 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of One: A Single Example is All it Takes for Segmentation in VLMs
Mar 13, 2025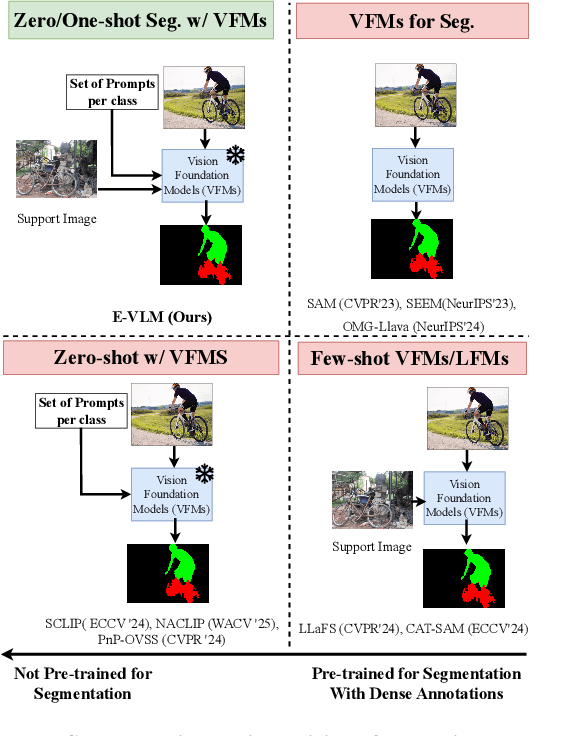
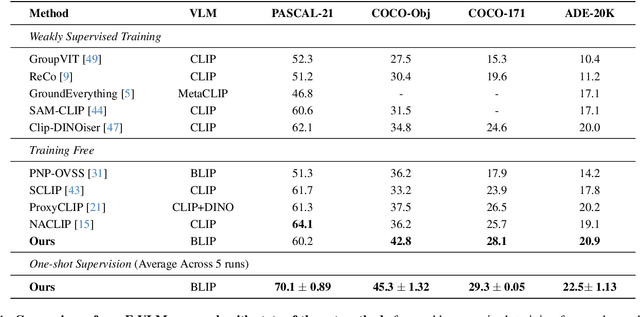
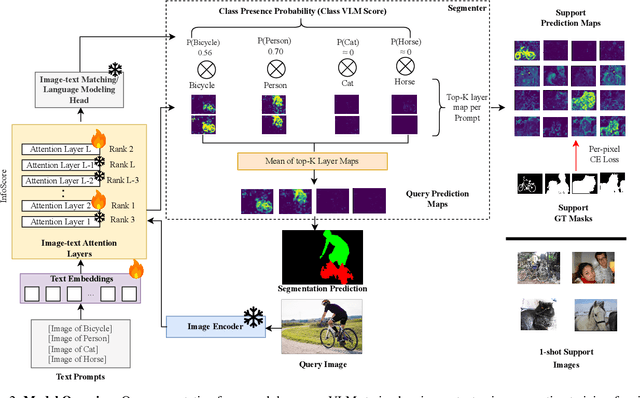
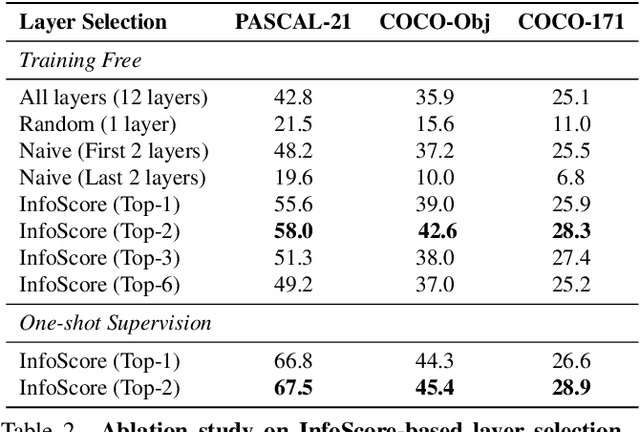
Large-scale vision-language models (VLMs), trained on extensive datasets of image-text pairs, exhibit strong multimodal understanding capabilities by implicitly learning associations between textual descriptions and image regions. This emergent ability enables zero-shot object detection and segmentation, using techniques that rely on text-image attention maps, without necessarily training on abundant labeled segmentation datasets. However, performance of such methods depends heavily on prompt engineering and manually selected layers or head choices for the attention layers. In this work, we demonstrate that, rather than relying solely on textual prompts, providing a single visual example for each category and fine-tuning the text-to-image attention layers and embeddings significantly improves the performance. Additionally, we propose learning an ensemble through few-shot fine-tuning across multiple layers and/or prompts. An entropy-based ranking and selection mechanism for text-to-image attention layers is proposed to identify the top-performing layers without the need for segmentation labels. This eliminates the need for hyper-parameter selection of text-to-image attention layers, providing a more flexible and scalable solution for open-vocabulary segmentation. We show that this approach yields strong zero-shot performance, further enhanced through fine-tuning with a single visual example. Moreover, we demonstrate that our method and findings are general and can be applied across various vision-language models (VLMs).
MM-R$^3$: On (In-)Consistency of Multi-modal Large Language Models (MLLMs)
Oct 07, 2024With the advent of Large Language Models (LLMs) and Multimodal (Visio-lingual) LLMs, a flurry of research has emerged, analyzing the performance of such models across a diverse array of tasks. While most studies focus on evaluating the capabilities of state-of-the-art (SoTA) MLLM models through task accuracy (e.g., Visual Question Answering, grounding) across various datasets, our work explores the related but complementary aspect of consistency - the ability of an MLLM model to produce semantically similar or identical responses to semantically similar queries. We note that consistency is a fundamental prerequisite (necessary but not sufficient