 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluidGaussian: Propagating Simulation-Based Uncertainty Toward Functionally-Intelligent 3D Reconstruction
Mar 22, 2026Real objects that inhabit the physical world follow physical laws and thus behave plausibly during interaction with other physical objects. However, current methods that perform 3D reconstructions of real-world scenes from multi-view 2D images optimize primarily for visual fidelity, i.e., they train with photometric losses and reason about uncertainty in the image or representation space. This appearance-centric view overlooks body contacts and couplings, conflates function-critical regions (e.g., aerodynamic or hydrodynamic surfaces) with ornamentation, and reconstructs structures suboptimally, even when physical regularizers are added. All these can lead to unphysical and implausible interactions. To address this, we consider the question: How can 3D reconstruction become aware of real-world interactions and underlying object functionality, beyond visual cues? To answer this question, we propose FluidGaussian, a plug-and-play method that tightly couples geometry reconstruction with ubiquitous fluid-structure interactions to assess surface quality at high granularity. We define a simulation-based uncertainty metric induced by fluid simulations and integrate it with active learning to prioritize views that improve both visual and physical fidelity. In an empirical evaluation on NeRF Synthetic (Blender), Mip-NeRF 360, and DrivAerNet++, our FluidGaussian method yields up to +8.6% visual PSNR (Peak Signal-to-Noise Ratio) and -62.3% velocity divergence during fluid simulations. Our code is available at https://github.com/delta-lab-ai/FluidGaussian.
Silent Speech Interfaces in the Era of Large Language Models: A Comprehensive Taxonomy and Systematic Review
Mar 12, 2026Human-computer interaction has traditionally relied on the acoustic channel, a dependency that introduces systemic vulnerabilities to environmental noise, privacy constraints, and physiological speech impairments. Silent Speech Interfaces (SSIs) emerge as a transformative paradigm that bypasses the acoustic stage by decoding linguistic intent directly from the neuro-muscular-articulatory continuum. This review provides a high-level synthesis of the SSI landscape, transitioning from traditional transducer-centric analysis to a holistic intent-to-execution taxonomy. We systematically evaluate sensing modalities across four critical physiological interception points: neural oscillations, neuromuscular activation, articulatory kinematics (ultrasound/magnetometry), and pervasive active probing via acoustic or radio-frequency sensing. Critically, we analyze the current paradigm shift from heuristic signal processing to Latent Semantic Alignment. In this new era, Large Language Models (LLMs) and deep generative architectures serve as high-level linguistic priors to resolve the ``informational sparsity'' and non-stationarity of biosignals. By mapping fragmented physiological gestures into structured semantic latent spaces, modern SSI frameworks have, for the first time, approached the Word Error Rate usability threshold required for real-world deployment. We further examine the transition of SSIs from bulky laboratory instrumentation to ``invisible interfaces'' integrated into commodity-grade wearables, such as earables and smart glasses. Finally, we outline a strategic roadmap addressing the ``user-dependency paradox'' through self-supervised foundation models and define the ethical boundaries of ``neuro-security'' to protect cognitive liberty in an increasingly interfaced world.
Learning Data-Efficient and Generalizable Neural Operators via Fundamental Physics Knowledge
Feb 16, 2026Recent advances in scientific machine learning (SciML) have enabled neural operators (NOs) to serve as powerful surrogates for modeling the dynamic evolution of physical systems governed by partial differential equations (PDEs). While existing approaches focus primarily on learning simulations from the target PDE, they often overlook more fundamental physical principles underlying these equations. Inspired by how numerical solvers are compatible with simulations of different settings of PDEs, we propose a multiphysics training framework that jointly learns from both the original PDEs and their simplified basic forms. Our framework enhances data efficiency, reduces predictive errors, and improves out-of-distribution (OOD) generalization, particularly in scenarios involving shifts of physical parameters and synthetic-to-real transfer. Our method is architecture-agnostic and demonstrates consistent improvements in normalized root mean square error (nRMSE) across a wide range of 1D/2D/3D PDE problems. Through extensive experiments, we show that explicit incorporation of fundamental physics knowledge significantly strengthens the generalization ability of neural operators. We will release models and codes at https://sites.google.com/view/sciml-fundemental-pde.
