 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Extended Attention for Zero-Shot Virtual Try-On In The Wild
Jun 21, 2024Virtual Try-On (VTON) is a highly active line of research, with increasing demand. It aims to replace a piece of garment in an image with one from another, while preserving person and garment characteristics as well as image fidelity. Current literature takes a supervised approach for the task, impairing generalization and imposing heavy computation. In this paper, we present a novel zero-shot training-free method for inpainting a clothing garment by reference. Our approach employs the prior of a diffusion model with no additional training, fully leveraging its native generalization capabilities. The method employs extended attention to transfer image information from reference to target images, overcoming two significant challenges. We first initially warp the reference garment over the target human using deep features, alleviating "texture sticking". We then leverage the extended attention mechanism with careful masking, eliminating leakage of reference background and unwanted influence. Through a user study, qualitative, and quantitative comparison to state-of-the-art approaches, we demonstrate superior image quality and garment preservation compared unseen clothing pieces or human figures.
Leveraging in-domain supervision for unsupervised image-to-image translation tasks via multi-stream generators
Dec 30, 2021
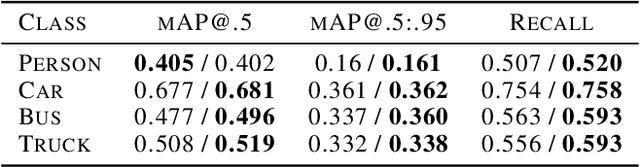
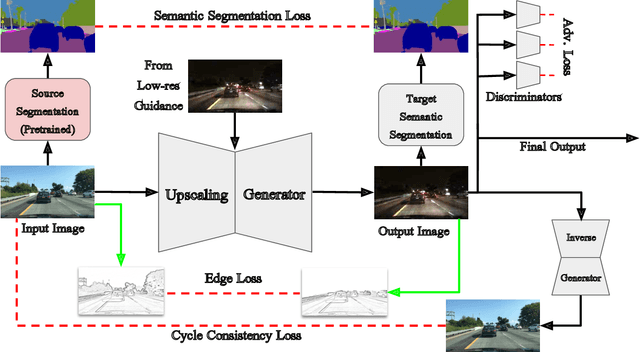
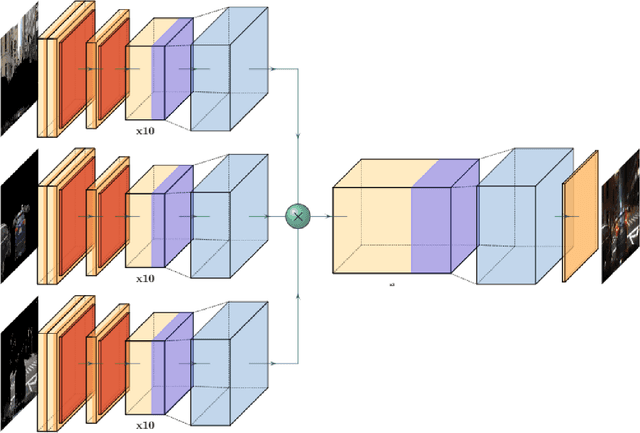
Supervision for image-to-image translation (I2I) tasks is hard to come by, but bears significant effect on the resulting quality. In this paper, we observe that for many Unsupervised I2I (UI2I) scenarios, one domain is more familiar than the other, and offers in-domain prior knowledge, such as semantic segmentation. We argue that for complex scenes, figuring out the semantic structure of the domain is hard, especially with no supervision, but is an important part of a successful I2I operation. We hence introduce two techniques to incorporate this invaluable in-domain prior knowledge for the benefit of translation quality: through a novel Multi-Stream generator architecture, and through a semantic segmentation-based regularization loss term. In essence, we propose splitting the input data according to semantic masks, explicitly guiding the network to different behavior for the different regions of the image. In addition, we propose training a semantic segmentation network along with the translation task, and to leverage this output as a loss term that improves robustness. We validate our approach on urban data, demonstrating superior quality in the challenging UI2I tasks of converting day images to night ones. In addition, we also demonstrate how reinforcing the target dataset with our augmented images improves the training of downstream tasks such as the classical detection one.
