 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazy Diffusion Transformer for Interactive Image Editing
Paper and Code
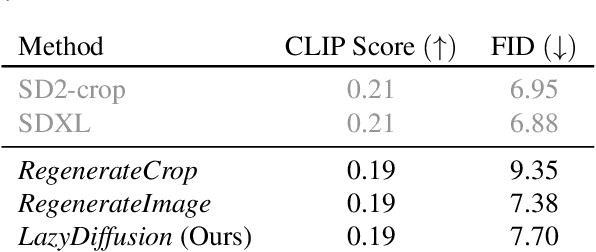

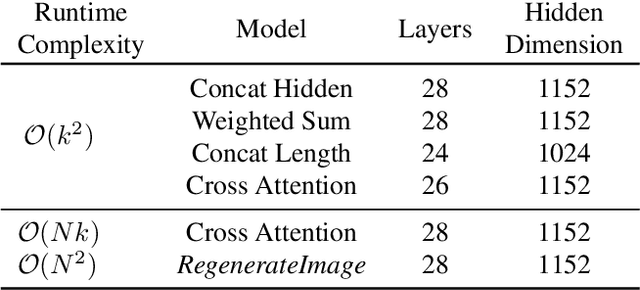

We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a "lazy" fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder's runtime scales with the mask size, which is typically small, while our encoder introduces negligible overhead. We demonstrate that our approach is competitive with state-of-the-art inpainting methods in terms of quality and fidelity while providing a 10x speedup for typical user interactions, where the editing mask represents 10% of the image.