the collected data might contain some personally identifiable information (PII), which is highly restricted in many countries. This label intensive and privacy concerning task has recently led to an increasing interest in training the detection models using synthetically generated pedestrian datasets collected with a photo-realistic video game engine. The engine is able to generate unlimited amounts of data with precise and consistent annotations, which gives potential for significant gains in the real-world applications. However, the use of synthetic data for training introduces a synthetic-to-real domain shift aggravating the final performance. To close the gap between the real and synthetic data, we propose to use a Generative Adversarial Network (GAN), which performsparameterized unpaired image-to-image translation to generate more realistic images. The key benefit of using the GAN is its intrinsic preference of low-level changes to geometric ones, which means annotations of a given synthetic image remain accurate even after domain translation is performed thus eliminating the need for labeling real data. We extensively experimented with the proposed method using MOTSynth dataset to train and MOT17 and MOT20 detection datasets to test, with experimental results demonstrating the effectiveness of this method. Our approach not only produces visually plausible samples but also does not require any labels of the real domain thus making it applicable to the variety of downstream tasks.
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model
Jun 02, 2023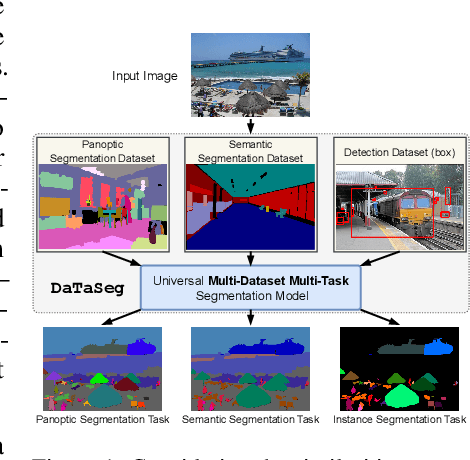
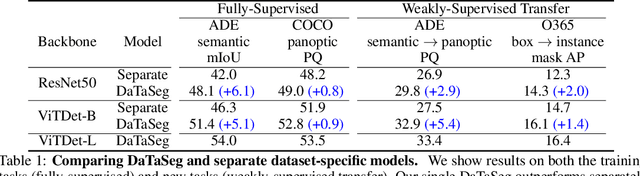
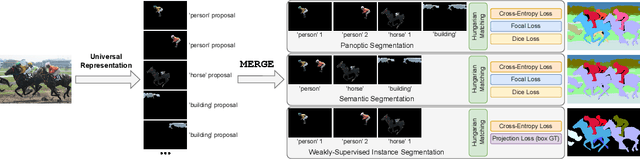
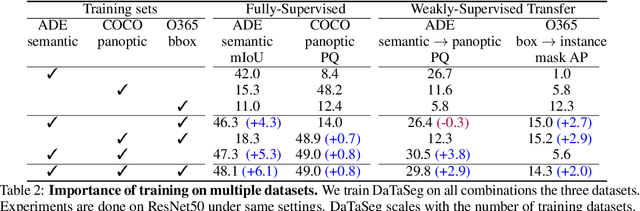
Observing the close relationship among panoptic, semantic and instance segmentation tasks, we propose to train a universal multi-dataset multi-task segmentation model: DaTaSeg.We use a shared representation (mask proposals with class predictions) for all tasks. To tackle task discrepancy, we adopt different merge operations and post-processing for different tasks. We also leverage weak-supervision, allowing our segmentation model to benefit from cheaper bounding box annotations. To share knowledge across datasets, we use text embeddings from the same semantic embedding space as classifiers and share all network parameters among datasets. We train DaTaSeg on ADE semantic, COCO panoptic, and Objects365 detection datasets. DaTaSeg improves performance on all datasets, especially small-scale datasets, achieving 54.0 mIoU on ADE semantic and 53.5 PQ on COCO panoptic. DaTaSeg also enables weakly-supervised knowledge transfer on ADE panoptic and Objects365 instance segmentation. Experiments show DaTaSeg scales with the number of training datasets and enables open-vocabulary segmentation through direct transfer. In addition, we annotate an Objects365 instance segmentation set of 1,000 images and will release it as a public benchmark.