condition) for robustness and trust in MLLMs. Humans, in particular, are known to be highly consistent (even if not always accurate) in their responses, and consistency is inherently expected from AI systems. Armed with this perspective, we propose the MM-R$^3$ benchmark, which analyses the performance in terms of consistency and accuracy in SoTA MLLMs with three tasks: Question Rephrasing, Image Restyling, and Context Reasoning. Our analysis reveals that consistency does not always align with accuracy, indicating that models with higher accuracy are not necessarily more consistent, and vice versa. Furthermore, we propose a simple yet effective mitigation strategy in the form of an adapter module trained to minimize inconsistency across prompts. With our proposed strategy, we are able to achieve absolute improvements of 5.7% and 12.5%, on average on widely used MLLMs such as BLIP-2 and LLaVa 1.5M in terms of consistency over their existing counterparts.
Visual Prompting for Generalized Few-shot Segmentation: A Multi-scale Approach
Apr 17, 2024The emergence of attention-based transformer models has led to their extensive use in various tasks, due to their superior generalization and transfer properties. Recent research has demonstrated that such models, when prompted appropriately, are excellent for few-shot inference. However, such techniques are under-explored for dense prediction tasks like semantic segmentation. In this work, we examine the effectiveness of prompting a transformer-decoder with learned visual prompts for the generalized few-shot segmentation (GFSS) task. Our goal is to achieve strong performance not only on novel categories with limited examples, but also to retain performance on base categories. We propose an approach to learn visual prompts with limited examples. These learned visual prompts are used to prompt a multiscale transformer decoder to facilitate accurate dense predictions. Additionally, we introduce a unidirectional causal attention mechanism between the novel prompts, learned with limited examples, and the base prompts, learned with abundant data. This mechanism enriches the novel prompts without deteriorating the base class performance. Overall, this form of prompting helps us achieve state-of-the-art performance for GFSS on two different benchmark datasets: COCO-$20^i$ and Pascal-$5^i$, without the need for test-time optimization (or transduction). Furthermore, test-time optimization leveraging unlabelled test data can be used to improve the prompts, which we refer to as transductive prompt tuning.
