 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMyStyle: A Personalized Generative Prior
Mar 31, 2022
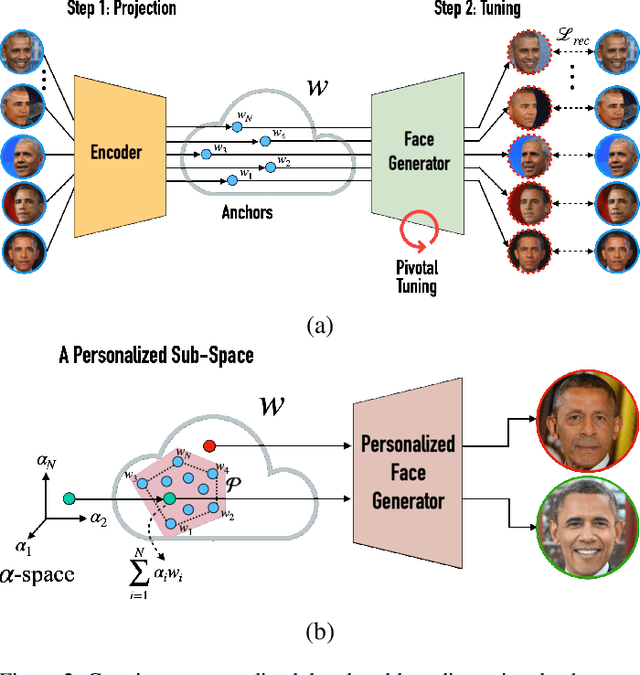
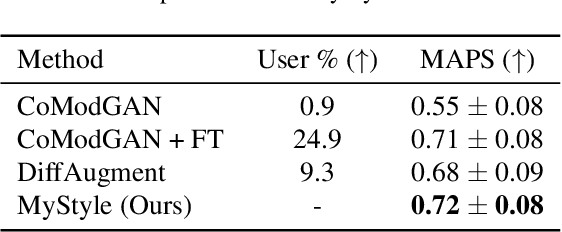

We introduce MyStyle, a personalized deep generative prior trained with a few shots of an individual. MyStyle allows to reconstruct, enhance and edit images of a specific person, such that the output is faithful to the person's key facial characteristics. Given a small reference set of portrait images of a person (~100), we tune the weights of a pretrained StyleGAN face generator to form a local, low-dimensional, personalized manifold in the latent space. We show that this manifold constitutes a personalized region that spans latent codes associated with diverse portrait images of the individual. Moreover, we demonstrate that we obtain a personalized generative prior, and propose a unified approach to apply it to various ill-posed image enhancement problems, such as inpainting and super-resolution, as well as semantic editing. Using the personalized generative prior we obtain outputs that exhibit high-fidelity to the input images and are also faithful to the key facial characteristics of the individual in the reference set. We demonstrate our method with fair-use images of numerous widely recognizable individuals for whom we have the prior knowledge for a qualitative evaluation of the expected outcome. We evaluate our approach against few-shots baselines and show that our personalized prior, quantitatively and qualitatively, outperforms state-of-the-art alternatives.
Zoom-to-Inpaint: Image Inpainting with High Frequency Details
Dec 17, 2020

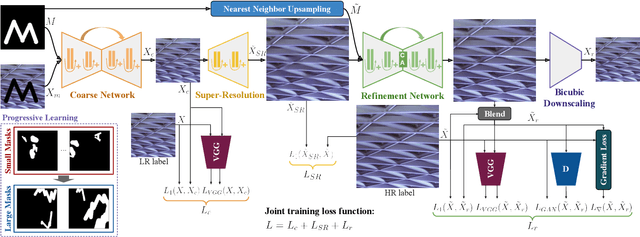
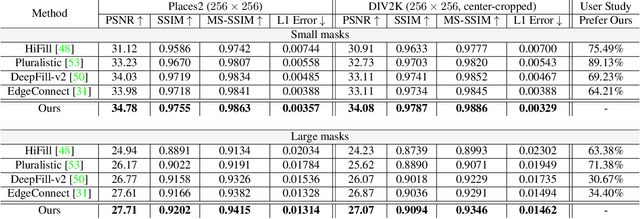
Although deep learning has enabled a huge leap forward in image inpainting, current methods are often unable to synthesize realistic high-frequency details. In this paper, we propose applying super resolution to coarsely reconstructed outputs, refining them at high resolution, and then downscaling the output to the original resolution. By introducing high-resolution images to the refinement network, our framework is able to reconstruct finer details that are usually smoothed out due to spectral bias - the tendency of neural networks to reconstruct low frequencies better than high frequencies. To assist training the refinement network on large upscaled holes, we propose a progressive learning technique in which the size of the missing regions increases as training progresses. Our zoom-in, refine and zoom-out strategy, combined with high-resolution supervision and progressive learning, constitutes a framework-agnostic approach for enhancing high-frequency details that can be applied to other inpainting methods. We provide qualitative and quantitative evaluations along with an ablation analysis to show the effectiveness of our approach, which outperforms state-of-the-art inpainting methods.
Sky Optimization: Semantically aware image processing of skies in low-light photography
Jun 15, 2020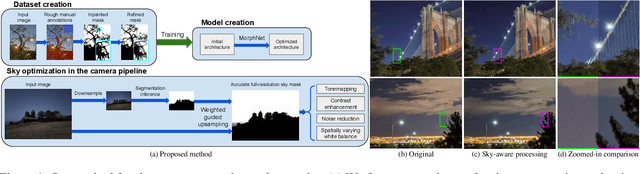

