 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Client Selection via Q-Learning-based Whittle Index in Wireless Federated Learning
Sep 19, 2025We consider the client selection problem in wireless Federated Learning (FL), with the objective of reducing the total required time to achieve a certain level of learning accuracy. Since the server cannot observe the clients' dynamic states that can change their computation and communication efficiency, we formulate client selection as a restless multi-armed bandit problem. We propose a scalable and efficient approach called the Whittle Index Learning in Federated Q-learning (WILF-Q), which uses Q-learning to adaptively learn and update an approximated Whittle index associated with each client, and then selects the clients with the highest indices. Compared to existing approaches, WILF-Q does not require explicit knowledge of client state transitions or data distributions, making it well-suited for deployment in practical FL settings. Experiment results demonstrate that WILF-Q significantly outperforms existing baseline policies in terms of learning efficiency, providing a robust and efficient approach to client selection in wireless FL.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Federated Learning of Shareable Bases for Personalization-Friendly Image Classification
Apr 16, 2023Personalized federated learning (PFL) aims to harness the collective wisdom of clients' data to build customized models tailored to individual clients' data distributions. Existing works offer personalization primarily to clients who participate in the FL process, making it hard to encompass new clients who were absent or newly show up. In this paper, we propose FedBasis, a novel PFL framework to tackle such a deficiency. FedBasis learns a set of few, shareable ``basis'' models, which can be linearly combined to form personalized models for clients. Specifically for a new client, only a small set of combination coefficients, not the models, needs to be learned. This notion makes FedBasis more parameter-efficient, robust, and accurate compared to other competitive PFL baselines, especially in the low data regime, without increasing the inference cost. To demonstrate its applicability, we also present a more practical PFL testbed for image classification, featuring larger data discrepancies across clients in both the image and label spaces as well as more faithful training and test splits.
Efficient Image Representation Learning with Federated Sampled Softmax
Mar 09, 2022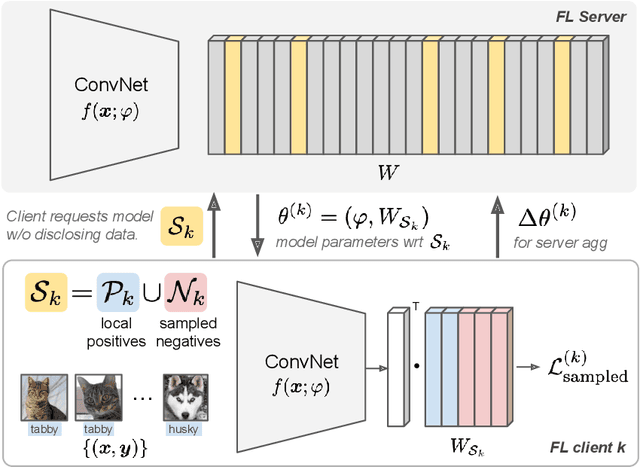
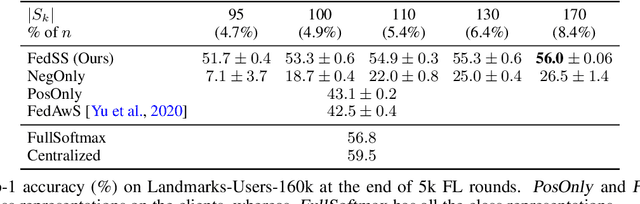
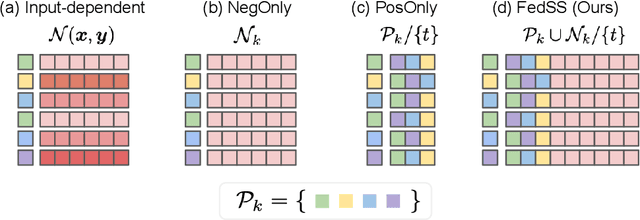
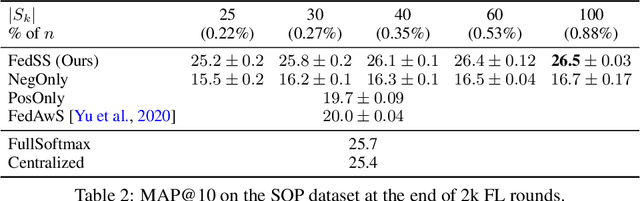
Learning image representations on decentralized data can bring many benefits in cases where data cannot be aggregated across data silos. Softmax cross entropy loss is highly effective and commonly used for learning image representations. Using a large number of classes has proven to be particularly beneficial for the descriptive power of such representations in centralized learning. However, doing so on decentralized data with Federated Learning is not straightforward as the demand on FL clients' computation and communication increases proportionally to the number of classes. In this work we introduce federated sampled softmax (FedSS), a resource-efficient approach for learning image representation with Federated Learning. Specifically, the FL clients sample a set of classes and optimize only the corresponding model parameters with respect to a sampled softmax objective that approximates the global full softmax objective. We examine the loss formulation and empirically show that our method significantly reduces the number of parameters transferred to and optimized by the client devices, while performing on par with the standard full softmax method. This work creates a possibility for efficiently learning image representations on decentralized data with a large number of classes under the federated setting.