Implicit and Explicit Commonsense for Multi-sentence Video Captioning
Mar 14, 2023



Existing dense or paragraph video captioning approaches rely on holistic representations of videos, possibly coupled with learned object/action representations, to condition hierarchical language decoders. However, they fundamentally lack the commonsense knowledge of the world required to reason about progression of events, causality, and even function of certain objects within a scene. To address this limitation we propose a novel video captioning Transformer-based model, that takes into account both implicit (visuo-lingual and purely linguistic) and explicit (knowledge-base) commonsense knowledge. We show that these forms of knowledge, in isolation and in combination, enhance the quality of produced captions. Further, inspired by imitation learning, we propose a new task of instruction generation, where the goal is to produce a set of linguistic instructions from a video demonstration of its performance. We formalize the task using ALFRED dataset [52] generated using an AI2-THOR environment. While instruction generation is conceptually similar to paragraph captioning, it differs in the fact that it exhibits stronger object persistence, as well as spatially-aware and causal sentence structure. We show that our commonsense knowledge enhanced approach produces significant improvements on this task (up to 57% in METEOR and 8.5% in CIDEr), as well as the state-of-the-art result on more traditional video captioning in the ActivityNet Captions dataset [29].
Semantically Enhanced Global Reasoning for Semantic Segmentation
Dec 06, 2022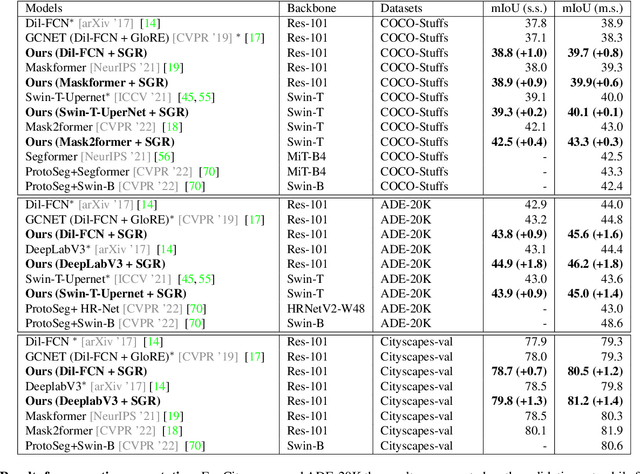
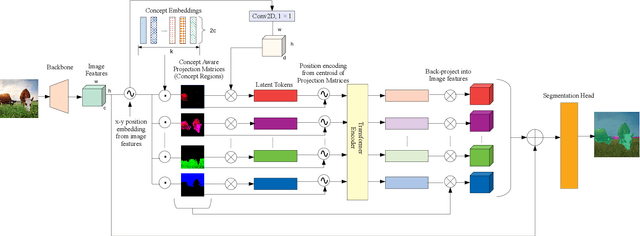
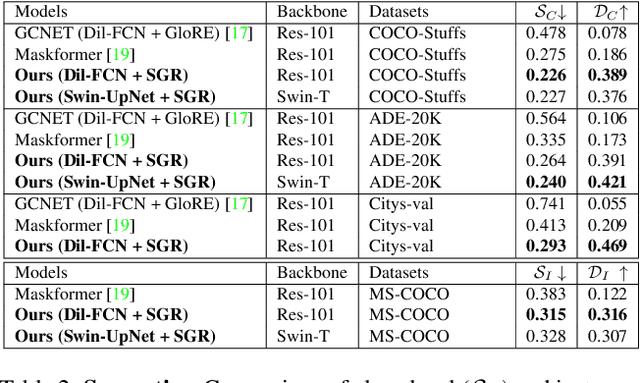

Recent advances in pixel-level tasks (e.g., segmentation) illustrate the benefit of long-range interactions between aggregated region-based representations that can enhance local features. However, such pixel-to-region associations and the resulting representation, which often take the form of attention, cannot model the underlying semantic structure of the scene (e.g., individual objects and, by extension, their interactions). In this work, we take a step toward addressing this limitation. Specifically, we propose an architecture where we learn to project image features into latent region representations and perform global reasoning across them, using a transformer, to produce contextualized and scene-consistent representations that are then fused with original pixel-level features. Our design enables the latent regions to represent semantically meaningful concepts, by ensuring that activated regions are spatially disjoint and unions of such regions correspond to connected object segments. The resulting semantic global reasoning (SGR) is end-to-end trainable and can be combined with any semantic segmentation framework and backbone. Combining SGR with DeepLabV3 results in a semantic segmentation performance that is competitive to the state-of-the-art, while resulting in more semantically interpretable and diverse region representations, which we show can effectively transfer to detection and instance segmentation. Further, we propose a new metric that allows us to measure the semantics of representations at both the object class and instance level.