Hybrid Neural-MPM for Interactive Fluid Simulations in Real-Time
May 25, 2025



We propose a neural physics system for real-time, interactive fluid simulations. Traditional physics-based methods, while accurate, are computationally intensive and suffer from latency issues. Recent machine-learning methods reduce computational costs while preserving fidelity; yet most still fail to satisfy the latency constraints for real-time use and lack support for interactive applications. To bridge this gap, we introduce a novel hybrid method that integrates numerical simulation, neural physics, and generative control. Our neural physics jointly pursues low-latency simulation and high physical fidelity by employing a fallback safeguard to classical numerical solvers. Furthermore, we develop a diffusion-based controller that is trained using a reverse modeling strategy to generate external dynamic force fields for fluid manipulation. Our system demonstrates robust performance across diverse 2D/3D scenarios, material types, and obstacle interactions, achieving real-time simulations at high frame rates (11~29% latency) while enabling fluid control guided by user-friendly freehand sketches. We present a significant step towards practical, controllable, and physically plausible fluid simulations for real-time interactive applications. We promise to release both models and data upon acceptance.
On the Role of Label Noise in the Feature Learning Process
May 25, 2025Deep learning with noisy labels presents significant challenges. In this work, we theoretically characterize the role of label noise from a feature learning perspective. Specifically, we consider a signal-noise data distribution, where each sample comprises a label-dependent signal and label-independent noise, and rigorously analyze the training dynamics of a two-layer convolutional neural network under this data setup, along with the presence of label noise. Our analysis identifies two key stages. In Stage I, the model perfectly fits all the clean samples (i.e., samples without label noise) while ignoring the noisy ones (i.e., samples with noisy labels). During this stage, the model learns the signal from the clean samples, which generalizes well on unseen data. In Stage II, as the training loss converges, the gradient in the direction of noise surpasses that of the signal, leading to overfitting on noisy samples. Eventually, the model memorizes the noise present in the noisy samples and degrades its generalization ability. Furthermore, our analysis provides a theoretical basis for two widely used techniques for tackling label noise: early stopping and sample selection. Experiments on both synthetic and real-world setups validate our theory.
On the Learning with Augmented Class via Forests
May 14, 2025Decision trees and forests have achieved successes in various real applications, most working with all testing classes known in training data. In this work, we focus on learning with augmented class via forests, where an augmented class may appear in testing data yet not in training data. We incorporate information of augmented class into trees' splitting, i.e., a new splitting criterion, called augmented Gini impurity, is introduced to exploit some unlabeled data from testing distribution. We then develop the approach named Learning with Augmented Class via Forests (LACForest), which constructs shallow forests based on the augmented Gini impurity and then splits forests with pseudo-labeled augmented instances for better performance. We also develop deep neural forests with a novel optimization objective based on our augmented Gini impurity, so as to utilize the representation power of neural networks for forests. Theoretically, we present the convergence analysis for augmented Gini impurity, and finally conduct experiments to verify the effectiveness of our approaches. The code is available at https://github.com/nju-xuf/LACForest/.
PDE-Controller: LLMs for Autoformalization and Reasoning of PDEs
Feb 03, 2025



While recent AI-for-math has made strides in pure mathematics, areas of applied mathematics, particularly PDEs, remain underexplored despite their significant real-world applications. We present PDE-Controller, a framework that enables large language models (LLMs) to control systems governed by partial differential equations (PDEs). Our approach enables LLMs to transform informal natural language instructions into formal specifications, and then execute reasoning and planning steps to improve the utility of PDE control. We build a holistic solution comprising datasets (both human-written cases and 2 million synthetic samples), math-reasoning models, and novel evaluation metrics, all of which require significant effort. Our PDE-Controller significantly outperforms prompting the latest open-source and GPT models in reasoning, autoformalization, and program synthesis, achieving up to a 62% improvement in utility gain for PDE control. By bridging the gap between language generation and PDE systems, we demonstrate the potential of LLMs in addressing complex scientific and engineering challenges. We will release all data, model checkpoints, and code at https://pde-controller.github.io/.
