 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightLab: Controlling Light Sources in Images with Diffusion Models
May 14, 2025We present a simple, yet effective diffusion-based method for fine-grained, parametric control over light sources in an image. Existing relighting methods either rely on multiple input views to perform inverse rendering at inference time, or fail to provide explicit control over light changes. Our method fine-tunes a diffusion model on a small set of real raw photograph pairs, supplemented by synthetically rendered images at scale, to elicit its photorealistic prior for relighting. We leverage the linearity of light to synthesize image pairs depicting controlled light changes of either a target light source or ambient illumination. Using this data and an appropriate fine-tuning scheme, we train a model for precise illumination changes with explicit control over light intensity and color. Lastly, we show how our method can achieve compelling light editing results, and outperforms existing methods based on user preference.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
PALP: Prompt Aligned Personalization of Text-to-Image Models
Jan 11, 2024



Content creators often aim to create personalized images using personal subjects that go beyond the capabilities of conventional text-to-image models. Additionally, they may want the resulting image to encompass a specific location, style, ambiance, and more. Existing personalization methods may compromise personalization ability or the alignment to complex textual prompts. This trade-off can impede the fulfillment of user prompts and subject fidelity. We propose a new approach focusing on personalization methods for a \emph{single} prompt to address this issue. We term our approach prompt-aligned personalization. While this may seem restrictive, our method excels in improving text alignment, enabling the creation of images with complex and intricate prompts, which may pose a challenge for current techniques. In particular, our method keeps the personalized model aligned with a target prompt using an additional score distillation sampling term. We demonstrate the versatility of our method in multi- and single-shot settings and further show that it can compose multiple subjects or use inspiration from reference images, such as artworks. We compare our approach quantitatively and qualitatively with existing baselines and state-of-the-art techniques.
Style Aligned Image Generation via Shared Attention
Dec 04, 2023Large-scale Text-to-Image (T2I) models have rapidly gained prominence across creative fields, generating visually compelling outputs from textual prompts. However, controlling these models to ensure consistent style remains challenging, with existing methods necessitating fine-tuning and manual intervention to disentangle content and style. In this paper, we introduce StyleAligned, a novel technique designed to establish style alignment among a series of generated images. By employing minimal `attention sharing' during the diffusion process, our method maintains style consistency across images within T2I models. This approach allows for the creation of style-consistent images using a reference style through a straightforward inversion operation. Our method's evaluation across diverse styles and text prompts demonstrates high-quality synthesis and fidelity, underscoring its efficacy in achieving consistent style across various inputs.
AnyLens: A Generative Diffusion Model with Any Rendering Lens
Nov 29, 2023State-of-the-art diffusion models can generate highly realistic images based on various conditioning like text, segmentation, and depth. However, an essential aspect often overlooked is the specific camera geometry used during image capture. The influence of different optical systems on the final scene appearance is frequently overlooked. This study introduces a framework that intimately integrates a text-to-image diffusion model with the particular lens geometry used in image rendering. Our method is based on a per-pixel coordinate conditioning method, enabling the control over the rendering geometry. Notably, we demonstrate the manipulation of curvature properties, achieving diverse visual effects, such as fish-eye, panoramic views, and spherical texturing using a single diffusion model.
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models
Nov 27, 2023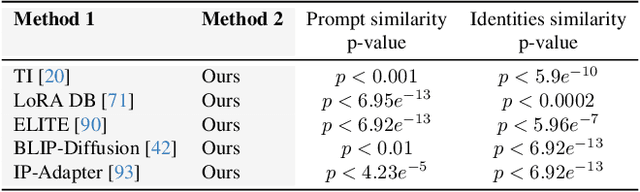


