 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParetoSlider: Diffusion Models Post-Training for Continuous Reward Control
Apr 22, 2026Reinforcement Learning (RL) post-training has become the standard for aligning generative models with human preferences, yet most methods rely on a single scalar reward. When multiple criteria matter, the prevailing practice of ``early scalarization'' collapses rewards into a fixed weighted sum. This commits the model to a single trade-off point at training time, providing no inference-time control over inherently conflicting goals -- such as prompt adherence versus source fidelity in image editing. We introduce ParetoSlider, a multi-objective RL (MORL) framework that trains a single diffusion model to approximate the entire Pareto front. By training the model with continuously varying preference weights as a conditioning signal, we enable users to navigate optimal trade-offs at inference time without retraining or maintaining multiple checkpoints. We evaluate ParetoSlider across three state-of-the-art flow-matching backbones: SD3.5, FluxKontext, and LTX-2. Our single preference-conditioned model matches or exceeds the performance of baselines trained separately for fixed reward trade-offs, while uniquely providing fine-grained control over competing generative goals.
Self-Evaluation Unlocks Any-Step Text-to-Image Generation
Dec 26, 2025We introduce the Self-Evaluating Model (Self-E), a novel, from-scratch training approach for text-to-image generation that supports any-step inference. Self-E learns from data similarly to a Flow Matching model, while simultaneously employing a novel self-evaluation mechanism: it evaluates its own generated samples using its current score estimates, effectively serving as a dynamic self-teacher. Unlike traditional diffusion or flow models, it does not rely solely on local supervision, which typically necessitates many inference steps. Unlike distillation-based approaches, it does not require a pretrained teacher. This combination of instantaneous local learning and self-driven global matching bridges the gap between the two paradigms, enabling the training of a high-quality text-to-image model from scratch that excels even at very low step counts. Extensive experiments on large-scale text-to-image benchmarks show that Self-E not only excels in few-step generation, but is also competitive with state-of-the-art Flow Matching models at 50 steps. We further find that its performance improves monotonically as inference steps increase, enabling both ultra-fast few-step generation and high-quality long-trajectory sampling within a single unified model. To our knowledge, Self-E is the first from-scratch, any-step text-to-image model, offering a unified framework for efficient and scalable generation.
Learning an Image Editing Model without Image Editing Pairs
Oct 16, 2025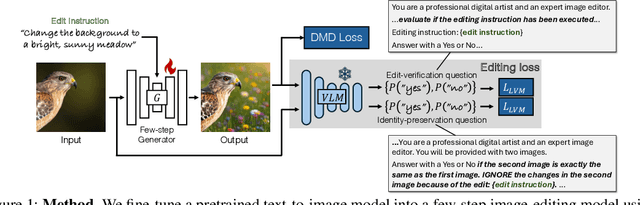
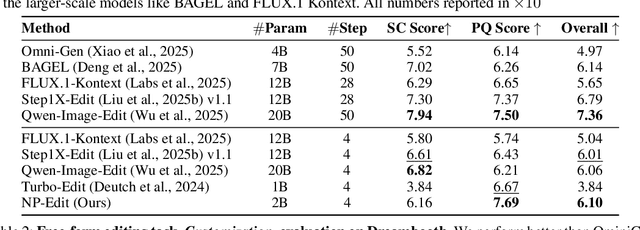

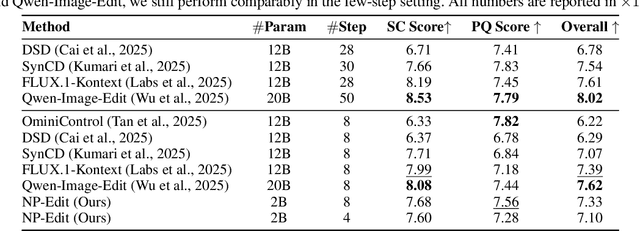
Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-language models (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.
Long-Context State-Space Video World Models
May 26, 2025Video diffusion models have recently shown promise for world modeling through autoregressive frame prediction conditioned on actions. However, they struggle to maintain long-term memory due to the high computational cost associated with processing extended sequences in attention layers. To overcome this limitation, we propose a novel architecture leveraging state-space models (SSMs) to extend temporal memory without compromising computational efficiency. Unlike previous approaches that retrofit SSMs for non-causal vision tasks, our method fully exploits the inherent advantages of SSMs in causal sequence modeling. Central to our design is a block-wise SSM scanning scheme, which strategically trades off spatial consistency for extended temporal memory, combined with dense local attention to ensure coherence between consecutive frames. We evaluate the long-term memory capabilities of our model through spatial retrieval and reasoning tasks over extended horizons. Experiments on Memory Maze and Minecraft datasets demonstrate that our approach surpasses baselines in preserving long-range memory, while maintaining practical inference speeds suitable for interactive applications.
Layer- and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion Transformers
Dec 22, 2024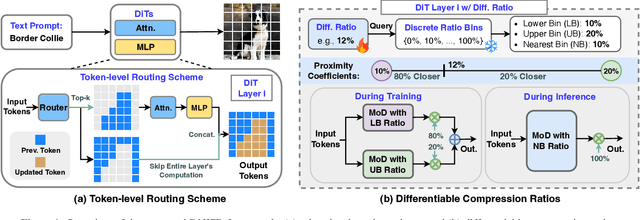



Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One key efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffRatio-MoD, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in Mixture-of-Depths (MoD) efficient DiT models. Specifically, DiffRatio-MoD integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is jointly fine-tuned with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer's computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on both text-to-image and inpainting tasks show that DiffRatio-MoD effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.
Masked Extended Attention for Zero-Shot Virtual Try-On In The Wild
Jun 21, 2024Virtual Try-On (VTON) is a highly active line of research, with increasing demand. It aims to replace a piece of garment in an image with one from another, while preserving person and garment characteristics as well as image fidelity. Current literature takes a supervised approach for the task, impairing generalization and imposing heavy computation. In this paper, we present a novel zero-shot training-free method for inpainting a clothing garment by reference. Our approach employs the prior of a diffusion model with no additional training, fully leveraging its native generalization capabilities. The method employs extended attention to transfer image information from reference to target images, overcoming two significant challenges. We first initially warp the reference garment over the target human using deep features, alleviating "texture sticking". We then leverage the extended attention mechanism with careful masking, eliminating leakage of reference background and unwanted influence. Through a user study, qualitative, and quantitative comparison to state-of-the-art approaches, we demonstrate superior image quality and garment preservation compared unseen clothing pieces or human figures.
Lazy Diffusion Transformer for Interactive Image Editing
Apr 18, 2024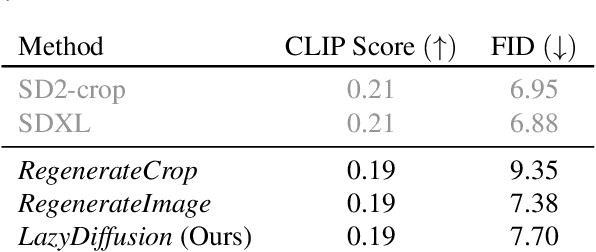

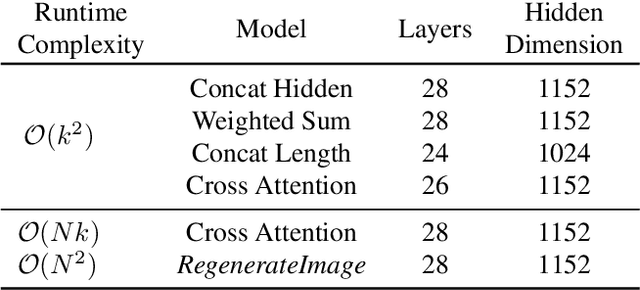

We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a "lazy" fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder's runtime scales with the mask size, which is typically small, while our encoder introduces negligible overhead. We demonstrate that our approach is competitive with state-of-the-art inpainting methods in terms of quality and fidelity while providing a 10x speedup for typical user interactions, where the editing mask represents 10% of the image.
Facial Reenactment Through a Personalized Generator
Jul 12, 2023