Data-Efficient Inference of Neural Fluid Fields via SciML Foundation Model
Dec 18, 2024



Recent developments in 3D vision have enabled successful progress in inferring neural fluid fields and realistic rendering of fluid dynamics. However, these methods require real-world flow captures, which demand dense video sequences and specialized lab setups, making the process costly and challenging. Scientific machine learning (SciML) foundation models, which are pretrained on extensive simulations of partial differential equations (PDEs), encode rich multiphysics knowledge and thus provide promising sources of domain priors for inferring fluid fields. Nevertheless, their potential to advance real-world vision problems remains largely underexplored, raising questions about the transferability and practical utility of these foundation models. In this work, we demonstrate that SciML foundation model can significantly improve the data efficiency of inferring real-world 3D fluid dynamics with improved generalization. At the core of our method is leveraging the strong forecasting capabilities and meaningful representations of SciML foundation models. We equip neural fluid fields with a novel collaborative training approach that utilizes augmented views and fluid features extracted by our foundation model. Our method demonstrates significant improvements in both quantitative metrics and visual quality, showcasing the practical applicability of SciML foundation models in real-world fluid dynamics.
Collapsed Language Models Promote Fairness
Oct 06, 2024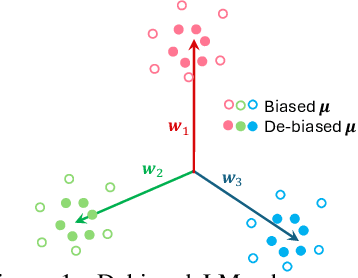
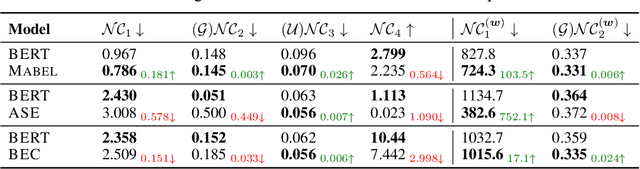
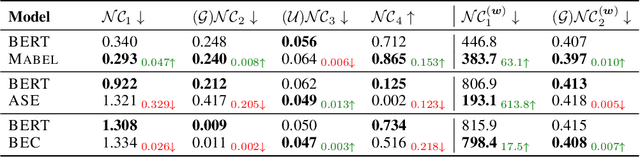
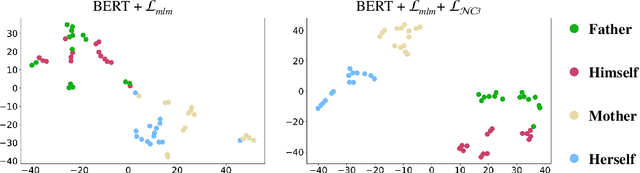
To mitigate societal biases implicitly encoded in recent successful pretrained language models, a diverse array of approaches have been proposed to encourage model fairness, focusing on prompting, data augmentation, regularized fine-tuning, and more. Despite the development, it is nontrivial to reach a principled understanding of fairness and an effective algorithm that can consistently debias language models. In this work, by rigorous evaluations of Neural Collapse -- a learning phenomenon happen in last-layer representations and classifiers in deep networks -- on fairness-related words, we find that debiased language models exhibit collapsed alignment between token representations and word embeddings. More importantly, this observation inspires us to design a principled fine-tuning method that can effectively improve fairness in a wide range of debiasing methods, while still preserving the performance of language models on standard natural language understanding tasks. We attach our code at https://anonymous.4open.science/r/Fairness_NC-457E .
Contrastive Learning-based Chaining-Cluster for Multilingual Voice-Face Association
Aug 04, 2024



The innate correlation between a person's face and voice has recently emerged as a compelling area of study, especially within the context of multilingual environments. This paper introduces our novel solution to the Face-Voice Association in Multilingual Environments (FAME) 2024 challenge, focusing on a contrastive learning-based chaining-cluster method to enhance face-voice association. This task involves the challenges of building biometric relations between auditory and visual modality cues and modelling the prosody interdependence between different languages while addressing both intrinsic and extrinsic variability present in the data. To handle these non-trivial challenges, our method employs supervised cross-contrastive (SCC) learning to establish robust associations between voices and faces in multi-language scenarios. Following this, we have specifically designed a chaining-cluster-based post-processing step to mitigate the impact of outliers often found in unconstrained in the wild data. We conducted extensive experiments to investigate the impact of language on face-voice association. The overall results were evaluated on the FAME public evaluation platform, where we achieved 2nd place. The results demonstrate the superior performance of our method, and we validate the robustness and effectiveness of our proposed approach. Code is available at https://github.com/colaudiolab/FAME24_solution.