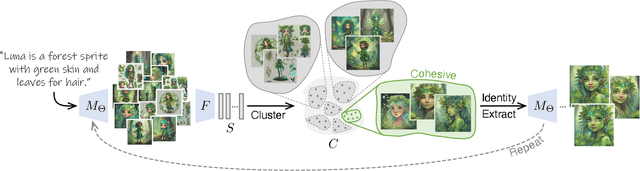
Recent advances in text-to-image generation models have unlocked vast potential for visual creativity. However, these models struggle with generation of consistent characters, a crucial aspect for numerous real-world applications such as story visualization, game development asset design, advertising, and more. Current methods typically rely on multiple pre-existing images of the target character or involve labor-intensive manual processes. In this work, we propose a fully automated solution for consistent character generation, with the sole input being a text prompt. We introduce an iterative procedure that, at each stage, identifies a coherent set of images sharing a similar identity and extracts a more consistent identity from this set. Our quantitative analysis demonstrates that our method strikes a better balance between prompt alignment and identity consistency compared to the baseline methods, and these findings are reinforced by a user study. To conclude, we showcase several practical applications of our approach. Project page is available at https://omriavrahami.com/the-chosen-one
SENS: Sketch-based Implicit Neural Shape Modeling
Jun 09, 2023We present SENS, a novel method for generating and editing 3D models from hand-drawn sketches, including those of an abstract nature. Our method allows users to quickly and easily sketch a shape, and then maps the sketch into the latent space of a part-aware neural implicit shape architecture. SENS analyzes the sketch and encodes its parts into ViT patch encoding, then feeds them into a transformer decoder that converts them to shape embeddings, suitable for editing 3D neural implicit shapes. SENS not only provides intuitive sketch-based generation and editing, but also excels in capturing the intent of the user's sketch to generate a variety of novel and expressive 3D shapes, even from abstract sketches. We demonstrate the effectiveness of our model compared to the state-of-the-art using objective metric evaluation criteria and a decisive user study, both indicating strong performance on sketches with a medium level of abstraction. Furthermore, we showcase its intuitive sketch-based shape editing capabilities.
Delta Denoising Score
Apr 14, 2023We introduce Delta Denoising Score (DDS), a novel scoring function for text-based image editing that guides minimal modifications of an input image towards the content described in a target prompt. DDS leverages the rich generative prior of text-to-image diffusion models and can be used as a loss term in an optimization problem to steer an image towards a desired direction dictated by a text. DDS utilizes the Score Distillation Sampling (SDS) mechanism for the purpose of image editing. We show that using only SDS often produces non-detailed and blurry outputs due to noisy gradients. To address this issue, DDS uses a prompt that matches the input image to identify and remove undesired erroneous directions of SDS. Our key premise is that SDS should be zero when calculated on pairs of matched prompts and images, meaning that if the score is non-zero, its gradients can be attributed to the erroneous component of SDS. Our analysis demonstrates the competence of DDS for text based image-to-image translation. We further show that DDS can be used to train an effective zero-shot image translation model. Experimental results indicate that DDS outperforms existing methods in terms of stability and quality, highlighting its potential for real-world applications in text-based image editing.
Word-As-Image for Semantic Typography
Mar 06, 2023



A word-as-image is a semantic typography technique where a word illustration presents a visualization of the meaning of the word, while also preserving its readability. We present a method to create word-as-image illustrations automatically. This task is highly challenging as it requires semantic understanding of the word and a creative idea of where and how to depict these semantics in a visually pleasing and legible manner. We rely on the remarkable ability of recent large pretrained language-vision models to distill textual concepts visually. We target simple, concise, black-and-white designs that convey the semantics clearly. We deliberately do not change the color or texture of the letters and do not use embellishments. Our method optimizes the outline of each letter to convey the desired concept, guided by a pretrained Stable Diffusion model. We incorporate additional loss terms to ensure the legibility of the text and the preservation of the style of the font. We show high quality and engaging results on numerous examples and compare to alternative techniques.
Null-text Inversion for Editing Real Images using Guided Diffusion Models
Nov 17, 2022



Recent text-guided diffusion models provide powerful image generation capabilities. Currently, a massive effort is given to enable the modification of these images using text only as means to offer intuitive and versatile editing. To edit a real image using these state-of-the-art tools, one must first invert the image with a meaningful text prompt into the pretrained model's domain. In this paper, we introduce an accurate inversion technique and thus facilitate an intuitive text-based modification of the image. Our proposed inversion consists of two novel key components: (i) Pivotal inversion for diffusion models. While current methods aim at mapping random noise samples to a single input image, we use a single pivotal noise vector for each timestamp and optimize around it. We demonstrate that a direct inversion is inadequate on its own, but does provide a good anchor for our optimization. (ii) NULL-text optimization, where we only modify the unconditional textual embedding that is used for classifier-free guidance, rather than the input text embedding. This allows for keeping both the model weights and the conditional embedding intact and hence enables applying prompt-based editing while avoiding the cumbersome tuning of the model's weights. Our Null-text inversion, based on the publicly available Stable Diffusion model, is extensively evaluated on a variety of images and prompt editing, showing high-fidelity editing of real images.