 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Visual Classification with Real-World Data Distribution
Mar 18, 2020
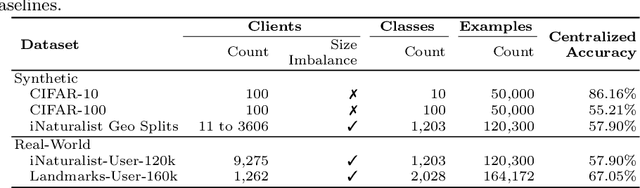
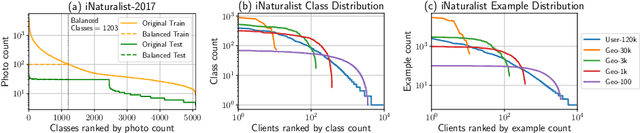
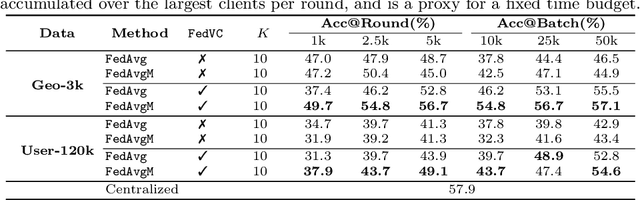
Federated Learning enables visual models to be trained on-device, bringing advantages for user privacy (data need never leave the device), but challenges in terms of data diversity and quality. Whilst typical models in the datacenter are trained using data that are independent and identically distributed (IID), data at source are typically far from IID. Furthermore, differing quantities of data are typically available at each device (imbalance). In this work, we characterize the effect these real-world data distributions have on distributed learning, using as a benchmark the standard Federated Averaging (FedAvg) algorithm. To do so, we introduce two new large-scale datasets for species and landmark classification, with realistic per-user data splits that simulate real-world edge learning scenarios. We also develop two new algorithms (FedVC, FedIR) that intelligently resample and reweight over the client pool, bringing large improvements in accuracy and stability in training.
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
Sep 13, 2019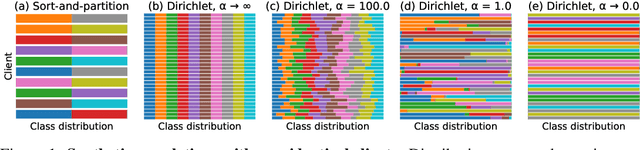
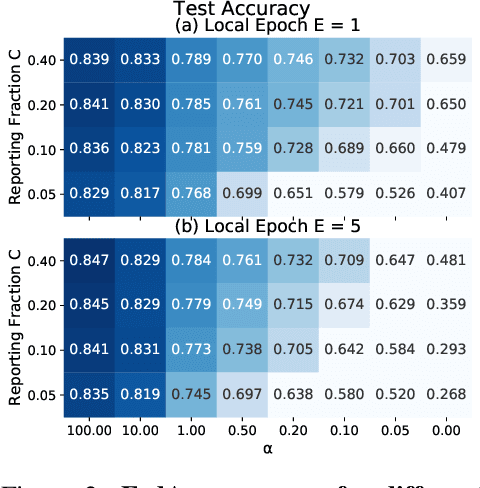
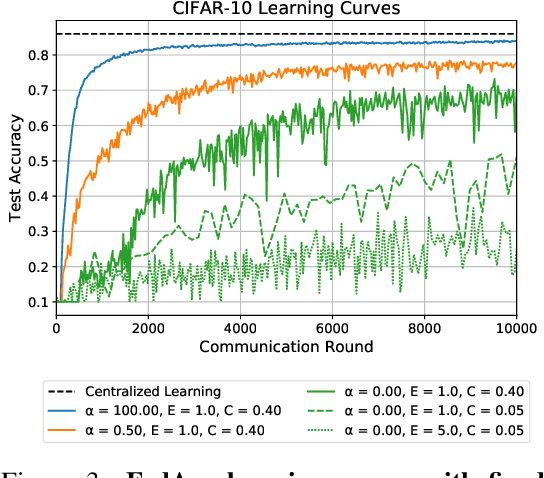
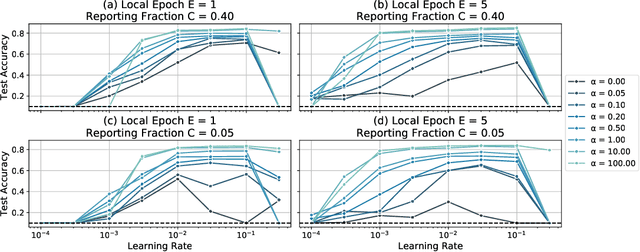
Federated Learning enables visual models to be trained in a privacy-preserving way using real-world data from mobile devices. Given their distributed nature, the statistics of the data across these devices is likely to differ significantly. In this work, we look at the effect such non-identical data distributions has on visual classification via Federated Learning. We propose a way to synthesize datasets with a continuous range of identicalness and provide performance measures for the Federated Averaging algorithm. We show that performance degrades as distributions differ more, and propose a mitigation strategy via server momentum. Experiments on CIFAR-10 demonstrate improved classification performance over a range of non-identicalness, with classification accuracy improved from 30.1% to 76.9% in the most skewed settings.