BalaGAN: Image Translation Between Imbalanced Domains via Cross-Modal Transfer
Oct 05, 2020


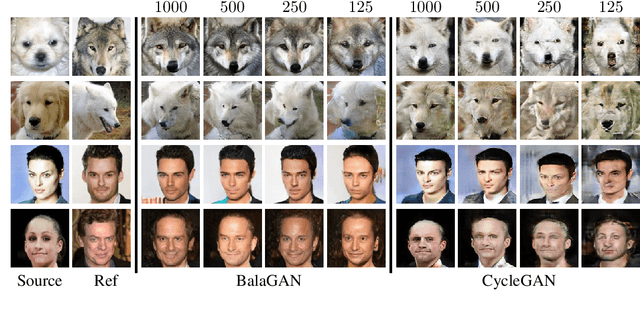
State-of-the-art image-to-image translation methods tend to struggle in an imbalanced domain setting, where one image domain lacks richness and diversity. We introduce a new unsupervised translation network, BalaGAN, specifically designed to tackle the domain imbalance problem. We leverage the latent modalities of the richer domain to turn the image-to-image translation problem, between two imbalanced domains, into a balanced, multi-class, and conditional translation problem, more resembling the style transfer setting. Specifically, we analyze the source domain and learn a decomposition of it into a set of latent modes or classes, without any supervision. This leaves us with a multitude of balanced cross-domain translation tasks, between all pairs of classes, including the target domain. During inference, the trained network takes as input a source image, as well as a reference or style image from one of the modes as a condition, and produces an image which resembles the source on the pixel-wise level, but shares the same mode as the reference. We show that employing modalities within the dataset improves the quality of the translated images, and that BalaGAN outperforms strong baselines of both unconditioned and style-transfer-based image-to-image translation methods, in terms of image quality and diversity.
Weakly Aligned Joint Cross-Modality Super Resolution
Apr 21, 2020
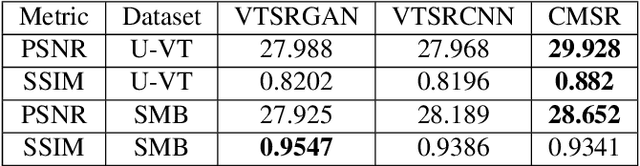


Non-visual imaging sensors are widely used in the industry for different purposes. Those sensors are more expensive than visual (RGB) sensors, and usually produce images with lower resolution. To this end, Cross-Modality Super-Resolution methods were introduced, where an RGB image of a high-resolution assists in increasing the resolution of the low-resolution modality. However, fusing images from different modalities is not a trivial task; the output must be artifact-free and remain loyal to the characteristics of the target modality. Moreover, the input images are never perfectly aligned, which results in further artifacts during the fusion process. We present CMSR, a deep network for Cross-Modality Super-Resolution, which unlike previous methods, is designed to deal with weakly aligned images. The network is trained on the two input images only, learns their internal statistics and correlations, and applies them to up-sample the target modality. CMSR contains an internal transformer that is trained on-the-fly together with the up-sampling process itself, without explicit supervision. We show that CMSR succeeds to increase the resolution of the input image, gaining valuable information from its RGB counterpart, yet in a conservative way, without introducing artifacts or irrelevant details.
Unsupervised Multi-Modal Image Registration via Geometry Preserving Image-to-Image Translation
Mar 18, 2020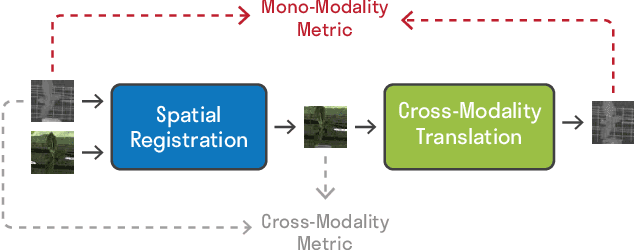
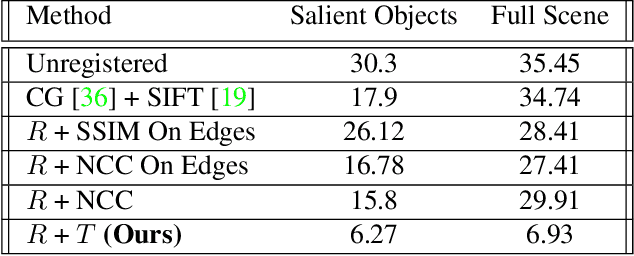
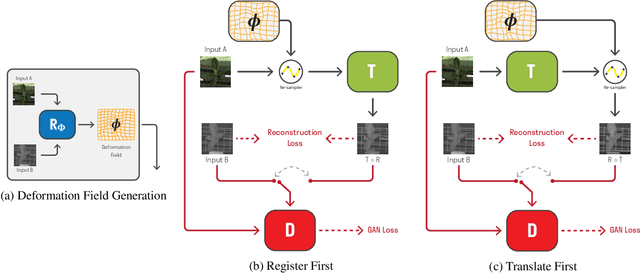
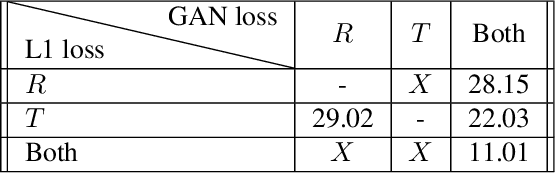
Many applications, such as autonomous driving, heavily rely on multi-modal data where spatial alignment between the modalities is required. Most multi-modal registration methods struggle computing the spatial correspondence between the images using prevalent cross-modality similarity measures. In this work, we bypass the difficulties of developing cross-modality similarity measures, by training an image-to-image translation network on the two input modalities. This learned translation allows training the registration network using simple and reliable mono-modality metrics. We perform multi-modal registration using two networks - a spatial transformation network and a translation network. We show that by encouraging our translation network to be geometry preserving, we manage to train an accurate spatial transformation network. Compared to state-of-the-art multi-modal methods our presented method is unsupervised, requiring no pairs of aligned modalities for training, and can be adapted to any pair of modalities. We evaluate our method quantitatively and qualitatively on commercial datasets, showing that it performs well on several modalities and achieves accurate alignment.
