 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating an Image From 1,000 Words: Enhancing Text-to-Image With Structured Captions
Nov 10, 2025



Text-to-image models have rapidly evolved from casual creative tools to professional-grade systems, achieving unprecedented levels of image quality and realism. Yet, most models are trained to map short prompts into detailed images, creating a gap between sparse textual input and rich visual outputs. This mismatch reduces controllability, as models often fill in missing details arbitrarily, biasing toward average user preferences and limiting precision for professional use. We address this limitation by training the first open-source text-to-image model on long structured captions, where every training sample is annotated with the same set of fine-grained attributes. This design maximizes expressive coverage and enables disentangled control over visual factors. To process long captions efficiently, we propose DimFusion, a fusion mechanism that integrates intermediate tokens from a lightweight LLM without increasing token length. We also introduce the Text-as-a-Bottleneck Reconstruction (TaBR) evaluation protocol. By assessing how well real images can be reconstructed through a captioning-generation loop, TaBR directly measures controllability and expressiveness, even for very long captions where existing evaluation methods fail. Finally, we demonstrate our contributions by training the large-scale model FIBO, achieving state-of-the-art prompt alignment among open-source models. Model weights are publicly available at https://huggingface.co/briaai/FIBO
Null-text Inversion for Editing Real Images using Guided Diffusion Models
Nov 17, 2022



Recent text-guided diffusion models provide powerful image generation capabilities. Currently, a massive effort is given to enable the modification of these images using text only as means to offer intuitive and versatile editing. To edit a real image using these state-of-the-art tools, one must first invert the image with a meaningful text prompt into the pretrained model's domain. In this paper, we introduce an accurate inversion technique and thus facilitate an intuitive text-based modification of the image. Our proposed inversion consists of two novel key components: (i) Pivotal inversion for diffusion models. While current methods aim at mapping random noise samples to a single input image, we use a single pivotal noise vector for each timestamp and optimize around it. We demonstrate that a direct inversion is inadequate on its own, but does provide a good anchor for our optimization. (ii) NULL-text optimization, where we only modify the unconditional textual embedding that is used for classifier-free guidance, rather than the input text embedding. This allows for keeping both the model weights and the conditional embedding intact and hence enables applying prompt-based editing while avoiding the cumbersome tuning of the model's weights. Our Null-text inversion, based on the publicly available Stable Diffusion model, is extensively evaluated on a variety of images and prompt editing, showing high-fidelity editing of real images.
Text-Only Training for Image Captioning using Noise-Injected CLIP
Nov 01, 2022We consider the task of image-captioning using only the CLIP model and additional text data at training time, and no additional captioned images. Our approach relies on the fact that CLIP is trained to make visual and textual embeddings similar. Therefore, we only need to learn how to translate CLIP textual embeddings back into text, and we can learn how to do this by learning a decoder for the frozen CLIP text encoder using only text. We argue that this intuition is "almost correct" because of a gap between the embedding spaces, and propose to rectify this via noise injection during training. We demonstrate the effectiveness of our approach by showing SOTA zero-shot image captioning across four benchmarks, including style transfer. Code, data, and models are available on GitHub.
