 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInAugment: Improving Classifiers via Internal Augmentation
Apr 08, 2021

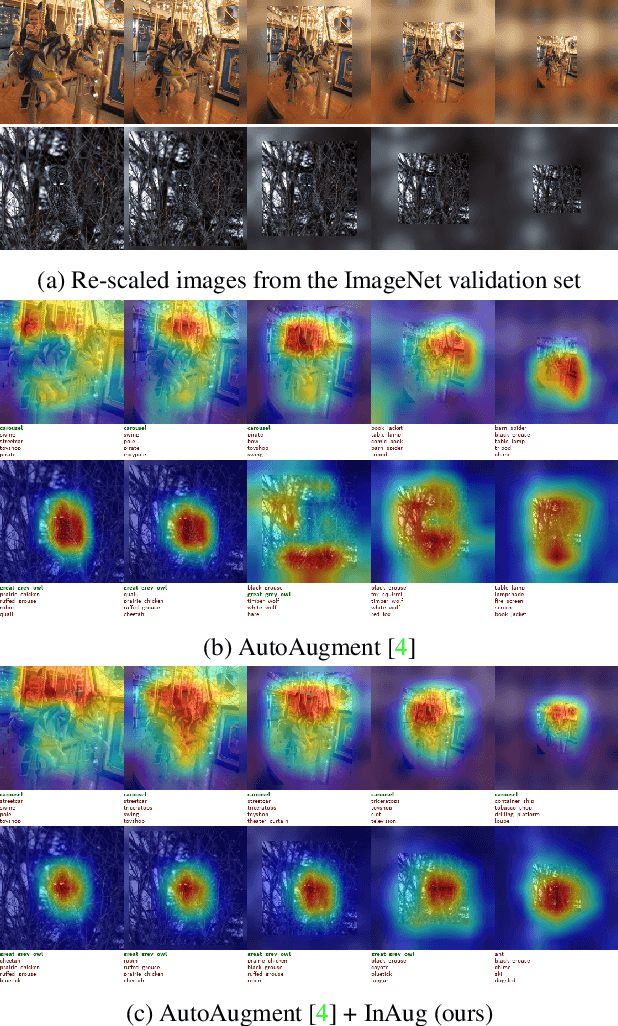

Image augmentation techniques apply transformation functions such as rotation, shearing, or color distortion on an input image. These augmentations were proven useful in improving neural networks' generalization ability. In this paper, we present a novel augmentation operation, InAugment, that exploits image internal statistics. The key idea is to copy patches from the image itself, apply augmentation operations on them, and paste them back at random positions on the same image. This method is simple and easy to implement and can be incorporated with existing augmentation techniques. We test InAugment on two popular datasets -- CIFAR and ImageNet. We show improvement over state-of-the-art augmentation techniques. Incorporating InAugment with Auto Augment yields a significant improvement over other augmentation techniques (e.g., +1% improvement over multiple architectures trained on the CIFAR dataset). We also demonstrate an increase for ResNet50 and EfficientNet-B3 top-1's accuracy on the ImageNet dataset compared to prior augmentation methods. Finally, our experiments suggest that training convolutional neural network using InAugment not only improves the model's accuracy and confidence but its performance on out-of-distribution images.
SWAGAN: A Style-based Wavelet-driven Generative Model
Feb 11, 2021