FedLite: A Scalable Approach for Federated Learning on Resource-constrained Clients
Feb 16, 2022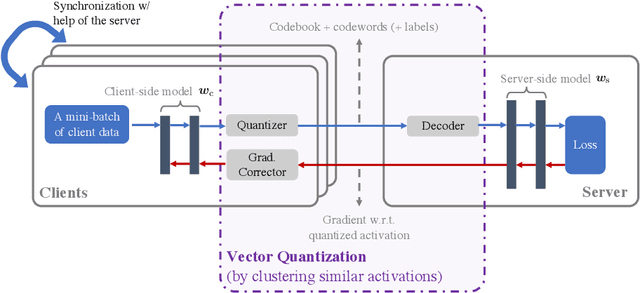

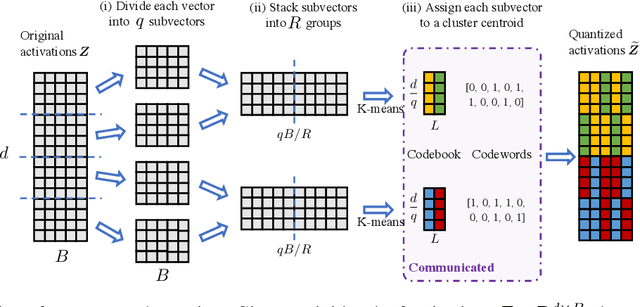
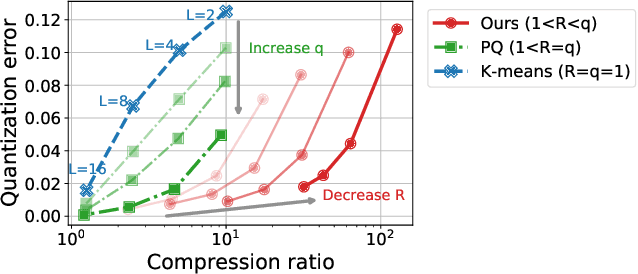
In classical federated learning, the clients contribute to the overall training by communicating local updates for the underlying model on their private data to a coordinating server. However, updating and communicating the entire model becomes prohibitively expensive when resource-constrained clients collectively aim to train a large machine learning model. Split learning provides a natural solution in such a setting, where only a small part of the model is stored and trained on clients while the remaining large part of the model only stays at the servers. However, the model partitioning employed in split learning introduces a significant amount of communication cost. This paper addresses this issue by compressing the additional communication using a novel clustering scheme accompanied by a gradient correction method. Extensive empirical evaluations on image and text benchmarks show that the proposed method can achieve up to $490\times$ communication cost reduction with minimal drop in accuracy, and enables a desirable performance vs. communication trade-off.
