 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Alignment for Face De-pixelization
Sep 29, 2020
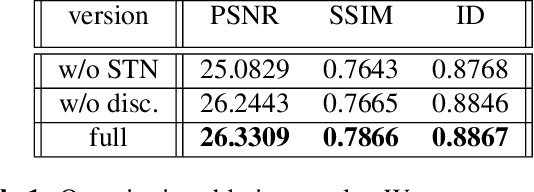
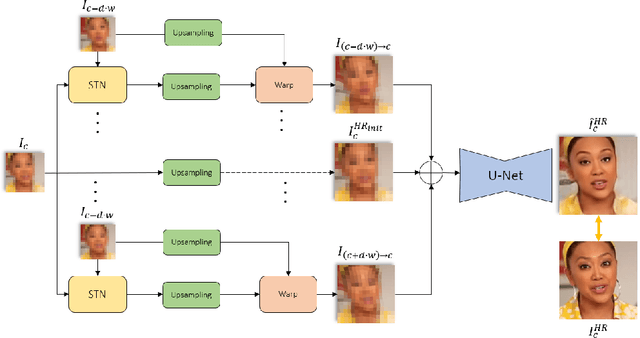

We present a simple method to reconstruct a high-resolution video from a face-video, where the identity of a person is obscured by pixelization. This concealment method is popular because the viewer can still perceive a human face figure and the overall head motion. However, we show in our experiments that a fairly good approximation of the original video can be reconstructed in a way that compromises anonymity. Our system exploits the simultaneous similarity and small disparity between close-by video frames depicting a human face, and employs a spatial transformation component that learns the alignment between the pixelated frames. Each frame, supported by its aligned surrounding frames, is first encoded, then decoded to a higher resolution. Reconstruction and perceptual losses promote adherence to the ground-truth, and an adversarial loss assists in maintaining domain faithfulness. There is no need for explicit temporal coherency loss as it is maintained implicitly by the alignment of neighboring frames and reconstruction. Although simple, our framework synthesizes high-quality face reconstructions, demonstrating that given the statistical prior of a human face, multiple aligned pixelated frames contain sufficient information to reconstruct a high-quality approximation of the original signal.
SketchPatch: Sketch Stylization via Seamless Patch-level Synthesis
Sep 04, 2020
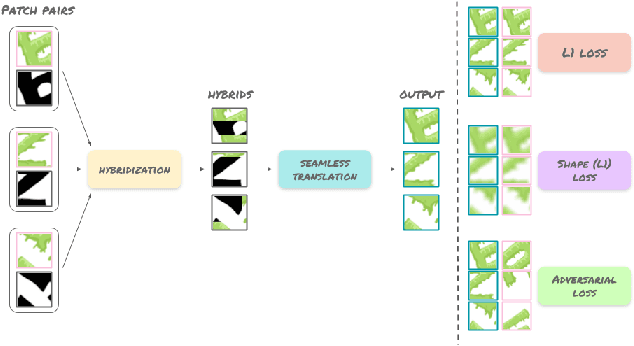
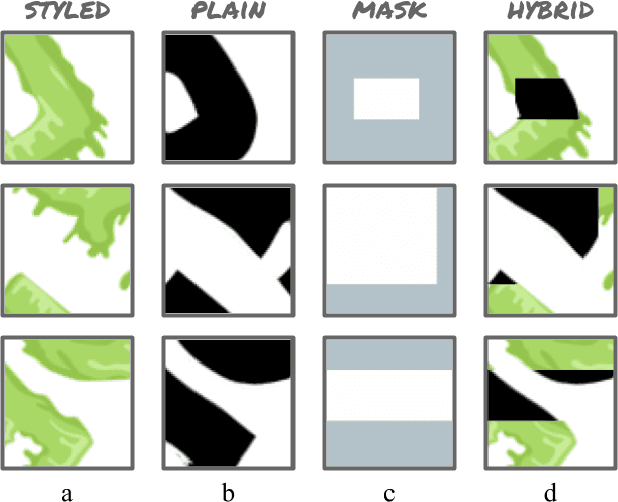
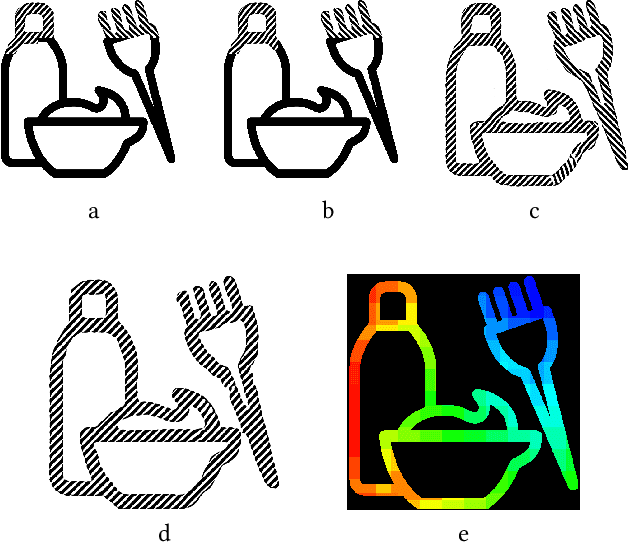
The paradigm of image-to-image translation is leveraged for the benefit of sketch stylization via transfer of geometric textural details. Lacking the necessary volumes of data for standard training of translation systems, we advocate for operation at the patch level, where a handful of stylized sketches provide ample mining potential for patches featuring basic geometric primitives. Operating at the patch level necessitates special consideration of full sketch translation, as individual translation of patches with no regard to neighbors is likely to produce visible seams and artifacts at patch borders. Aligned pairs