Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Depth and Ego-Motion from Video
Paper and Code

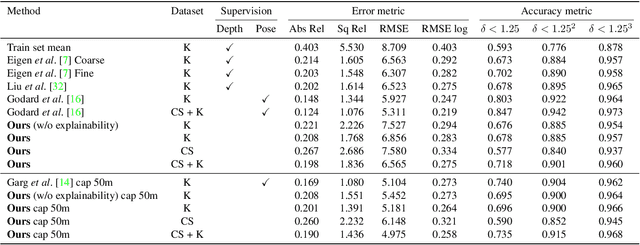
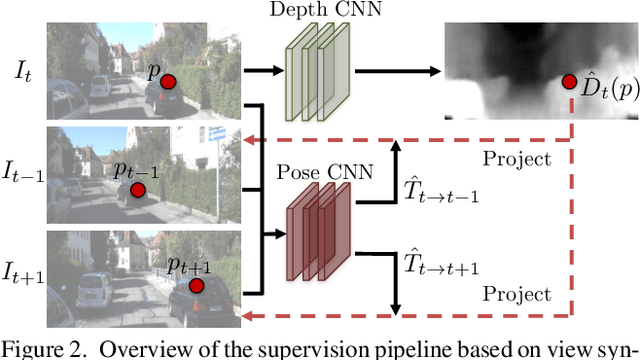
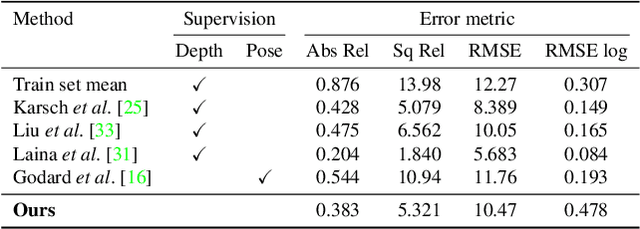
We present an unsupervised learning framework for the task of monocular depth and camera motion estimation from unstructured video sequences. We achieve this by simultaneously training depth and camera pose estimation networks using the task of view synthesis as the supervisory signal. The networks are thus coupled via the view synthesis objective during training, but can be applied independently at test time. Empirical evaluation on the KITTI dataset demonstrates the effectiveness of our approach: 1) monocular depth performing comparably with supervised methods that use either ground-truth pose or depth for training, and 2) pose estimation performing favorably with established SLAM systems under comparable input settings.
* Accepted to CVPR 2017. Project webpage:
https://people.eecs.berkeley.edu/~tinghuiz/projects/SfMLearner/
View paper on