Prompt-to-Prompt Image Editing with Cross Attention Control
Aug 02, 2022

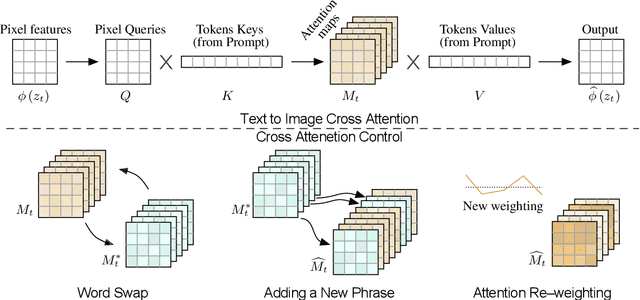
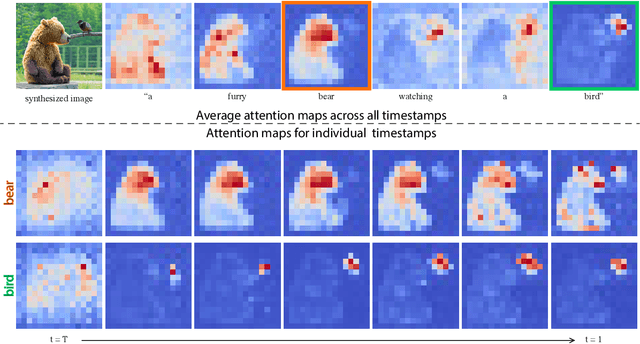
Recent large-scale text-driven synthesis models have attracted much attention thanks to their remarkable capabilities of generating highly diverse images that follow given text prompts. Such text-based synthesis methods are particularly appealing to humans who are used to verbally describe their intent. Therefore, it is only natural to extend the text-driven image synthesis to text-driven image editing. Editing is challenging for these generative models, since an innate property of an editing technique is to preserve most of the original image, while in the text-based models, even a small modification of the text prompt often leads to a completely different outcome. State-of-the-art methods mitigate this by requiring the users to provide a spatial mask to localize the edit, hence, ignoring the original structure and content within the masked region. In this paper, we pursue an intuitive prompt-to-prompt editing framework, where the edits are controlled by text only. To this end, we analyze a text-conditioned model in depth and observe that the cross-attention layers are the key to controlling the relation between the spatial layout of the image to each word in the prompt. With this observation, we present several applications which monitor the image synthesis by editing the textual prompt only. This includes localized editing by replacing a word, global editing by adding a specification, and even delicately controlling the extent to which a word is reflected in the image. We present our results over diverse images and prompts, demonstrating high-quality synthesis and fidelity to the edited prompts.
State-of-the-Art in the Architecture, Methods and Applications of StyleGAN
Feb 28, 2022

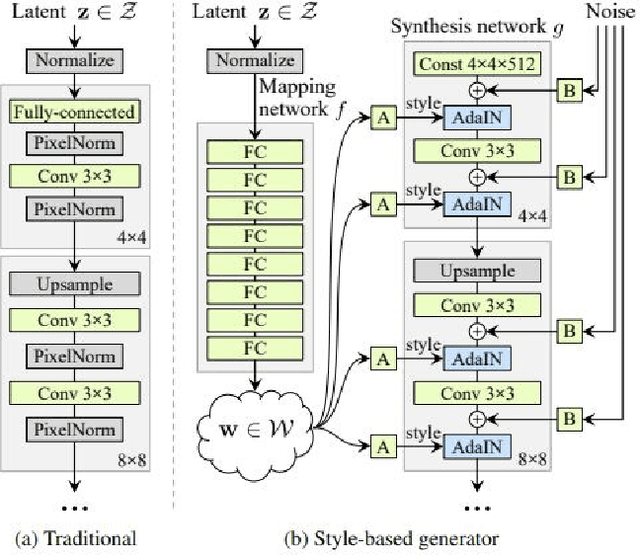
Generative Adversarial Networks (GANs) have established themselves as a prevalent approach to image synthesis. Of these, StyleGAN offers a fascinating case study, owing to its remarkable visual quality and an ability to support a large array of downstream tasks. This state-of-the-art report covers the StyleGAN architecture, and the ways it has been employed since its conception, while also analyzing its severe limitations. It aims to be of use for both newcomers, who wish to get a grasp of the field, and for more experienced readers that might benefit from seeing current research trends and existing tools laid out. Among StyleGAN's most interesting aspects is its learned latent space. Despite being learned with no supervision, it is surprisingly well-behaved and remarkably disentangled. Combined with StyleGAN's visual quality, these properties gave rise to unparalleled editing capabilities. However, the control offered by StyleGAN is inherently limited to the generator's learned distribution, and can only be applied to images generated by StyleGAN itself. Seeking to bring StyleGAN's latent control to real-world scenarios, the study of GAN inversion and latent space embedding has quickly gained in popularity. Meanwhile, this same study has helped shed light on the inner workings and limitations of StyleGAN. We map out StyleGAN's impressive story through these investigations, and discuss the details that have made StyleGAN the go-to generator. We further elaborate on the visual priors StyleGAN constructs, and discuss their use in downstream discriminative tasks. Looking forward, we point out StyleGAN's limitations and speculate on current trends and promising directions for future research, such as task and target specific fine-tuning.