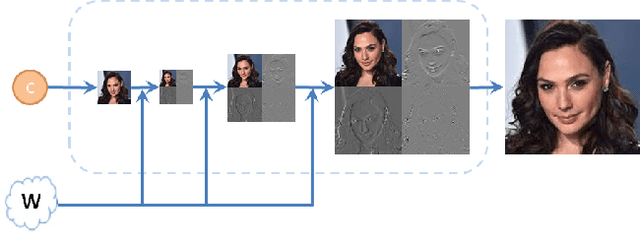

In recent years, considerable progress has been made in the visual quality of Generative Adversarial Networks (GANs). Even so, these networks still suffer from degradation in quality for high-frequency content, stemming from a spectrally biased architecture, and similarly unfavorable loss functions. To address this issue, we present a novel general-purpose Style and WAvelet based GAN (SWAGAN) that implements progressive generation in the frequency domain. SWAGAN incorporates wavelets throughout its generator and discriminator architectures, enforcing a frequency-aware latent representation at every step of the way. This approach yields enhancements in the visual quality of the generated images, and considerably increases computational performance. We demonstrate the advantage of our method by integrating it into the SyleGAN2 framework, and verifying that content generation in the wavelet domain leads to higher quality images with more realistic high-frequency content. Furthermore, we verify that our model's latent space retains the qualities that allow StyleGAN to serve as a basis for a multitude of editing tasks, and show that our frequency-aware approach also induces improved downstream visual quality.
SketchPatch: Sketch Stylization via Seamless Patch-level Synthesis
Sep 04, 2020
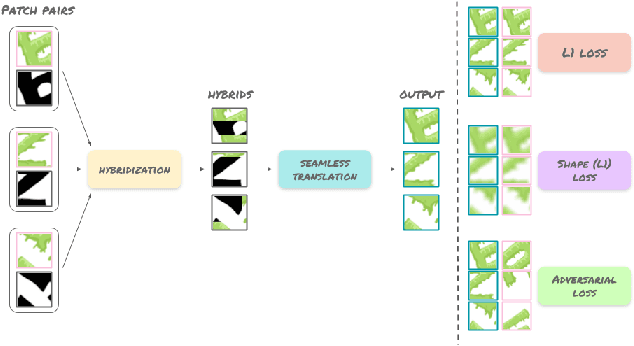
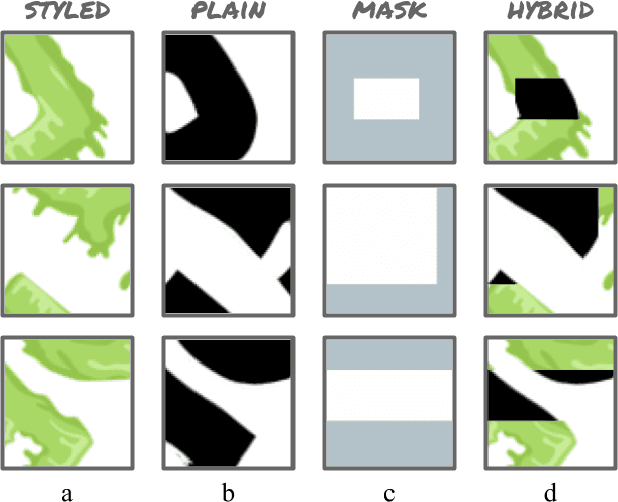
The paradigm of image-to-image translation is leveraged for the benefit of sketch stylization via transfer of geometric textural details. Lacking the necessary volumes of data for standard training of translation systems, we advocate for operation at the patch level, where a handful of stylized sketches provide ample mining potential for patches featuring basic geometric primitives. Operating at the patch level necessitates special consideration of full sketch translation, as individual translation of patches with no regard to neighbors is likely to produce visible seams and artifacts at patch borders. Aligned pairs of styled and plain primitives are combined to form input hybrids containing styled elements around the border and plain elements within, and given as input to a seamless translation (ST) generator, whose output patches are expected to reconstruct the fully styled patch. An adversarial addition promotes generalization and robustness to diverse geometries at inference time, forming a simple and effective system for arbitrary sketch stylization, as demonstrated upon a variety of styles and sketches.
MRGAN: Multi-Rooted 3D Shape Generation with Unsupervised Part Disentanglement
Jul 25, 2020