Bootstrapping Human Optical Flow and Pose
Oct 28, 2022We propose a bootstrapping framework to enhance human optical flow and pose. We show that, for videos involving humans in scenes, we can improve both the optical flow and the pose estimation quality of humans by considering the two tasks at the same time. We enhance optical flow estimates by fine-tuning them to fit the human pose estimates and vice versa. In more detail, we optimize the pose and optical flow networks to, at inference time, agree with each other. We show that this results in state-of-the-art results on the Human 3.6M and 3D Poses in the Wild datasets, as well as a human-related subset of the Sintel dataset, both in terms of pose estimation accuracy and the optical flow accuracy at human joint locations. Code available at https://github.com/ubc-vision/bootstrapping-human-optical-flow-and-pose
UNeRF: Time and Memory Conscious U-Shaped Network for Training Neural Radiance Fields
Jun 23, 2022
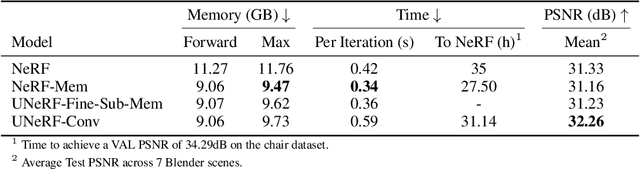
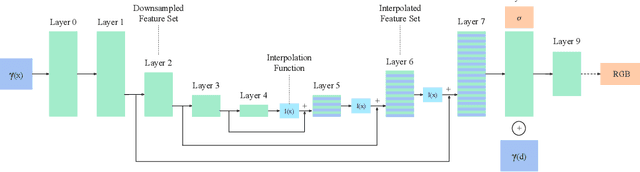

Neural Radiance Fields (NeRFs) increase reconstruction detail for novel view synthesis and scene reconstruction, with applications ranging from large static scenes to dynamic human motion. However, the increased resolution and model-free nature of such neural fields come at the cost of high training times and excessive memory requirements. Recent advances improve the inference time by using complementary data structures yet these methods are ill-suited for dynamic scenes and often increase memory consumption. Little has been done to reduce the resources required at training time. We propose a method to exploit the redundancy of NeRF's sample-based computations by partially sharing evaluations across neighboring sample points. Our UNeRF architecture is inspired by the UNet, where spatial resolution is reduced in the middle of the network and information is shared between adjacent samples. Although this change violates the strict and conscious separation of view-dependent appearance and view-independent density estimation in the NeRF method, we show that it improves novel view synthesis. We also introduce an alternative subsampling strategy which shares computation while minimizing any violation of view invariance. UNeRF is a plug-in module for the original NeRF network. Our major contributions include reduction of the memory footprint, improved accuracy, and reduced amortized processing time both during training and inference. With only weak assumptions on locality, we achieve improved resource utilization on a variety of neural radiance fields tasks. We demonstrate applications to the novel view synthesis of static scenes as well as dynamic human shape and motion.
