 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStitch it in Time: GAN-Based Facial Editing of Real Videos
Jan 21, 2022


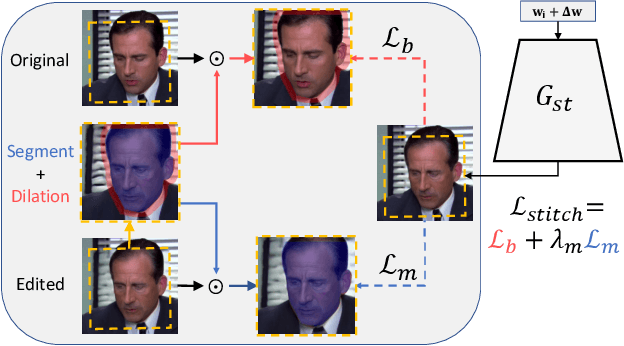
The ability of Generative Adversarial Networks to encode rich semantics within their latent space has been widely adopted for facial image editing. However, replicating their success with videos has proven challenging. Sets of high-quality facial videos are lacking, and working with videos introduces a fundamental barrier to overcome - temporal coherency. We propose that this barrier is largely artificial. The source video is already temporally coherent, and deviations from this state arise in part due to careless treatment of individual components in the editing pipeline. We leverage the natural alignment of StyleGAN and the tendency of neural networks to learn low frequency functions, and demonstrate that they provide a strongly consistent prior. We draw on these insights and propose a framework for semantic editing of faces in videos, demonstrating significant improvements over the current state-of-the-art. Our method produces meaningful face manipulations, maintains a higher degree of temporal consistency, and can be applied to challenging, high quality, talking head videos which current methods struggle with.
JOKR: Joint Keypoint Representation for Unsupervised Cross-Domain Motion Retargeting
Jun 17, 2021


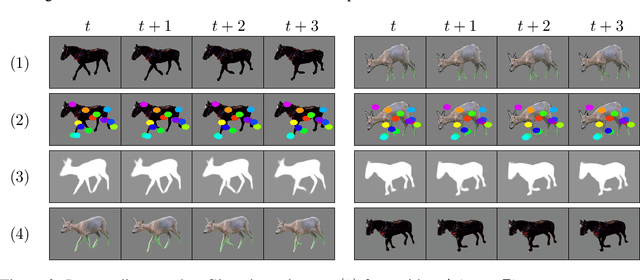
The task of unsupervised motion retargeting in videos has seen substantial advancements through the use of deep neural networks. While early works concentrated on specific object priors such as a human face or body, recent work considered the unsupervised case. When the source and target videos, however, are of different shapes, current methods fail. To alleviate this problem, we introduce JOKR - a JOint Keypoint Representation that captures the motion common to both the source and target videos, without requiring any object prior or data collection. By employing a domain confusion term, we enforce the unsupervised keypoint representations of both videos to be indistinguishable. This encourages disentanglement between the parts of the motion that are common to the two domains, and their distinctive appearance and motion, enabling the generation of videos that capture the motion of the one while depicting the style of the other. To enable cases where the objects are of different proportions or orientations, we apply a learned affine transformation between the JOKRs. This augments the representation to be affine invariant, and in practice broadens the variety of possible retargeting pairs. This geometry-driven representation enables further intuitive control, such as temporal coherence and manual editing. Through comprehensive experimentation, we demonstrate the applicability of our method to different challenging cross-domain video pairs. We evaluate our method both qualitatively and quantitatively, and demonstrate that our method handles various cross-domain scenarios, such as different animals, different flowers, and humans. We also demonstrate superior temporal coherency and visual quality compared to state-of-the-art alternatives, through statistical metrics and a user study. Source code and videos can be found at https://rmokady.github.io/JOKR/ .