of styled and plain primitives are combined to form input hybrids containing styled elements around the border and plain elements within, and given as input to a seamless translation (ST) generator, whose output patches are expected to reconstruct the fully styled patch. An adversarial addition promotes generalization and robustness to diverse geometries at inference time, forming a simple and effective system for arbitrary sketch stylization, as demonstrated upon a variety of styles and sketches.
Focus-and-Expand: Training Guidance Through Gradual Manipulation of Input Features
Jul 15, 2020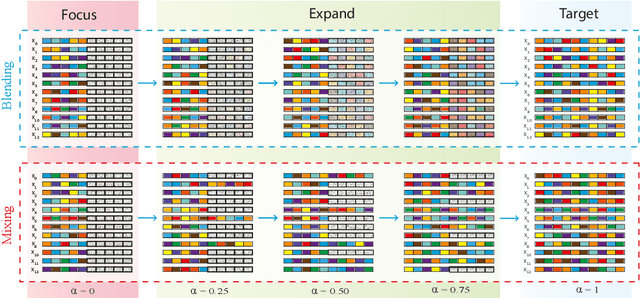
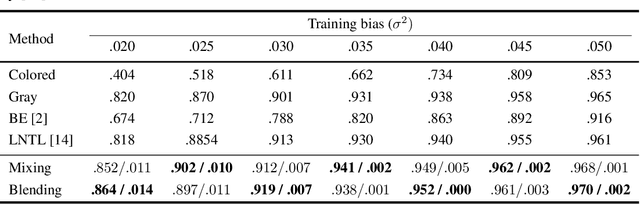

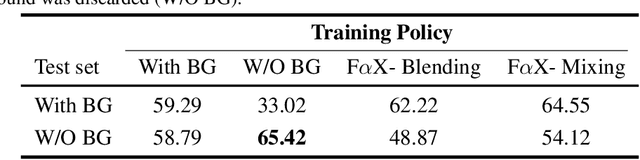
We present a simple and intuitive Focus-and-eXpand (\fax) method to guide the training process of a neural network towards a specific solution. Optimizing a neural network is a highly non-convex problem. Typically, the space of solutions is large, with numerous possible local minima, where reaching a specific minimum depends on many factors. In many cases, however, a solution which considers specific aspects, or features, of the input is desired. For example, in the presence of bias, a solution that disregards the biased feature is a more robust and accurate one. Drawing inspiration from Parameter Continuation methods, we propose steering the training process to consider specific features in the input more than others, through gradual shifts in the input domain. \fax extracts a subset of features from each input data-point, and exposes the learner to these features first, Focusing the solution on them. Then, by using a blending/mixing parameter $\alpha$ it gradually eXpands the learning process to include all features of the input. This process encourages the consideration of the desired features more than others. Though not restricted to this field, we quantitatively evaluate the effectiveness of our approach on various Computer Vision tasks, and achieve state-of-the-art bias removal, improvements to an established augmentation method, and two examples of improvements to image classification tasks. Through these few examples we demonstrate the impact this approach potentially carries for a wide variety of problems, which stand to gain from understanding the solution landscape.