Federated Multi-Target Domain Adaptation
Aug 17, 2021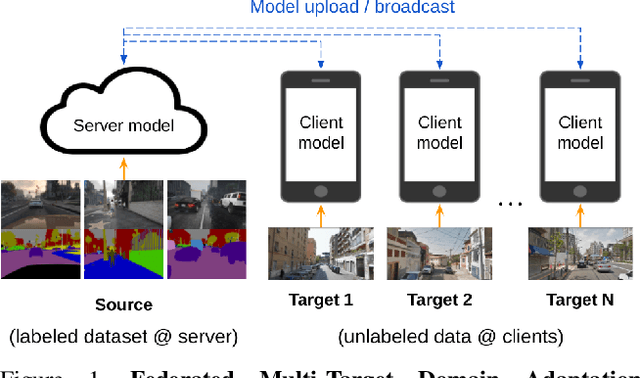
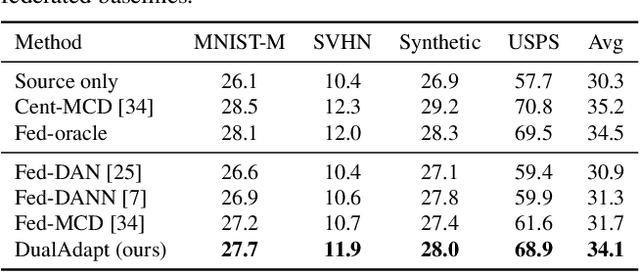
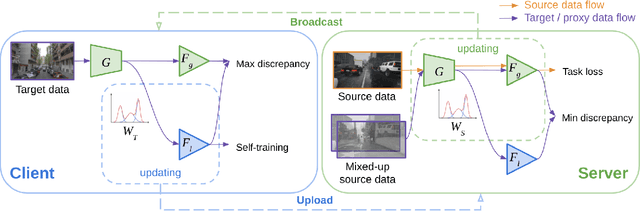
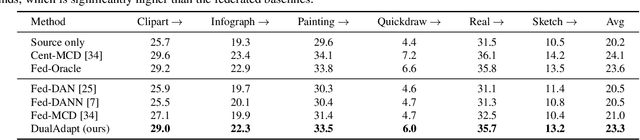
Federated learning methods enable us to train machine learning models on distributed user data while preserving its privacy. However, it is not always feasible to obtain high-quality supervisory signals from users, especially for vision tasks. Unlike typical federated settings with labeled client data, we consider a more practical scenario where the distributed client data is unlabeled, and a centralized labeled dataset is available on the server. We further take the server-client and inter-client domain shifts into account and pose a domain adaptation problem with one source (centralized server data) and multiple targets (distributed client data). Within this new Federated Multi-Target Domain Adaptation (FMTDA) task, we analyze the model performance of exiting domain adaptation methods and propose an effective DualAdapt method to address the new challenges. Extensive experimental results on image classification and semantic segmentation tasks demonstrate that our method achieves high accuracy, incurs minimal communication cost, and requires low computational resources on client devices.