Image Resizing by Reconstruction from Deep Features
Apr 17, 2019

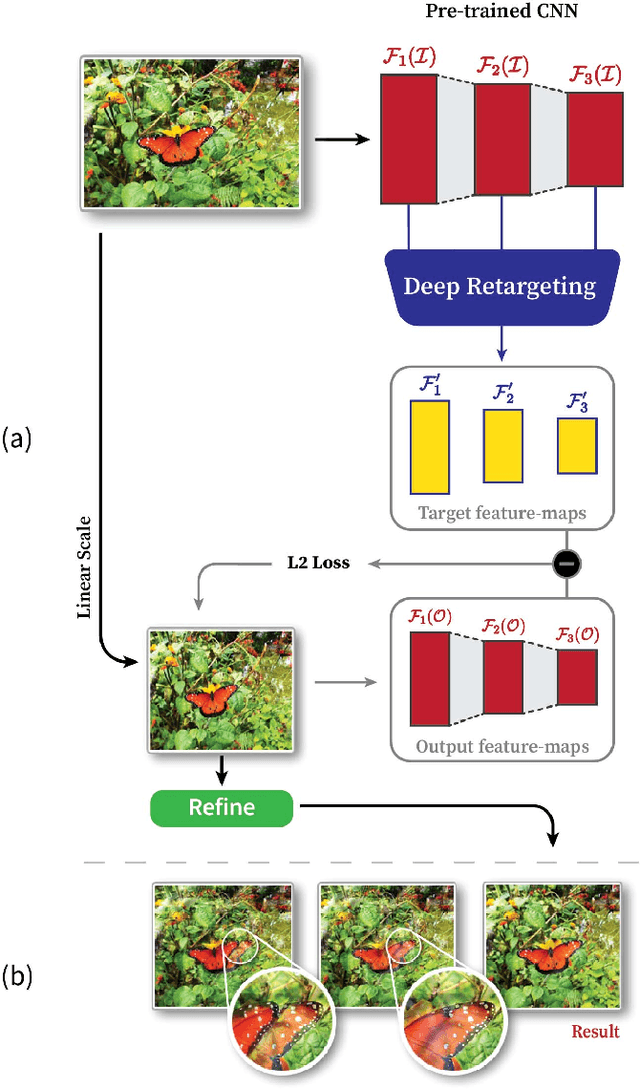

Traditional image resizing methods usually work in pixel space and use various saliency measures. The challenge is to adjust the image shape while trying to preserve important content. In this paper we perform image resizing in feature space where the deep layers of a neural network contain rich important semantic information. We directly adjust the image feature maps, extracted from a pre-trained classification network, and reconstruct the resized image using a neural-network based optimization. This novel approach leverages the hierarchical encoding of the network, and in particular, the high-level discriminative power of its deeper layers, that recognizes semantic objects and regions and allows maintaining their aspect ratio. Our use of reconstruction from deep features diminishes the artifacts introduced by image-space resizing operators. We evaluate our method on benchmarks, compare to alternative approaches, and demonstrate its strength on challenging images.