Image Morphing with Perceptual Constraints and STN Alignment
Apr 29, 2020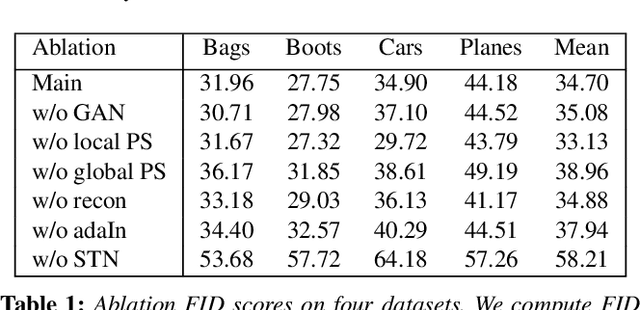
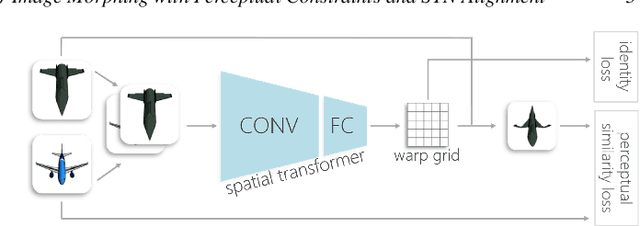
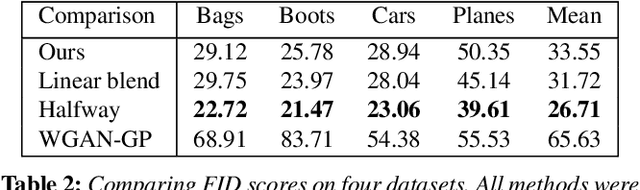

In image morphing, a sequence of plausible frames are synthesized and composited together to form a smooth transformation between given instances. Intermediates must remain faithful to the input, stand on their own as members of the set, and maintain a well-paced visual transition from one to the next. In this paper, we propose a conditional GAN morphing framework operating on a pair of input images. The network is trained to synthesize frames corresponding to temporal samples along the transformation, and learns a proper shape prior that enhances the plausibility of intermediate frames. While individual frame plausibility is boosted by the adversarial setup, a special training protocol producing sequences of frames, combined with a perceptual similarity loss, promote smooth transformation over time. Explicit stating of correspondences is replaced with a grid-based freeform deformation spatial transformer that predicts the geometric warp between the inputs, instituting the smooth geometric effect by bringing the shapes into an initial alignment. We provide comparisons to classic as well as latent space morphing techniques, and demonstrate that, given a set of images for self-supervision, our network learns to generate visually pleasing morphing effects featuring believable in-betweens, with robustness to changes in shape and texture, requiring no correspondence annotation.