A Field Guide to Federated Optimization
Jul 14, 2021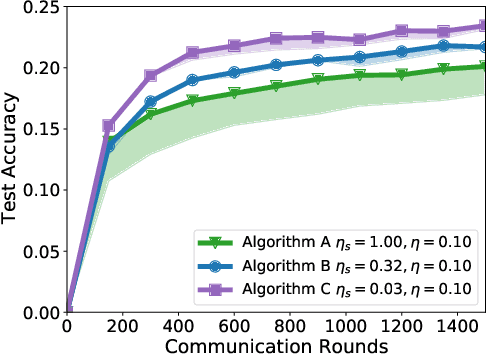


Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Federated Visual Classification with Real-World Data Distribution
Mar 18, 2020
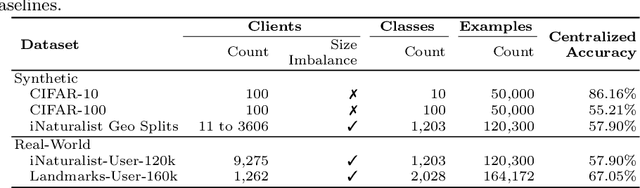
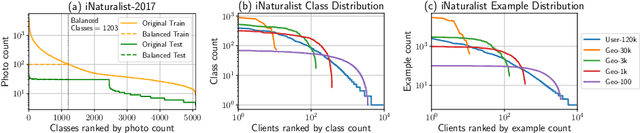
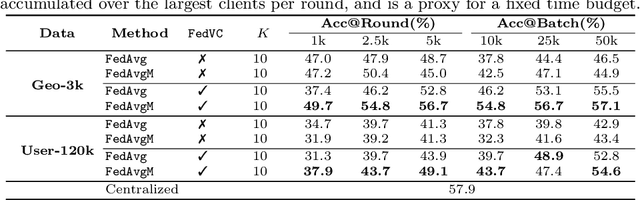
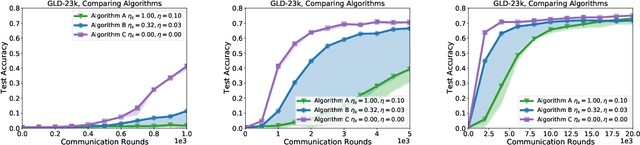
Federated Learning enables visual models to be trained on-device, bringing advantages for user privacy (data need never leave the device), but challenges in terms of data diversity and quality. Whilst typical models in the datacenter are trained using data that are independent and identically distributed (IID), data at source are typically far from IID. Furthermore, differing quantities of data are typically available at each device (imbalance). In this work, we characterize the effect these real-world data distributions have on distributed learning, using as a benchmark the standard Federated Averaging (FedAvg) algorithm. To do so, we introduce two new large-scale datasets for species and landmark classification, with realistic per-user data splits that simulate real-world edge learning scenarios. We also develop two new algorithms (FedVC, FedIR) that intelligently resample and reweight over the client pool, bringing large improvements in accuracy and stability in training.
