 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Shot Learning with Imprinted Weights
Apr 06, 2018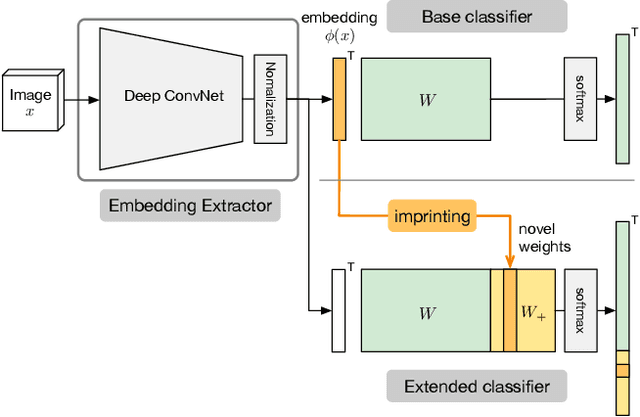
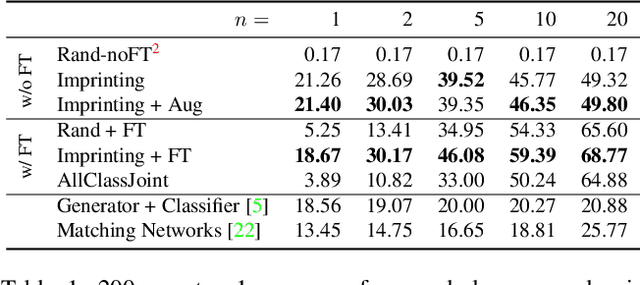
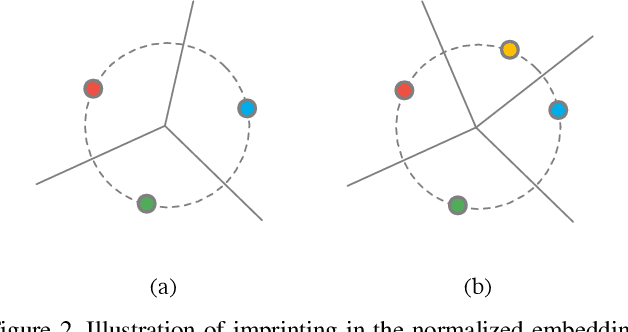
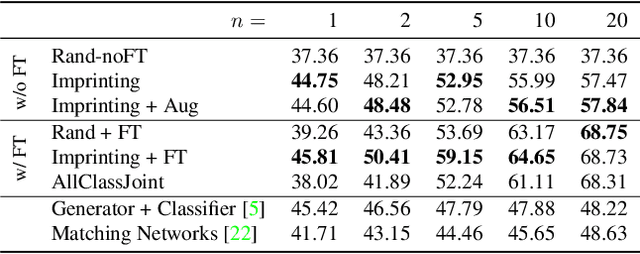
Human vision is able to immediately recognize novel visual categories after seeing just one or a few training examples. We describe how to add a similar capability to ConvNet classifiers by directly setting the final layer weights from novel training examples during low-shot learning. We call this process weight imprinting as it directly sets weights for a new category based on an appropriately scaled copy of the embedding layer activations for that training example. The imprinting process provides a valuable complement to training with stochastic gradient descent, as it provides immediate good classification performance and an initialization for any further fine-tuning in the future. We show how this imprinting process is related to proxy-based embeddings. However, it differs in that only a single imprinted weight vector is learned for each novel category, rather than relying on a nearest-neighbor distance to training instances as typically used with embedding methods. Our experiments show that using averaging of imprinted weights provides better generalization than using nearest-neighbor instance embeddings.
Unsupervised Learning of Depth and Ego-Motion from Video
Aug 01, 2017
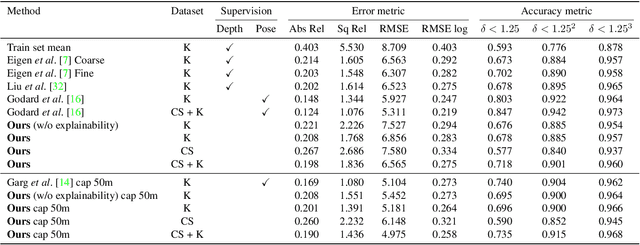
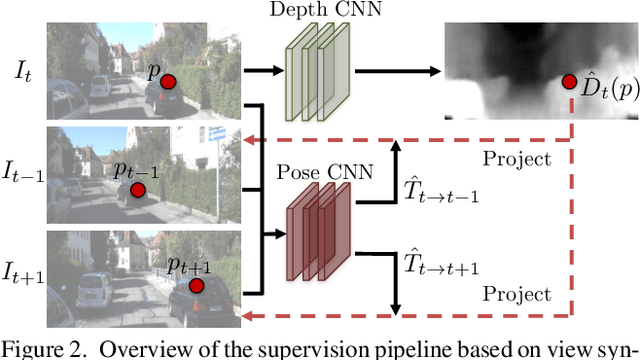
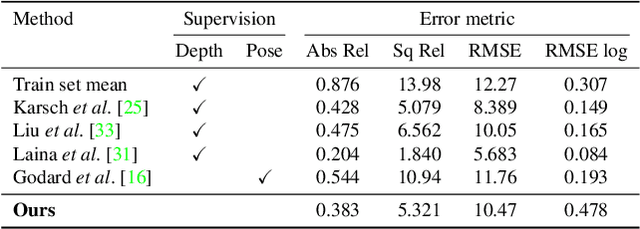
We present an unsupervised learning framework for the task of monocular depth and camera motion estimation from unstructured video sequences. We achieve this by simultaneously training depth and camera pose estimation networks using the task of view synthesis as the supervisory signal. The networks are thus coupled via the view synthesis objective during training, but can be applied independently at test time. Empirical evaluation on the KITTI dataset demonstrates the effectiveness of our approach: 1) monocular depth performing comparably with supervised methods that use either ground-truth pose or depth for training, and 2) pose estimation performing favorably with established SLAM systems under comparable input settings.
Self-Learning for Player Localization in Sports Video
Jul 27, 2013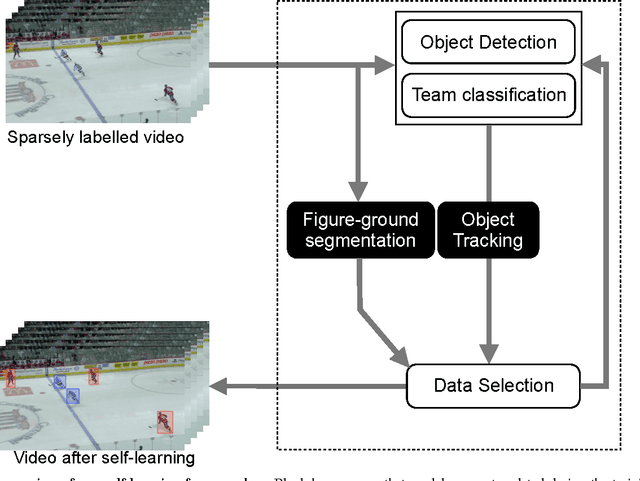