Clinically Accurate Chest X-Ray Report Generation
Apr 04, 2019
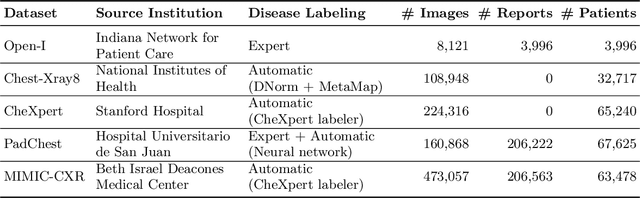
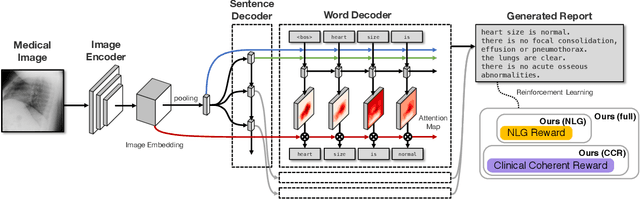
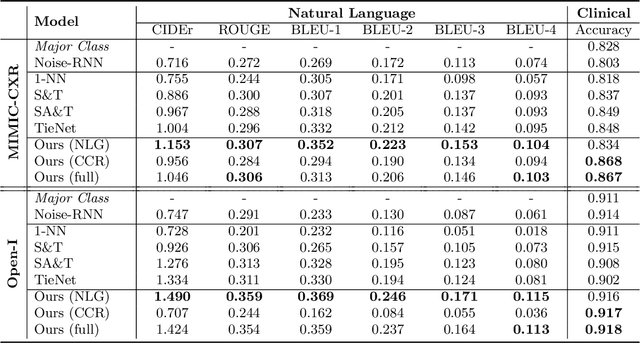
The automatic generation of radiology reports given medical radiographs has significant potential to operationally and clinically improve patient care. A number of prior works have focused on this problem, employing advanced methods from computer vision and natural language generation to produce readable reports. However, these works often fail to account for the particular nuances of the radiology domain, and, in particular, the critical importance of clinical accuracy in the resulting generated reports. In this work, we present a domain-aware automatic chest X-Ray radiology report generation system which first predicts what topics will be discussed in the report, then conditionally generates sentences corresponding to these topics. The resulting system is fine-tuned using reinforcement learning, considering both readability and clinical accuracy, as assessed by the proposed Clinically Coherent Reward. We verify this system on two datasets, Open-I and MIMIC-CXR, and demonstrate that our model offers marked improvements on both language generation metrics and CheXpert assessed accuracy over a variety of competitive baselines.
Unsupervised Multimodal Representation Learning across Medical Images and Reports
Nov 21, 2018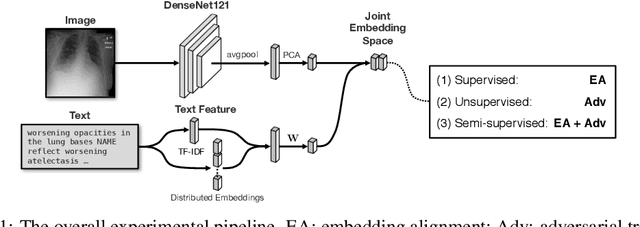
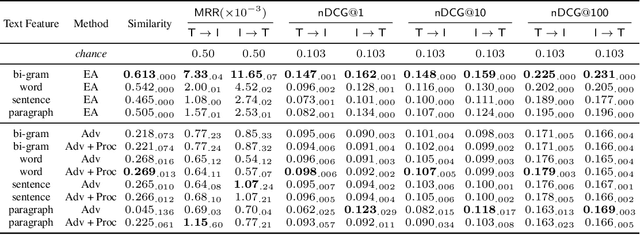
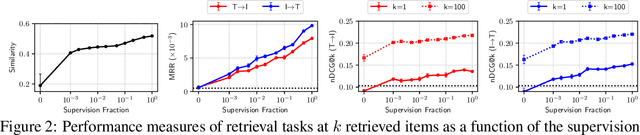
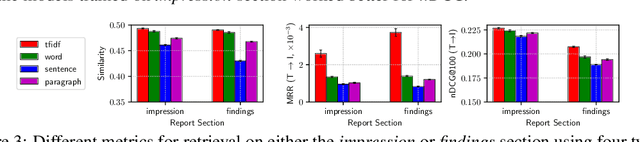
Joint embeddings between medical imaging modalities and associated radiology reports have the potential to offer significant benefits to the clinical community, ranging from cross-domain retrieval to conditional generation of reports to the broader goals of multimodal representation learning. In this work, we establish baseline joint embedding results measured via both local and global retrieval methods on the soon to be released MIMIC-CXR dataset consisting of both chest X-ray images and the associated radiology reports. We examine both supervised and unsupervised methods on this task and show that for document retrieval tasks with the learned representations, only a limited amount of supervision is needed to yield results comparable to those of fully-supervised methods.