 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStitch it in Time: GAN-Based Facial Editing of Real Videos
Paper and Code



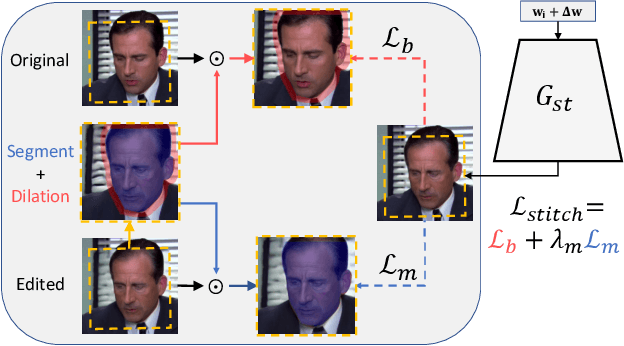
The ability of Generative Adversarial Networks to encode rich semantics within their latent space has been widely adopted for facial image editing. However, replicating their success with videos has proven challenging. Sets of high-quality facial videos are lacking, and working with videos introduces a fundamental barrier to overcome - temporal coherency. We propose that this barrier is largely artificial. The source video is already temporally coherent, and deviations from this state arise in part due to careless treatment of individual components in the editing pipeline. We leverage the natural alignment of StyleGAN and the tendency of neural networks to learn low frequency functions, and demonstrate that they provide a strongly consistent prior. We draw on these insights and propose a framework for semantic editing of faces in videos, demonstrating significant improvements over the current state-of-the-art. Our method produces meaningful face manipulations, maintains a higher degree of temporal consistency, and can be applied to challenging, high quality, talking head videos which current methods struggle with.