Advances and Open Problems in Federated Learning
Dec 10, 2019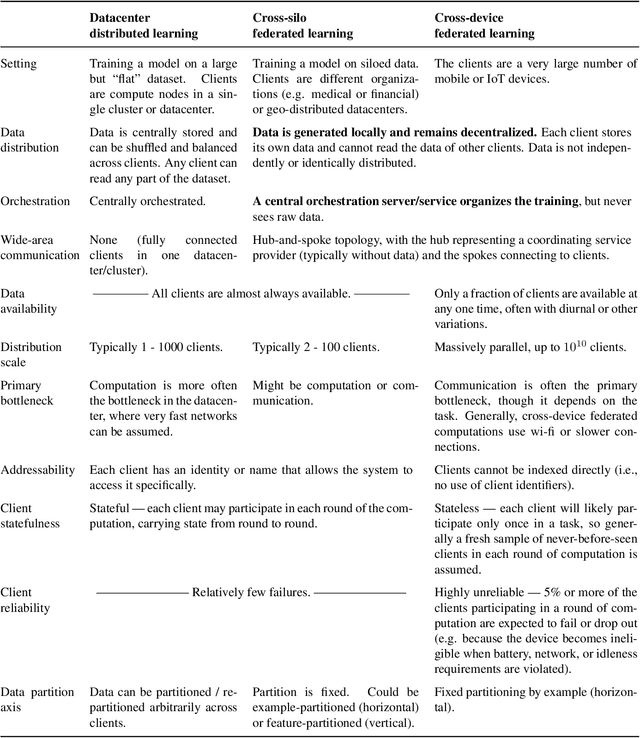
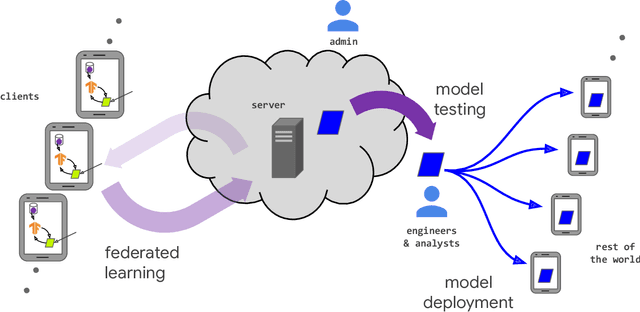
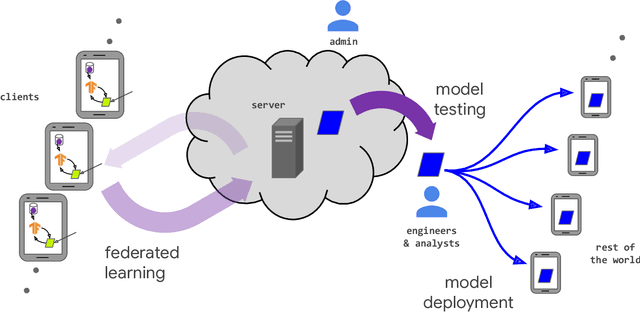

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
Sep 13, 2019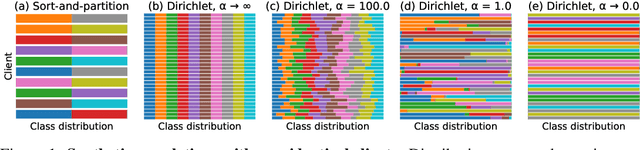
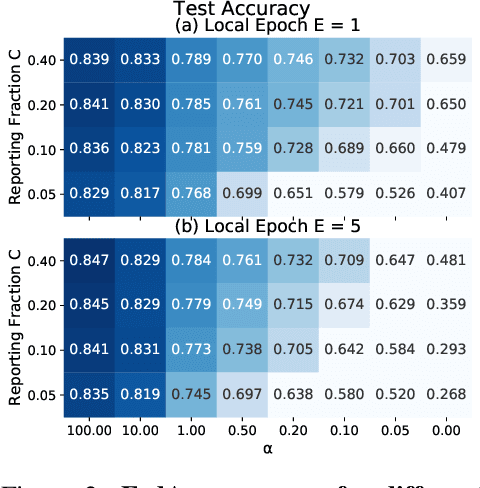
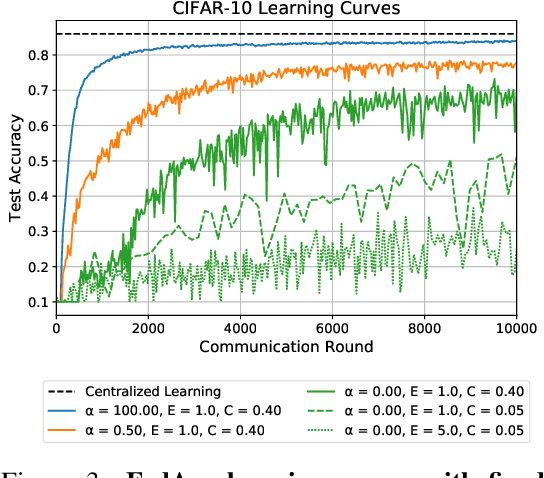
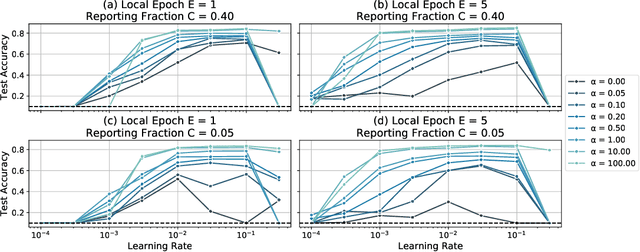
Federated Learning enables visual models to be trained in a privacy-preserving way using real-world data from mobile devices. Given their distributed nature, the statistics of the data across these devices is likely to differ significantly. In this work, we look at the effect such non-identical data distributions has on visual classification via Federated Learning. We propose a way to synthesize datasets with a continuous range of identicalness and provide performance measures for the Federated Averaging algorithm. We show that performance degrades as distributions differ more, and propose a mitigation strategy via server momentum. Experiments on CIFAR-10 demonstrate improved classification performance over a range of non-identicalness, with classification accuracy improved from 30.1% to 76.9% in the most skewed settings.