 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multi-Modal Image Registration via Geometry Preserving Image-to-Image Translation
Mar 18, 2020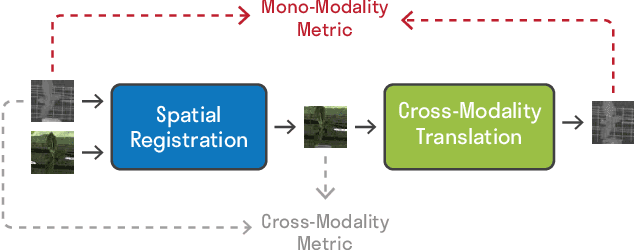
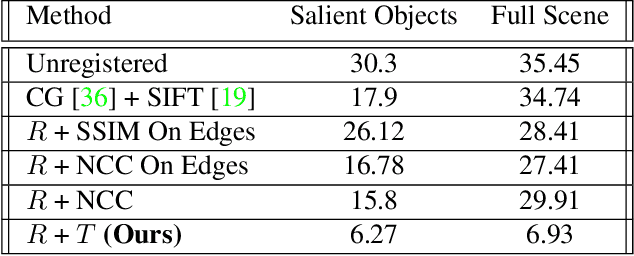
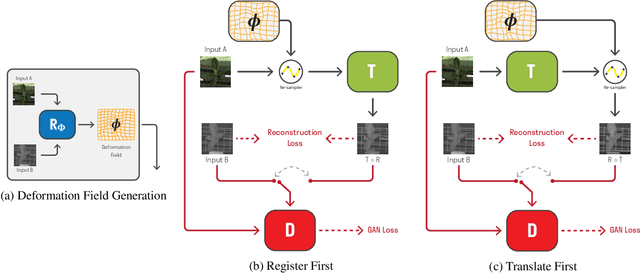
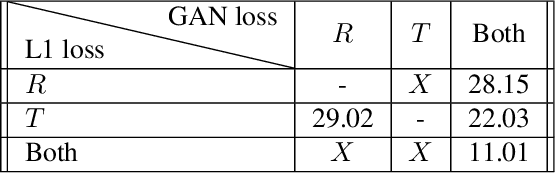
Many applications, such as autonomous driving, heavily rely on multi-modal data where spatial alignment between the modalities is required. Most multi-modal registration methods struggle computing the spatial correspondence between the images using prevalent cross-modality similarity measures. In this work, we bypass the difficulties of developing cross-modality similarity measures, by training an image-to-image translation network on the two input modalities. This learned translation allows training the registration network using simple and reliable mono-modality metrics. We perform multi-modal registration using two networks - a spatial transformation network and a translation network. We show that by encouraging our translation network to be geometry preserving, we manage to train an accurate spatial transformation network. Compared to state-of-the-art multi-modal methods our presented method is unsupervised, requiring no pairs of aligned modalities for training, and can be adapted to any pair of modalities. We evaluate our method quantitatively and qualitatively on commercial datasets, showing that it performs well on several modalities and achieves accurate alignment.
Implicit Pairs for Boosting Unpaired Image-to-Image Translation
Apr 15, 2019
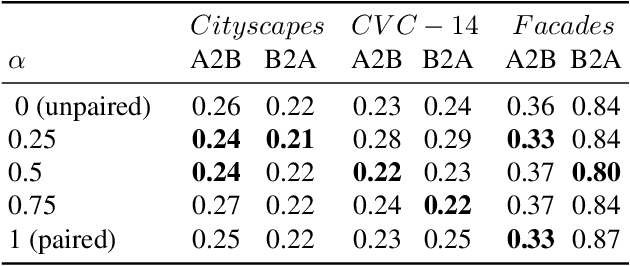
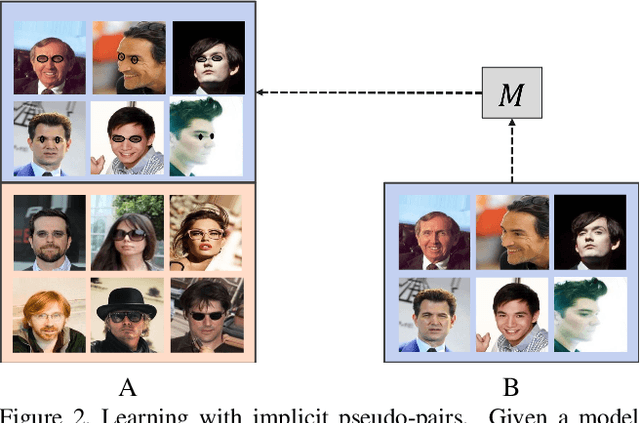
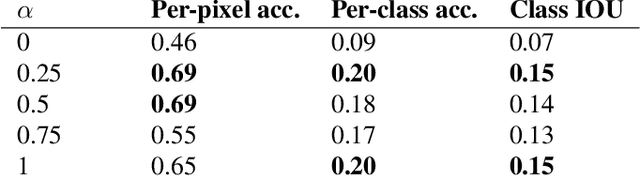
In image-to-image translation the goal is to learn a mapping from one image domain to another. Supervised approaches learn the mapping from paired samples. However, collecting large sets of image pairs is often prohibitively expensive or infeasible. In our work, we show that even training on the pairs implicitly, boosts the performance of unsupervised techniques by over 14% across several measurements. We illustrate that the injection of implicit pairs into unpaired sets strengthens the mapping between the two domains and improves the compatibility of their distributions. Furthermore, we show that for this purpose the implicit pairs can be pseudo-pairs, i.e., paired samples which only approximate a real pair. We demonstrate the effect of the approximated implicit samples on image-to-image translation problems, where such pseudo-pairs can be synthesized in one direction, but not in the other. We further show that pseudo-pairs are significantly more effective as implicit pairs in an unpaired setting, than directly using them explicitly in a paired setting.