Efficient Image Representation Learning with Federated Sampled Softmax
Mar 09, 2022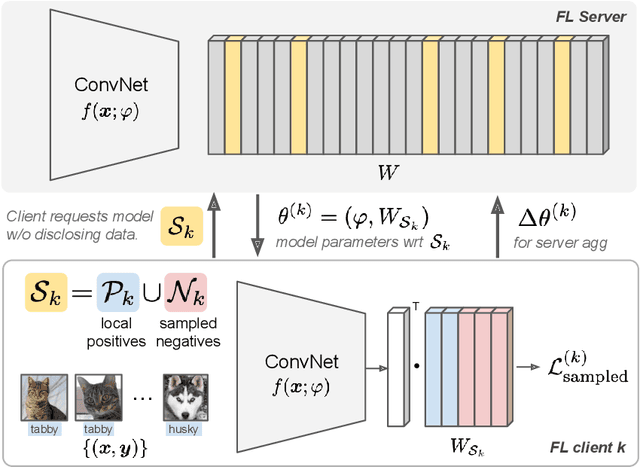
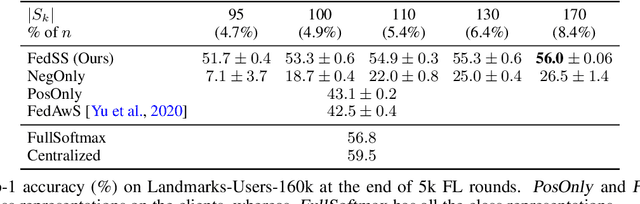
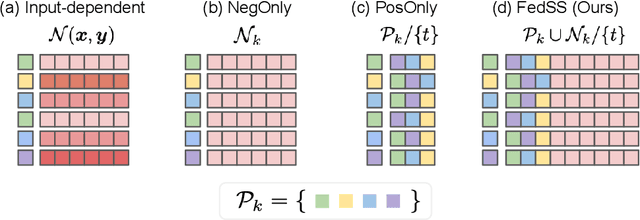
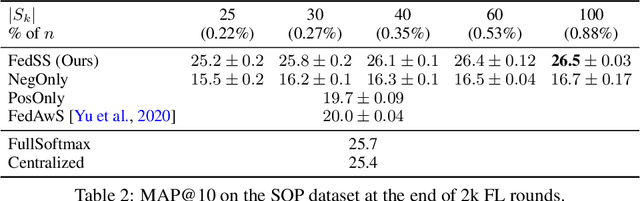
Learning image representations on decentralized data can bring many benefits in cases where data cannot be aggregated across data silos. Softmax cross entropy loss is highly effective and commonly used for learning image representations. Using a large number of classes has proven to be particularly beneficial for the descriptive power of such representations in centralized learning. However, doing so on decentralized data with Federated Learning is not straightforward as the demand on FL clients' computation and communication increases proportionally to the number of classes. In this work we introduce federated sampled softmax (FedSS), a resource-efficient approach for learning image representation with Federated Learning. Specifically, the FL clients sample a set of classes and optimize only the corresponding model parameters with respect to a sampled softmax objective that approximates the global full softmax objective. We examine the loss formulation and empirically show that our method significantly reduces the number of parameters transferred to and optimized by the client devices, while performing on par with the standard full softmax method. This work creates a possibility for efficiently learning image representations on decentralized data with a large number of classes under the federated setting.
A Simple Single-Scale Vision Transformer for Object Localization and Instance Segmentation
Dec 17, 2021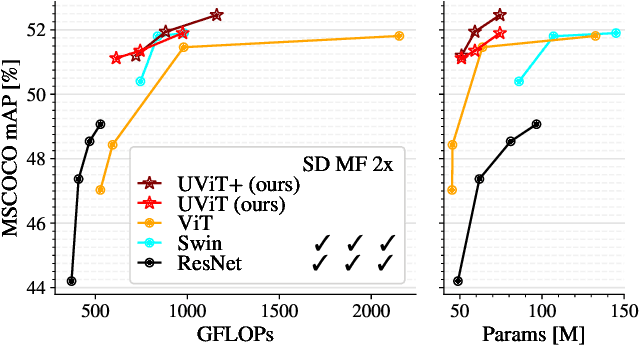

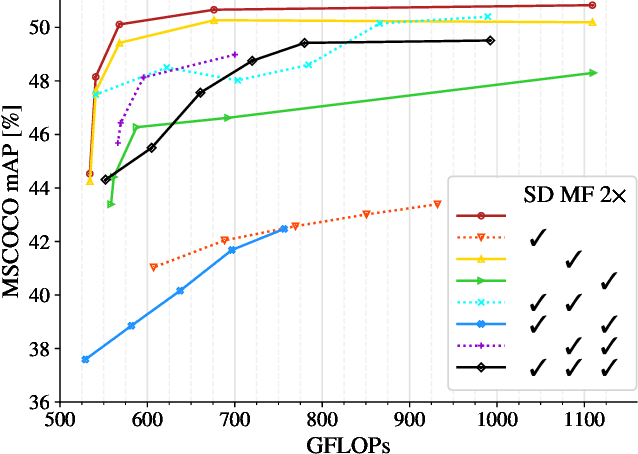

This work presents a simple vision transformer design as a strong baseline for object localization and instance segmentation tasks. Transformers recently demonstrate competitive performance in image classification tasks. To adopt ViT to object detection and dense prediction tasks, many works inherit the multistage design from convolutional networks and highly customized ViT architectures. Behind this design, the goal is to pursue a better trade-off between computational cost and effective aggregation of multiscale global contexts. However, existing works adopt the multistage architectural design as a black-box solution without a clear understanding of its true benefits. In this paper, we comprehensively study three architecture design choices on ViT -- spatial reduction, doubled channels, and multiscale features -- and demonstrate that a vanilla ViT architecture can fulfill this goal without handcrafting multiscale features, maintaining the original ViT design philosophy. We further complete a scaling rule to optimize our model's trade-off on accuracy and computation cost / model size. By leveraging a constant feature resolution and hidden size throughout the encoder blocks, we propose a simple and compact ViT architecture called Universal Vision Transformer (UViT) that achieves strong performance on COCO object detection and instance segmentation tasks.