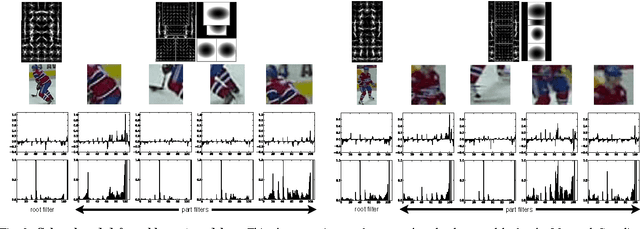
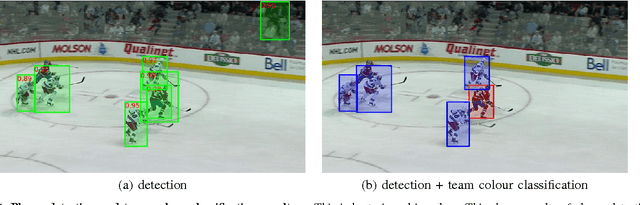
This paper introduces a novel self-learning framework that automates the label acquisition process for improving models for detecting players in broadcast footage of sports games. Unlike most previous self-learning approaches for improving appearance-based object detectors from videos, we allow an unknown, unconstrained number of target objects in a more generalized video sequence with non-static camera views. Our self-learning approach uses a latent SVM learning algorithm and deformable part models to represent the shape and colour information of players, constraining their motions, and learns the colour of the playing field by a gentle Adaboost algorithm. We combine those image cues and discover additional labels automatically from unlabelled data. In our experiments, our approach exploits both labelled and unlabelled data in sparsely labelled videos of sports games, providing a mean performance improvement of over 20% in the average precision for detecting sports players and improved tracking, when videos contain very few labelled images.
Local Naive Bayes Nearest Neighbor for Image Classification
Dec 01, 2011

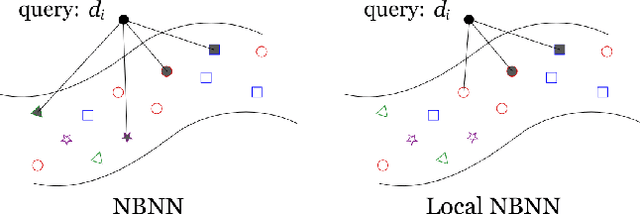

We present Local Naive Bayes Nearest Neighbor, an improvement to the NBNN image classification algorithm that increases classification accuracy and improves its ability to scale to large numbers of object classes. The key observation is that only the classes represented in the local neighborhood of a descriptor contribute significantly and reliably to their posterior probability estimates. Instead of maintaining a separate search structure for each class, we merge all of the reference data together into one search structure, allowing quick identification of a descriptor's local neighborhood. We show an increase in classification accuracy when we ignore adjustments to the more distant classes and show that the run time grows with the log of the number of classes rather than linearly in the number of classes as did the original. This gives a 100 times speed-up over the original method on the Caltech 256 dataset. We also provide the first head-to-head comparison of NBNN against spatial pyramid methods using a common set of input features. We show that local NBNN outperforms all previous NBNN based methods and the original spatial pyramid model. However, we find that local NBNN, while competitive with, does not beat state-of-the-art spatial pyramid methods that use local soft assignment and max-pooling.