Self-Distilled StyleGAN: Towards Generation from Internet Photos
Feb 24, 2022
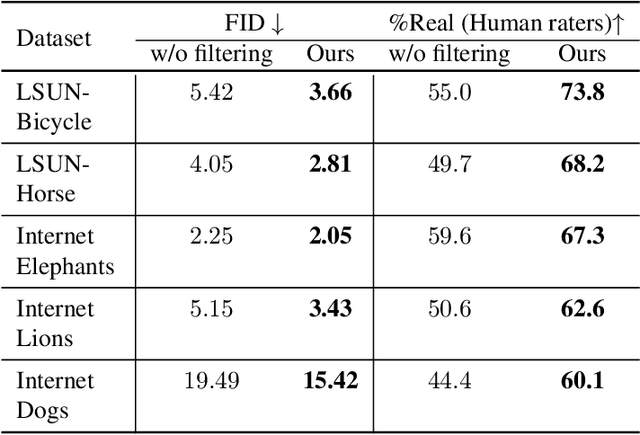
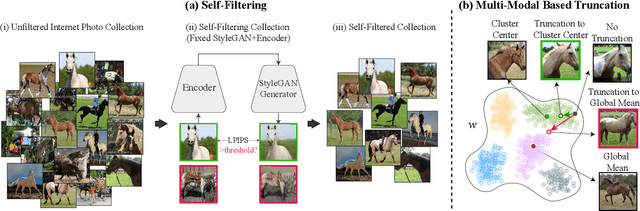
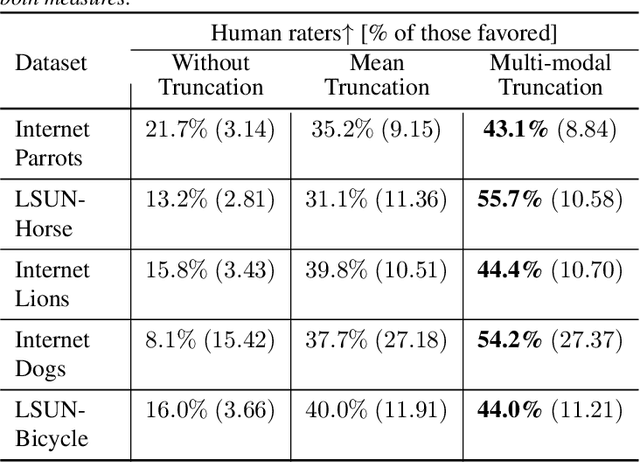
StyleGAN is known to produce high-fidelity images, while also offering unprecedented semantic editing. However, these fascinating abilities have been demonstrated only on a limited set of datasets, which are usually structurally aligned and well curated. In this paper, we show how StyleGAN can be adapted to work on raw uncurated images collected from the Internet. Such image collections impose two main challenges to StyleGAN: they contain many outlier images, and are characterized by a multi-modal distribution. Training StyleGAN on such raw image collections results in degraded image synthesis quality. To meet these challenges, we proposed a StyleGAN-based self-distillation approach, which consists of two main components: (i) A generative-based self-filtering of the dataset to eliminate outlier images, in order to generate an adequate training set, and (ii) Perceptual clustering of the generated images to detect the inherent data modalities, which are then employed to improve StyleGAN's "truncation trick" in the image synthesis process. The presented technique enables the generation of high-quality images, while minimizing the loss in diversity of the data. Through qualitative and quantitative evaluation, we demonstrate the power of our approach to new challenging and diverse domains collected from the Internet. New datasets and pre-trained models are available at https://self-distilled-stylegan.github.io/ .
