 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptiBox: Breaking the Limits of Proposals for Visual Grounding
Paper and Code
Nov 29, 2019
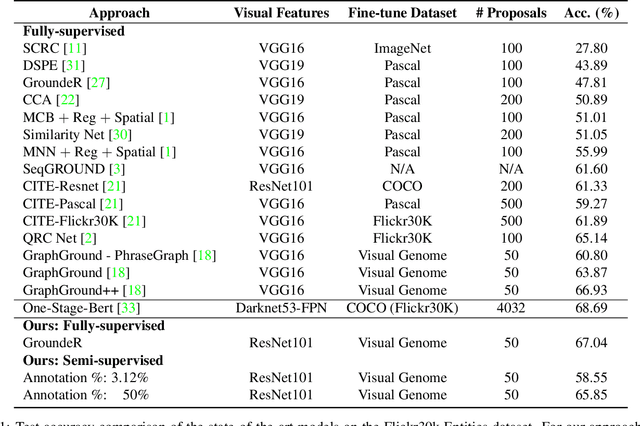
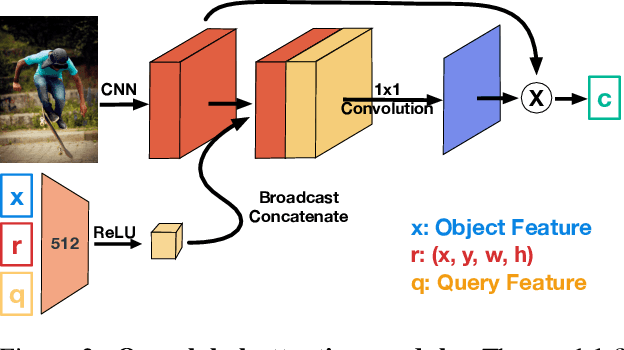

The problem of language grounding has attracted much attention in recent years due to its pivotal role in more general image-lingual high level reasoning tasks (e.g., image captioning, VQA). Despite the tremendous progress in visual grounding, the performance of most approaches has been hindered by the quality of bounding box proposals obtained in the early stages of all recent pipelines. To address this limitation, we propose a general progressive query-guided bounding box refinement architecture (OptiBox) that leverages global image encoding for added context. We apply this architecture in the context of the GroundeR model, first introduced in 2016, which has a number of unique and appealing properties, such as the ability to learn in the semi-supervised setting by leveraging cyclic language-reconstruction. Using GroundeR + OptiBox and a simple semantic language reconstruction loss that we propose, we achieve state-of-the-art grounding performance in the supervised setting on Flickr30k Entities dataset. More importantly, we are able to surpass many recent fully supervised models with only 50% of training data and perform competitively with as low as 3%.