ALIGNet: Partial-Shape Agnostic Alignment via Unsupervised Learning
Oct 30, 2018
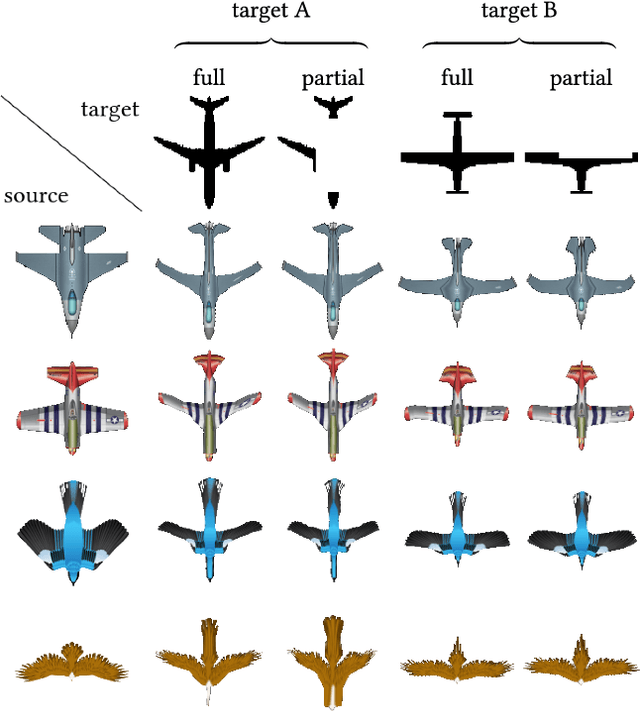

The process of aligning a pair of shapes is a fundamental operation in computer graphics. Traditional approaches rely heavily on matching corresponding points or features to guide the alignment, a paradigm that falters when significant shape portions are missing. These techniques generally do not incorporate prior knowledge about expected shape characteristics, which can help compensate for any misleading cues left by inaccuracies exhibited in the input shapes. We present an approach based on a deep neural network, leveraging shape datasets to learn a shape-aware prior for source-to-target alignment that is robust to shape incompleteness. In the absence of ground truth alignments for supervision, we train a network on the task of shape alignment using incomplete shapes generated from full shapes for self-supervision. Our network, called ALIGNet, is trained to warp complete source shapes to incomplete targets, as if the target shapes were complete, thus essentially rendering the alignment partial-shape agnostic. We aim for the network to develop specialized expertise over the common characteristics of the shapes in each dataset, thereby achieving a higher-level understanding of the expected shape space to which a local approach would be oblivious. We constrain ALIGNet through an anisotropic total variation identity regularization to promote piecewise smooth deformation fields, facilitating both partial-shape agnosticism and post-deformation applications. We demonstrate that ALIGNet learns to align geometrically distinct shapes, and is able to infer plausible mappings even when the target shape is significantly incomplete. We show that our network learns the common expected characteristics of shape collections, without over-fitting or memorization, enabling it to produce plausible deformations on unseen data during test time.
MeshCNN: A Network with an Edge
Sep 16, 2018
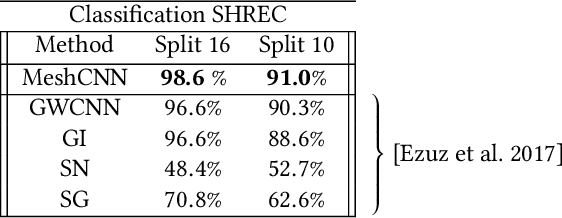
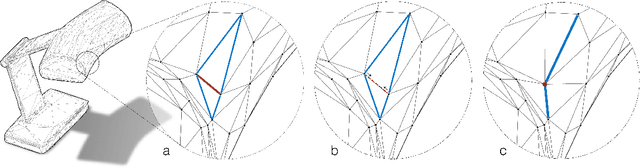
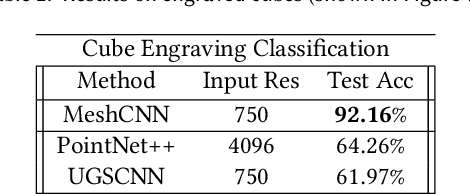
A polygonal mesh representation provides an efficient approximation for 3D shapes. It explicitly captures both shape surface and topology, and leverages non-uniformity to represent large flat regions as well as sharp, intricate features. This non-uniformity and irregularity, however, inhibits mesh analysis efforts using neural networks that combine convolution and pooling operations. In this paper, we utilize the unique properties of the mesh for a direct analysis of 3D shapes using MeshCNN, a convolutional neural network designed specifically for triangular meshes. Analogous to classic CNNs, MeshCNN combines specialized convolution and pooling layers that operate on the mesh edges, by leveraging their intrinsic geodesic connections. Convolutions are applied on edges and the four edges of their incident triangles, and pooling is applied via an edge collapse operation that retains surface topology, thereby, generating new mesh connectivity for the subsequent convolutions. MeshCNN learns which edges to collapse, thus forming a task-driven process where the network exposes and expands the important features while discarding the redundant ones. We demonstrate the effectiveness of our task-driven pooling on various learning tasks applied to 3D meshes.