Implicit Pairs for Boosting Unpaired Image-to-Image Translation
Apr 15, 2019
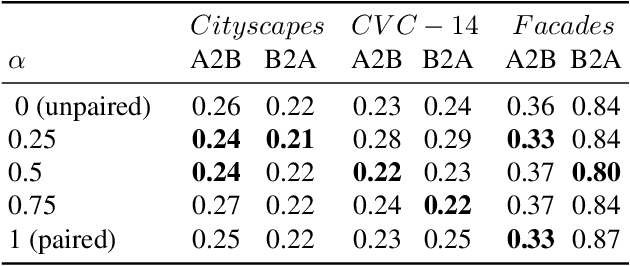
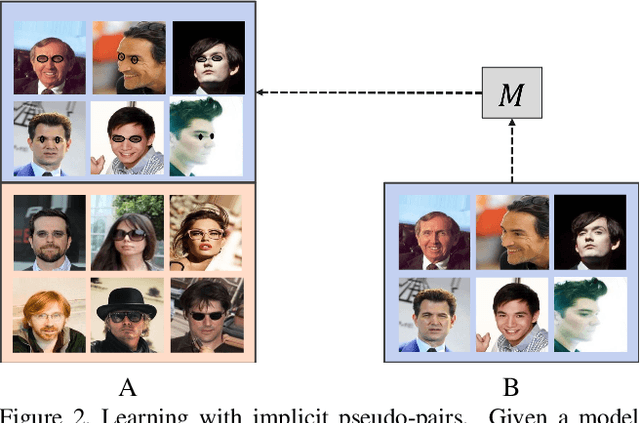
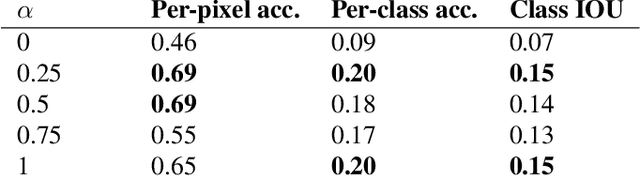
In image-to-image translation the goal is to learn a mapping from one image domain to another. Supervised approaches learn the mapping from paired samples. However, collecting large sets of image pairs is often prohibitively expensive or infeasible. In our work, we show that even training on the pairs implicitly, boosts the performance of unsupervised techniques by over 14% across several measurements. We illustrate that the injection of implicit pairs into unpaired sets strengthens the mapping between the two domains and improves the compatibility of their distributions. Furthermore, we show that for this purpose the implicit pairs can be pseudo-pairs, i.e., paired samples which only approximate a real pair. We demonstrate the effect of the approximated implicit samples on image-to-image translation problems, where such pseudo-pairs can be synthesized in one direction, but not in the other. We further show that pseudo-pairs are significantly more effective as implicit pairs in an unpaired setting, than directly using them explicitly in a paired setting.
Unsupervised Natural Image Patch Learning
Jun 28, 2018


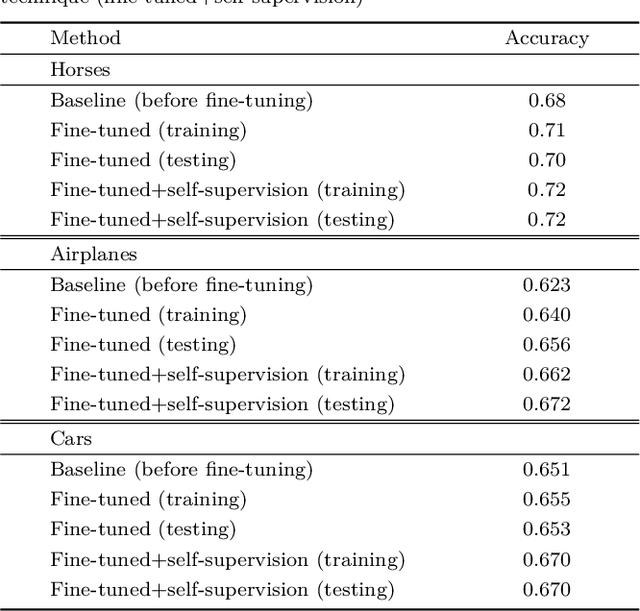
Learning a metric of natural image patches is an important tool for analyzing images. An efficient means is to train a deep network to map an image patch to a vector space, in which the Euclidean distance reflects patch similarity. Previous attempts learned such an embedding in a supervised manner, requiring the availability of many annotated images. In this paper, we present an unsupervised embedding of natural image patches, avoiding the need for annotated images. The key idea is that the similarity of two patches can be learned from the prevalence of their spatial proximity in natural images. Clearly, relying on this simple principle, many spatially nearby pairs are outliers, however, as we show, the outliers do not harm the convergence of the metric learning. We show that our unsupervised embedding approach is more effective than a supervised one or one that uses deep patch representations. Moreover, we show that it naturally leads itself to an efficient self-supervised domain adaptation technique onto a target domain that contains a common foreground object.