We present MRGAN, a multi-rooted adversarial network which generates part-disentangled 3D point-cloud shapes without part-based shape supervision. The network fuses multiple branches of tree-structured graph convolution layers which produce point clouds, with learnable constant inputs at the tree roots. Each branch learns to grow a different shape part, offering control over the shape generation at the part level. Our network encourages disentangled generation of semantic parts via two key ingredients: a root-mixing training strategy which helps decorrelate the different branches to facilitate disentanglement, and a set of loss terms designed with part disentanglement and shape semantics in mind. Of these, a novel convexity loss incentivizes the generation of parts that are more convex, as semantic parts tend to be. In addition, a root-dropping loss further ensures that each root seeds a single part, preventing the degeneration or over-growth of the point-producing branches. We evaluate the performance of our network on a number of 3D shape classes, and offer qualitative and quantitative comparisons to previous works and baseline approaches. We demonstrate the controllability offered by our part-disentangled generation through two applications for shape modeling: part mixing and individual part variation, without receiving segmented shapes as input.
Focus-and-Expand: Training Guidance Through Gradual Manipulation of Input Features
Jul 15, 2020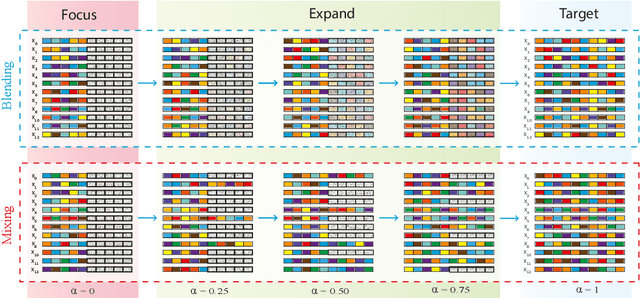
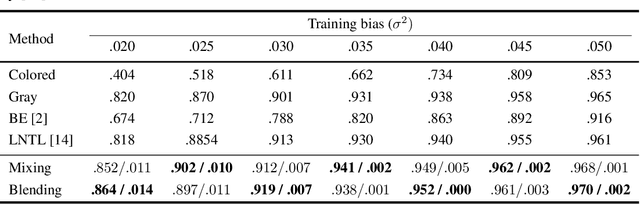

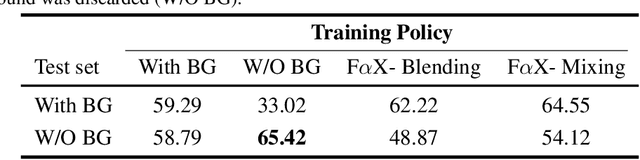
We present a simple and intuitive Focus-and-eXpand (\fax) method to guide the training process of a neural network towards a specific solution. Optimizing a neural network is a highly non-convex problem. Typically, the space of solutions is large, with numerous possible local minima, where reaching a specific minimum depends on many factors. In many cases, however, a solution which considers specific aspects, or features, of the input is desired. For example, in the presence of bias, a solution that disregards the biased feature is a more robust and accurate one. Drawing inspiration from Parameter Continuation methods, we propose steering the training process to consider specific features in the input more than others, through gradual shifts in the input domain. \fax extracts a subset of features from each input data-point, and exposes the learner to these features first, Focusing the solution on them. Then, by using a blending/mixing parameter $\alpha$ it gradually eXpands the learning process to include all features of the input. This process encourages the consideration of the desired features more than others. Though not restricted to this field, we quantitatively evaluate the effectiveness of our approach on various Computer Vision tasks, and achieve state-of-the-art bias removal, improvements to an established augmentation method, and two examples of improvements to image classification tasks. Through these few examples we demonstrate the impact this approach potentially carries for a wide variety of problems, which stand to gain from understanding the solution landscape.
Disentangling in Latent Space by Harnessing a Pretrained Generator
May 15, 2020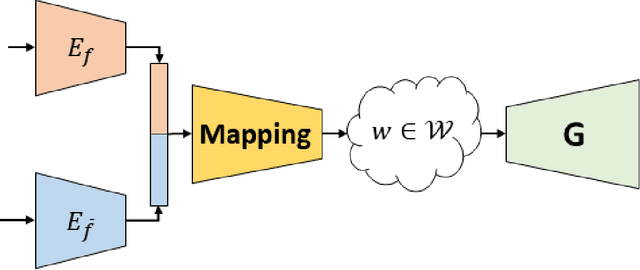


