 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Enhanced Global Reasoning for Semantic Segmentation
Paper and Code
Dec 06, 2022
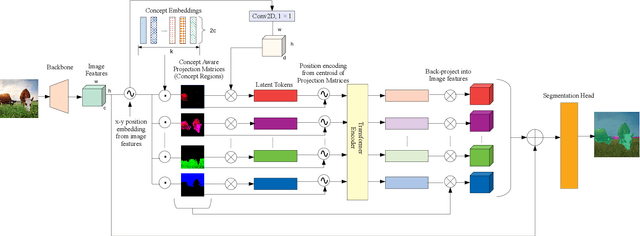
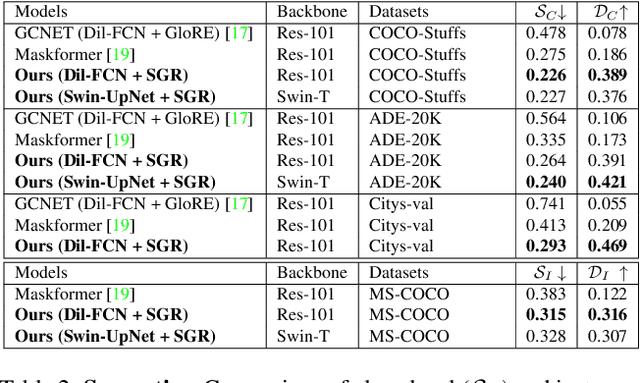

Recent advances in pixel-level tasks (e.g., segmentation) illustrate the benefit of long-range interactions between aggregated region-based representations that can enhance local features. However, such pixel-to-region associations and the resulting representation, which often take the form of attention, cannot model the underlying semantic structure of the scene (e.g., individual objects and, by extension, their interactions). In this work, we take a step toward addressing this limitation. Specifically, we propose an architecture where we learn to project image features into latent region representations and perform global reasoning across them, using a transformer, to produce contextualized and scene-consistent representations that are then fused with original pixel-level features. Our design enables the latent regions to represent semantically meaningful concepts, by ensuring that activated regions are spatially disjoint and unions of such regions correspond to connected object segments. The resulting semantic global reasoning (SGR) is end-to-end trainable and can be combined with any semantic segmentation framework and backbone. Combining SGR with DeepLabV3 results in a semantic segmentation performance that is competitive to the state-of-the-art, while resulting in more semantically interpretable and diverse region representations, which we show can effectively transfer to detection and instance segmentation. Further, we propose a new metric that allows us to measure the semantics of representations at both the object class and instance level.