Stitch it in Time: GAN-Based Facial Editing of Real Videos
Jan 21, 2022


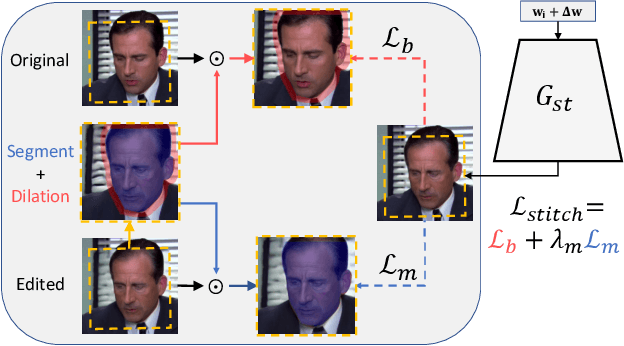
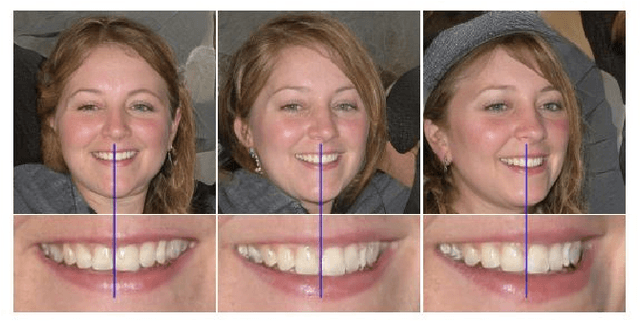
The ability of Generative Adversarial Networks to encode rich semantics within their latent space has been widely adopted for facial image editing. However, replicating their success with videos has proven challenging. Sets of high-quality facial videos are lacking, and working with videos introduces a fundamental barrier to overcome - temporal coherency. We propose that this barrier is largely artificial. The source video is already temporally coherent, and deviations from this state arise in part due to careless treatment of individual components in the editing pipeline. We leverage the natural alignment of StyleGAN and the tendency of neural networks to learn low frequency functions, and demonstrate that they provide a strongly consistent prior. We draw on these insights and propose a framework for semantic editing of faces in videos, demonstrating significant improvements over the current state-of-the-art. Our method produces meaningful face manipulations, maintains a higher degree of temporal consistency, and can be applied to challenging, high quality, talking head videos which current methods struggle with.
HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing
Nov 30, 2021
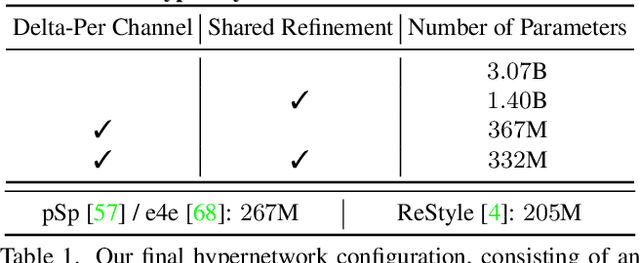
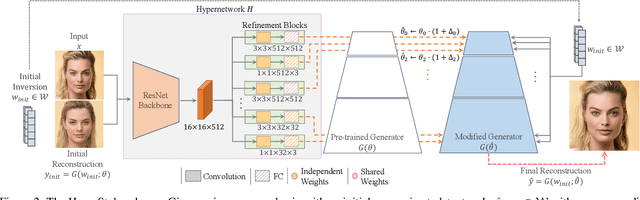
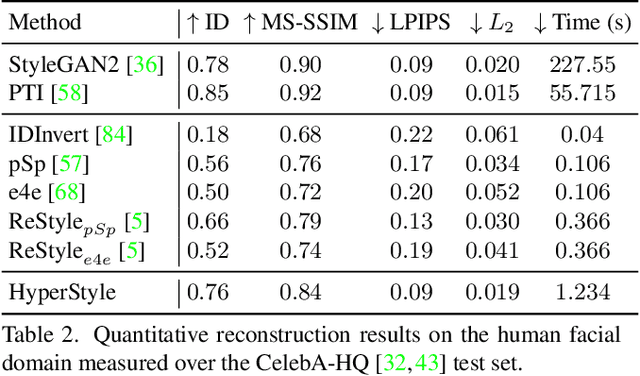
The inversion of real images into StyleGAN's latent space is a well-studied problem. Nevertheless, applying existing approaches to real-world scenarios remains an open challenge, due to an inherent trade-off between reconstruction and editability: latent space regions which can accurately represent real images typically suffer from degraded semantic control. Recent work proposes to mitigate this trade-off by fine-tuning the generator to add the target image to well-behaved, editable regions of the latent space. While promising, this fine-tuning scheme is impractical for prevalent use as it requires a lengthy training phase for each new image. In this work, we introduce this approach into the realm of encoder-based inversion. We propose HyperStyle, a hypernetwork that learns to modulate StyleGAN's weights to faithfully express a given image in editable regions of the latent space. A naive modulation approach would require training a hypernetwork with over three billion parameters. Through careful network design, we reduce this to be in line with existing encoders. HyperStyle yields reconstructions comparable to those of optimization techniques with the near real-time inference capabilities of encoders. Lastly, we demonstrate HyperStyle's effectiveness on several applications beyond the inversion task, including the editing of out-of-domain images which were never seen during training.
