 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Learning for Player Localization in Sports Video
Paper and Code
Jul 27, 2013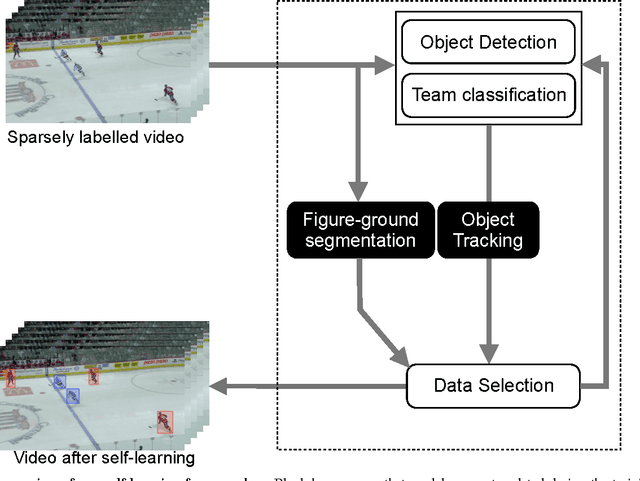

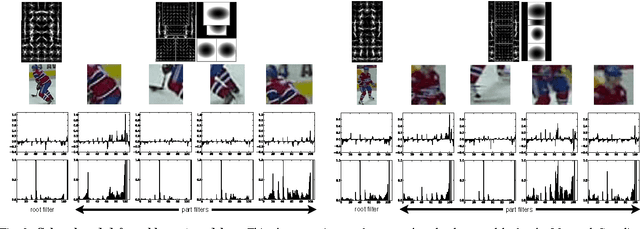
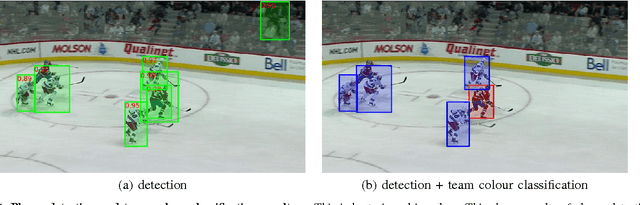
This paper introduces a novel self-learning framework that automates the label acquisition process for improving models for detecting players in broadcast footage of sports games. Unlike most previous self-learning approaches for improving appearance-based object detectors from videos, we allow an unknown, unconstrained number of target objects in a more generalized video sequence with non-static camera views. Our self-learning approach uses a latent SVM learning algorithm and deformable part models to represent the shape and colour information of players, constraining their motions, and learns the colour of the playing field by a gentle Adaboost algorithm. We combine those image cues and discover additional labels automatically from unlabelled data. In our experiments, our approach exploits both labelled and unlabelled data in sparsely labelled videos of sports games, providing a mean performance improvement of over 20% in the average precision for detecting sports players and improved tracking, when videos contain very few labelled images.