ElePose: Unsupervised 3D Human Pose Estimation by Predicting Camera Elevation and Learning Normalizing Flows on 2D Poses
Dec 14, 2021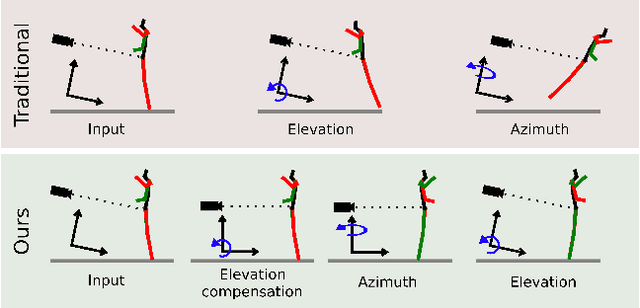
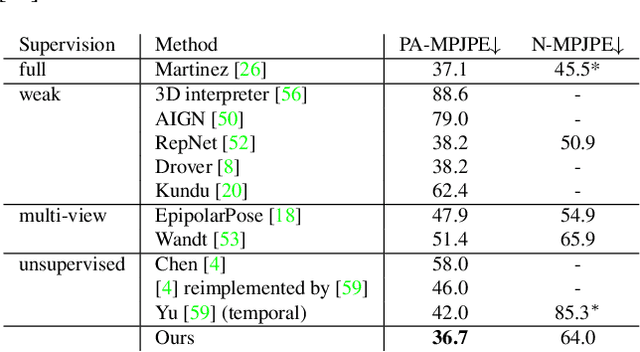
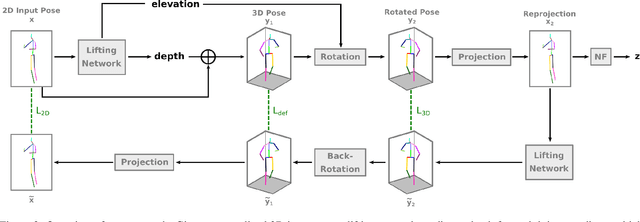

Human pose estimation from single images is a challenging problem that is typically solved by supervised learning. Unfortunately, labeled training data does not yet exist for many human activities since 3D annotation requires dedicated motion capture systems. Therefore, we propose an unsupervised approach that learns to predict a 3D human pose from a single image while only being trained with 2D pose data, which can be crowd-sourced and is already widely available. To this end, we estimate the 3D pose that is most likely over random projections, with the likelihood estimated using normalizing flows on 2D poses. While previous work requires strong priors on camera rotations in the training data set, we learn the distribution of camera angles which significantly improves the performance. Another part of our contribution is to stabilize training with normalizing flows on high-dimensional 3D pose data by first projecting the 2D poses to a linear subspace. We outperform the state-of-the-art unsupervised human pose estimation methods on the benchmark datasets Human3.6M and MPI-INF-3DHP in many metrics.
OptiBox: Breaking the Limits of Proposals for Visual Grounding
Nov 29, 2019
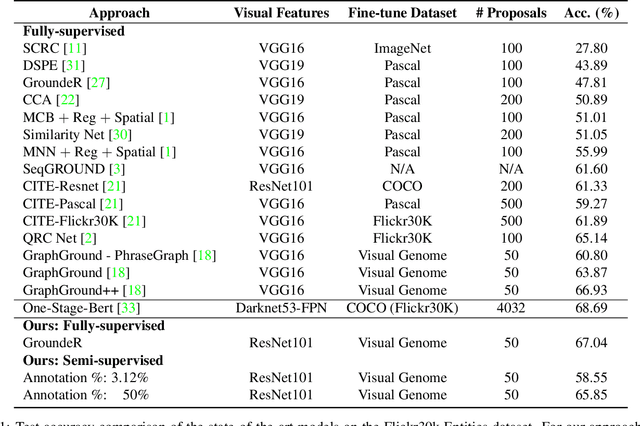
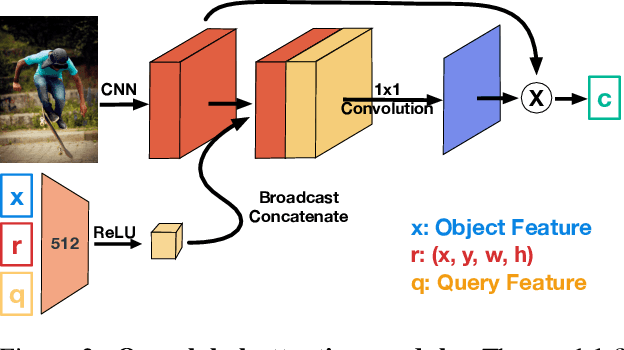

The problem of language grounding has attracted much attention in recent years due to its pivotal role in more general image-lingual high level reasoning tasks (e.g., image captioning, VQA). Despite the tremendous progress in visual grounding, the performance of most approaches has been hindered by the