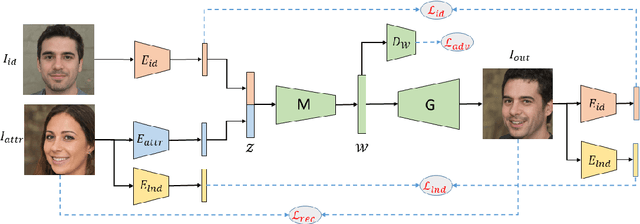
Learning disentangled representations of data is a fundamental problem in artificial intelligence. Specifically, disentangled latent representations allow generative models to control and compose the disentangled factors in the synthesis process. Current methods, however, require extensive supervision and training, or instead, noticeably compromise quality. In this paper, we present a method that learn show to represent data in a disentangled way, with minimal supervision, manifested solely using available pre-trained networks. Our key insight is to decouple the processes of disentanglement and synthesis, by employing a leading pre-trained unconditional image generator, such as StyleGAN. By learning to map into its latent space, we leverage both its state-of-the-art quality generative power, and its rich and expressive latent space, without the burden of training it.We demonstrate our approach on the complex and high dimensional domain of human heads. We evaluate our method qualitatively and quantitatively, and exhibit its success with de-identification operations and with temporal identity coherency in image sequences. Through this extensive experimentation, we show that our method successfully disentangles identity from other facial attributes, surpassing existing methods, even though they require more training and supervision.
Structural-analogy from a Single Image Pair
Apr 16, 2020
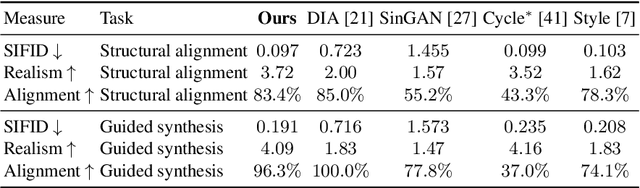
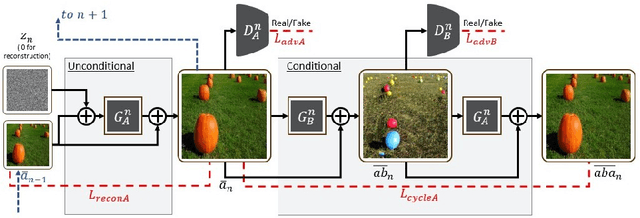