ClipCap: CLIP Prefix for Image Captioning
Nov 18, 2021



Image captioning is a fundamental task in vision-language understanding, where the model predicts a textual informative caption to a given input image. In this paper, we present a simple approach to address this task. We use CLIP encoding as a prefix to the caption, by employing a simple mapping network, and then fine-tunes a language model to generate the image captions. The recently proposed CLIP model contains rich semantic features which were trained with textual context, making it best for vision-language perception. Our key idea is that together with a pre-trained language model (GPT2), we obtain a wide understanding of both visual and textual data. Hence, our approach only requires rather quick training to produce a competent captioning model. Without additional annotations or pre-training, it efficiently generates meaningful captions for large-scale and diverse datasets. Surprisingly, our method works well even when only the mapping network is trained, while both CLIP and the language model remain frozen, allowing a lighter architecture with less trainable parameters. Through quantitative evaluation, we demonstrate our model achieves comparable results to state-of-the-art methods on the challenging Conceptual Captions and nocaps datasets, while it is simpler, faster, and lighter. Our code is available in https://github.com/rmokady/CLIP_prefix_caption.
JOKR: Joint Keypoint Representation for Unsupervised Cross-Domain Motion Retargeting
Jun 17, 2021


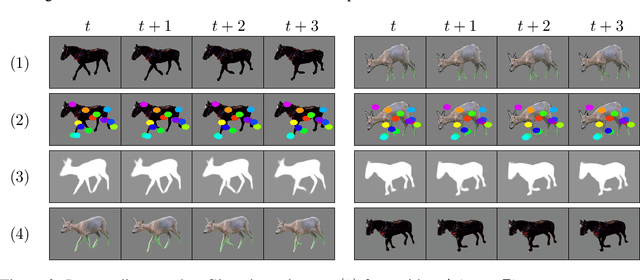
The task of unsupervised motion retargeting in videos has seen substantial advancements through the use of deep neural networks. While early works concentrated on specific object priors such as a human face or body, recent work considered the unsupervised case. When the source and target videos, however, are of different shapes, current methods fail. To alleviate this problem, we introduce JOKR - a JOint Keypoint Representation that captures the motion common to both the source and target videos, without requiring any object prior or data collection. By employing a domain confusion term, we enforce the unsupervised keypoint representations of both videos to be indistinguishable. This encourages disentanglement between the parts of the motion that are common to the two domains, and their distinctive appearance and motion, enabling the generation of videos that capture the motion of the one while depicting the style of the other. To enable cases where the objects are of different proportions or orientations, we apply a learned affine transformation between the JOKRs. This augments the representation to be affine invariant, and in practice broadens the variety of possible retargeting pairs. This geometry-driven representation enables further intuitive control, such as temporal coherence and manual editing. Through comprehensive experimentation, we demonstrate the applicability of our method to different challenging cross-domain video pairs. We evaluate our method both qualitatively and quantitatively, and demonstrate that our method handles various cross-domain scenarios, such as different animals, different flowers, and humans. We also demonstrate superior temporal coherency and visual quality compared to state-of-the-art alternatives, through statistical metrics and a user study. Source code and videos can be found at https://rmokady.github.io/JOKR/ .