quality of bounding box proposals obtained in the early stages of all recent pipelines. To address this limitation, we propose a general progressive query-guided bounding box refinement architecture (OptiBox) that leverages global image encoding for added context. We apply this architecture in the context of the GroundeR model, first introduced in 2016, which has a number of unique and appealing properties, such as the ability to learn in the semi-supervised setting by leveraging cyclic language-reconstruction. Using GroundeR + OptiBox and a simple semantic language reconstruction loss that we propose, we achieve state-of-the-art grounding performance in the supervised setting on Flickr30k Entities dataset. More importantly, we are able to surpass many recent fully supervised models with only 50% of training data and perform competitively with as low as 3%.
Pan-tilt-zoom SLAM for Sports Videos
Jul 20, 2019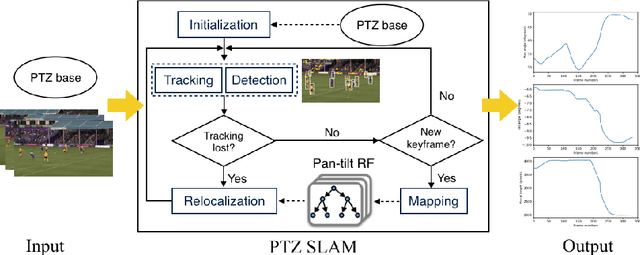
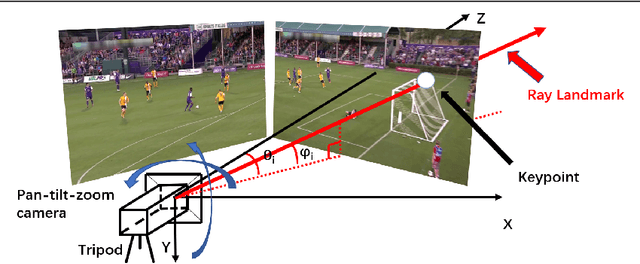
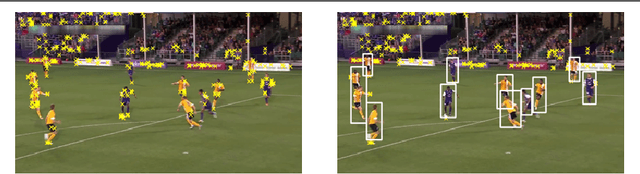
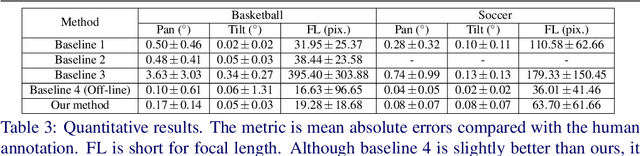
We present an online SLAM system specifically designed to track pan-tilt-zoom (PTZ) cameras in highly dynamic sports such as basketball and soccer games. In these games, PTZ cameras rotate very fast and players cover large image areas. To overcome these challenges, we propose to use a novel camera model for tracking and to use rays as landmarks in mapping. Rays overcome the missing depth in pure-rotation cameras. We also develop an online pan-tilt forest for mapping and introduce moving objects (players) detection to mitigate negative impacts from foreground objects. We test our method on both synthetic and real datasets. The experimental results show the superior performance of our method over previous methods for online PTZ camera pose estimation.