The task of unsupervised image-to-image translation has seen substantial advancements in recent years through the use of deep neural networks. Typically, the proposed solutions learn the characterizing distribution of two large, unpaired collections of images, and are able to alter the appearance of a given image, while keeping its geometry intact. In this paper, we explore the capabilities of neural networks to understand image structure given only a single pair of images, A and B. We seek to generate images that are structurally aligned: that is, to generate an image that keeps the appearance and style of B, but has a structural arrangement that corresponds to A. The key idea is to map between image patches at different scales. This enables controlling the granularity at which analogies are produced, which determines the conceptual distinction between style and content. In addition to structural alignment, our method can be used to generate high quality imagery in other conditional generation tasks utilizing images A and B only: guided image synthesis, style and texture transfer, text translation as well as video translation. Our code and additional results are available in https://github.com/rmokady/structural-analogy/.
Unsupervised Multi-Modal Image Registration via Geometry Preserving Image-to-Image Translation
Mar 18, 2020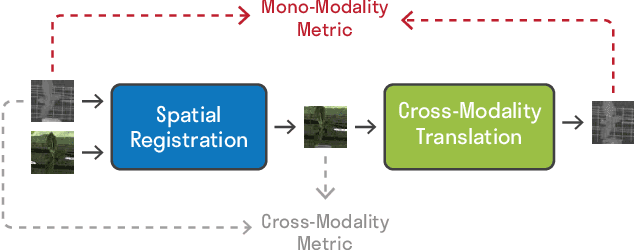
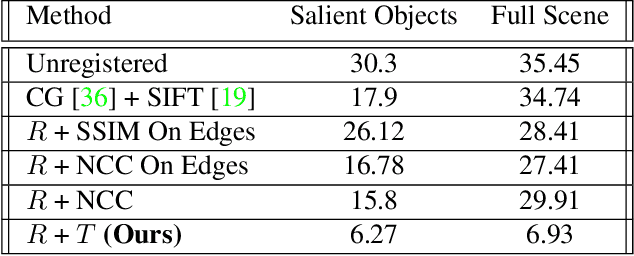
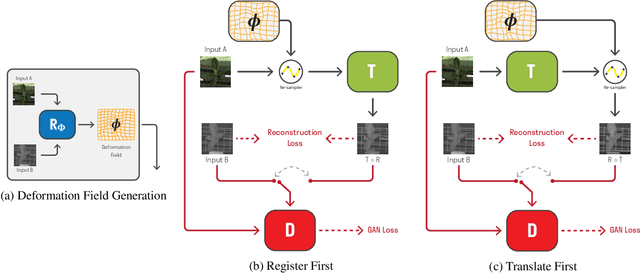
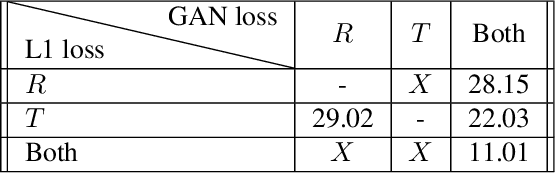
Many applications, such as autonomous driving, heavily rely on multi-modal data where spatial alignment between the modalities is required. Most multi-modal registration methods struggle computing the spatial correspondence between the images using prevalent cross-modality similarity measures. In this work, we bypass the difficulties of developing cross-modality similarity measures, by training an image-to-image translation network on the two input modalities. This learned translation allows training the registration network using simple and reliable mono-modality metrics. We perform multi-modal registration using two networks - a spatial transformation network and a translation network. We show that by encouraging our translation network to be geometry preserving, we manage to train an accurate spatial transformation network. Compared to state-of-the-art multi-modal methods our presented method is unsupervised, requiring no pairs of aligned modalities for training, and can be adapted to any pair of modalities. We evaluate our method quantitatively and qualitatively on commercial datasets, showing that it performs well on several modalities and achieves accurate alignment.
Mask Based Unsupervised Content Transfer
Jun 15, 2019

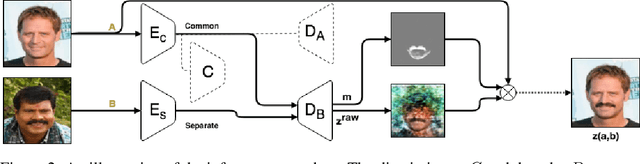

We consider the problem of translating, in an unsupervised manner, between two domains where one contains some additional information compared to the other. The proposed method disentangles the common and separate parts of these domains and, through the generation of a mask, focuses the attention of the underlying network to the desired augmentation alone, without wastefully reconstructing the entire target. This enables state-of-the-art quality and variety of content translation, as shown through extensive quantitative and qualitative evaluation. Furthermore, the novel mask-based formulation and regularization is accurate enough to achieve state-of-the-art performance in the realm of weakly supervised segmentation, where only class labels are given. To our knowledge, this is the first report that bridges the problems of domain disentanglement and weakly supervised segmentation. Our code is publicly available at https://github.com/rmokady/mbu-content-tansfer.