In recent years, the role of image generative models in facial reenactment has been steadily increasing. Such models are usually subject-agnostic and trained on domain-wide datasets. The appearance of the reenacted individual is learned from a single image, and hence, the entire breadth of the individual's appearance is not entirely captured, leading these methods to resort to unfaithful hallucination. Thanks to recent advancements, it is now possible to train a personalized generative model tailored specifically to a given individual. In this paper, we propose a novel method for facial reenactment using a personalized generator. We train the generator using frames from a short, yet varied, self-scan video captured using a simple commodity camera. Images synthesized by the personalized generator are guaranteed to preserve identity. The premise of our work is that the task of reenactment is thus reduced to accurately mimicking head poses and expressions. To this end, we locate the desired frames in the latent space of the personalized generator using carefully designed latent optimization. Through extensive evaluation, we demonstrate state-of-the-art performance for facial reenactment. Furthermore, we show that since our reenactment takes place in a semantic latent space, it can be semantically edited and stylized in post-processing.
Domain Expansion of Image Generators
Jan 12, 2023Can one inject new concepts into an already trained generative model, while respecting its existing structure and knowledge? We propose a new task - domain expansion - to address this. Given a pretrained generator and novel (but related) domains, we expand the generator to jointly model all domains, old and new, harmoniously. First, we note the generator contains a meaningful, pretrained latent space. Is it possible to minimally perturb this hard-earned representation, while maximally representing the new domains? Interestingly, we find that the latent space offers unused, "dormant" directions, which do not affect the output. This provides an opportunity: By "repurposing" these directions, we can represent new domains without perturbing the original representation. In fact, we find that pretrained generators have the capacity to add several - even hundreds - of new domains! Using our expansion method, one "expanded" model can supersede numerous domain-specific models, without expanding the model size. Additionally, a single expanded generator natively supports smooth transitions between domains, as well as composition of domains. Code and project page available at https://yotamnitzan.github.io/domain-expansion/.
MyStyle: A Personalized Generative Prior
Mar 31, 2022
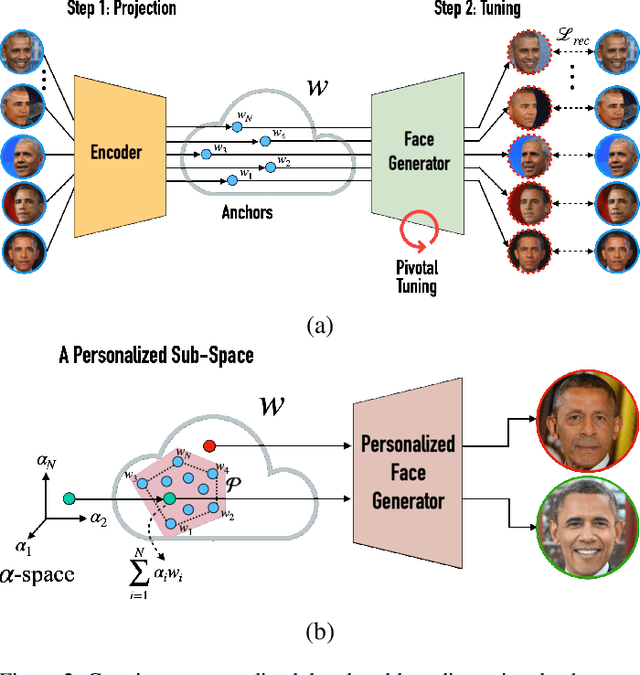
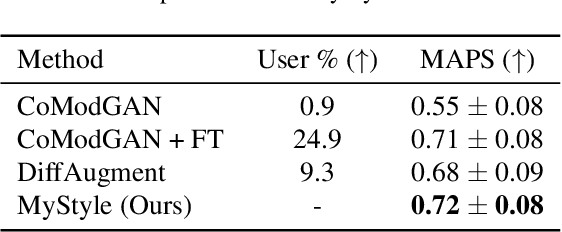

We introduce MyStyle, a personalized deep generative prior trained with a few shots of an individual. MyStyle allows to reconstruct, enhance and edit images of a specific person, such that the output is faithful to the person's key facial characteristics. Given a small reference set of portrait images of a person (~100), we tune the weights of a pretrained StyleGAN face generator to form a local, low-dimensional, personalized manifold in the latent space. We show that this manifold constitutes a personalized region that spans latent codes associated with diverse portrait images of the individual. Moreover, we demonstrate that we obtain a personalized generative prior, and propose a unified approach to apply it to various ill-posed image enhancement problems, such as inpainting and super-resolution, as well as semantic editing. Using the personalized generative prior we obtain outputs that exhibit high-fidelity to the input images and are also faithful to the key facial characteristics of the individual in the reference set. We demonstrate our method with fair-use images of numerous widely recognizable individuals for whom we have the prior knowledge for a qualitative evaluation of the expected outcome. We evaluate our approach against few-shots baselines and show that our personalized prior, quantitatively and qualitatively, outperforms state-of-the-art alternatives.