 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollapsed Language Models Promote Fairness
Paper and Code
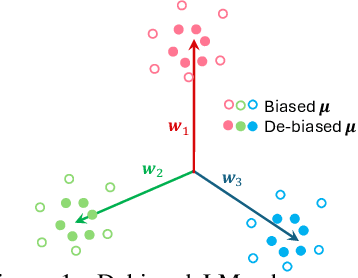
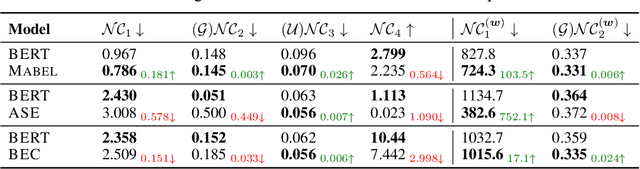
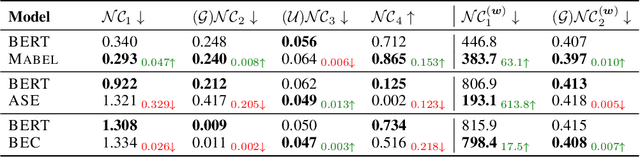
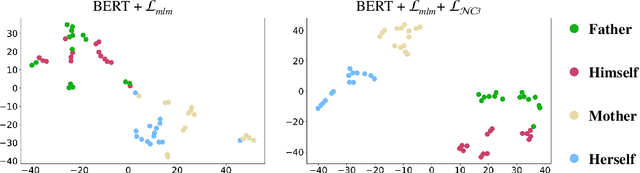
To mitigate societal biases implicitly encoded in recent successful pretrained language models, a diverse array of approaches have been proposed to encourage model fairness, focusing on prompting, data augmentation, regularized fine-tuning, and more. Despite the development, it is nontrivial to reach a principled understanding of fairness and an effective algorithm that can consistently debias language models. In this work, by rigorous evaluations of Neural Collapse -- a learning phenomenon happen in last-layer representations and classifiers in deep networks -- on fairness-related words, we find that debiased language models exhibit collapsed alignment between token representations and word embeddings. More importantly, this observation inspires us to design a principled fine-tuning method that can effectively improve fairness in a wide range of debiasing methods, while still preserving the performance of language models on standard natural language understanding tasks. We attach our code at https://anonymous.4open.science/r/Fairness_NC-457E .