Sky Optimization: Semantically aware image processing of skies in low-light photography
Jun 15, 2020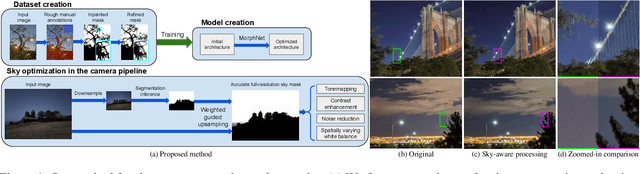

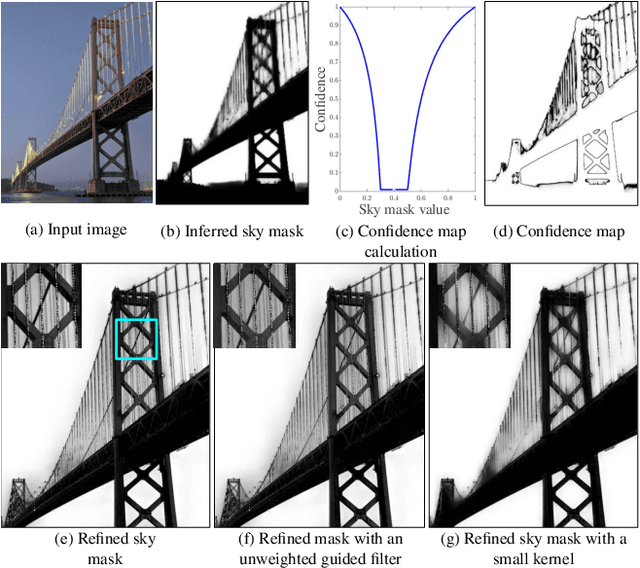
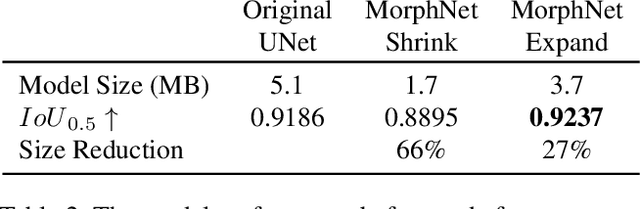
The sky is a major component of the appearance of a photograph, and its color and tone can strongly influence the mood of a picture. In nighttime photography, the sky can also suffer from noise and color artifacts. For this reason, there is a strong desire to process the sky in isolation from the rest of the scene to achieve an optimal look. In this work, we propose an automated method, which can run as a part of a camera pipeline, for creating accurate sky alpha-masks and using them to improve the appearance of the sky. Our method performs end-to-end sky optimization in less than half a second per image on a mobile device. We introduce a method for creating an accurate sky-mask dataset that is based on partially annotated images that are inpainted and refined by our modified weighted guided filter. We use this dataset to train a neural network for semantic sky segmentation. Due to the compute and power constraints of mobile devices, sky segmentation is performed at a low image resolution. Our modified weighted guided filter is used for edge-aware upsampling to resize the alpha-mask to a higher resolution. With this detailed mask we automatically apply post-processing steps to the sky in isolation, such as automatic spatially varying white-balance, brightness adjustments, contrast enhancement, and noise reduction.