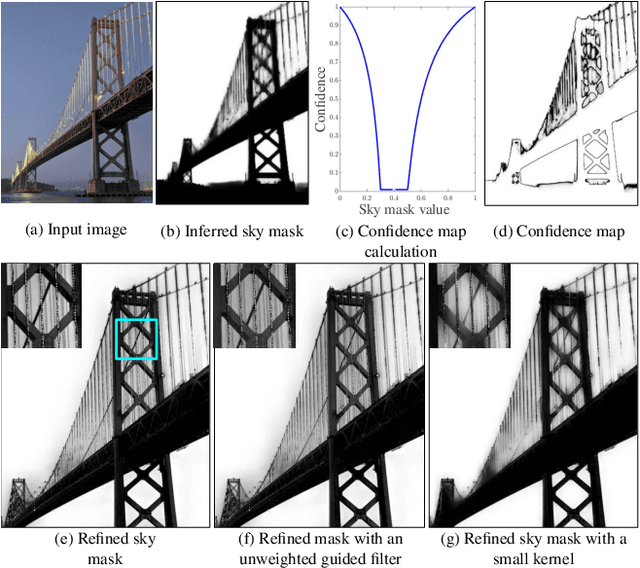
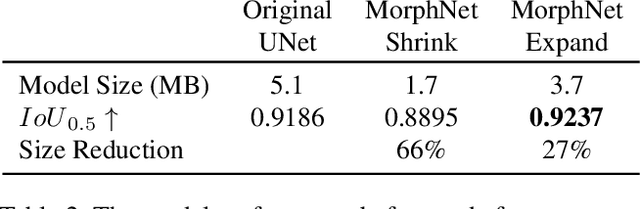
The sky is a major component of the appearance of a photograph, and its color and tone can strongly influence the mood of a picture. In nighttime photography, the sky can also suffer from noise and color artifacts. For this reason, there is a strong desire to process the sky in isolation from the rest of the scene to achieve an optimal look. In this work, we propose an automated method, which can run as a part of a camera pipeline, for creating accurate sky alpha-masks and using them to improve the appearance of the sky. Our method performs end-to-end sky optimization in less than half a second per image on a mobile device. We introduce a method for creating an accurate sky-mask dataset that is based on partially annotated images that are inpainted and refined by our modified weighted guided filter. We use this dataset to train a neural network for semantic sky segmentation. Due to the compute and power constraints of mobile devices, sky segmentation is performed at a low image resolution. Our modified weighted guided filter is used for edge-aware upsampling to resize the alpha-mask to a higher resolution. With this detailed mask we automatically apply post-processing steps to the sky in isolation, such as automatic spatially varying white-balance, brightness adjustments, contrast enhancement, and noise reduction.
Handheld Mobile Photography in Very Low Light
Oct 24, 2019

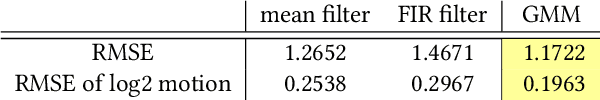

Taking photographs in low light using a mobile phone is challenging and rarely produces pleasing results. Aside from the physical limits imposed by read noise and photon shot noise, these cameras are typically handheld, have small apertures and sensors, use mass-produced analog electronics that cannot easily be cooled, and are commonly used to photograph subjects that move, like children and pets. In this paper we describe a system for capturing clean, sharp, colorful photographs in light as low as 0.3~lux, where human vision becomes monochromatic and indistinct. To permit handheld photography without flash illumination, we capture, align, and combine multiple frames. Our system employs "motion metering", which uses an estimate of motion magnitudes (whether due to handshake or moving objects) to identify the number of frames and the per-frame exposure times that together minimize both noise and motion blur in a captured burst. We combine these frames using robust alignment and merging techniques that are specialized for high-noise imagery. To ensure accurate colors in such low light, we employ a learning-based auto white balancing algorithm. To prevent the photographs from looking like they were shot in daylight, we use tone mapping techniques inspired by illusionistic painting: increasing contrast, crushing shadows to black, and surrounding the scene with darkness. All of these processes are performed using the limited computational resources of a mobile device. Our system can be used by novice photographers to produce shareable pictures in a few seconds based on a single shutter press, even in environments so dim that humans cannot see clearly.
* 22 pages, 27 figures