 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchPatch: Sketch Stylization via Seamless Patch-level Synthesis
Sep 04, 2020
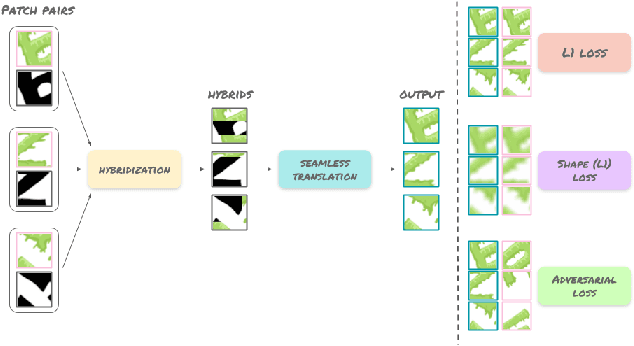
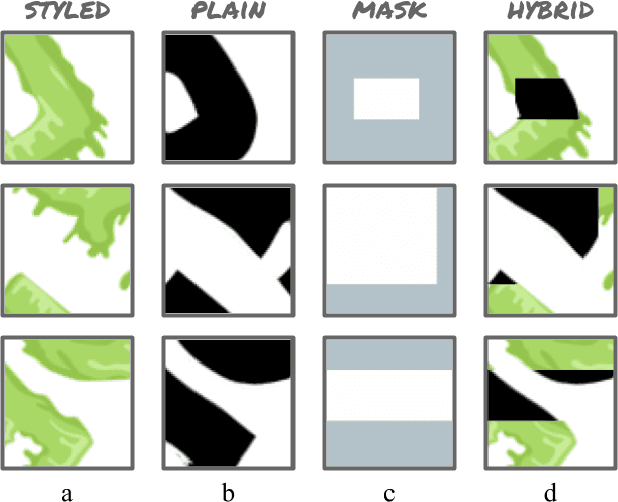
The paradigm of image-to-image translation is leveraged for the benefit of sketch stylization via transfer of geometric textural details. Lacking the necessary volumes of data for standard training of translation systems, we advocate for operation at the patch level, where a handful of stylized sketches provide ample mining potential for patches featuring basic geometric primitives. Operating at the patch level necessitates special consideration of full sketch translation, as individual translation of patches with no regard to neighbors is likely to produce visible seams and artifacts at patch borders. Aligned pairs of styled and plain primitives are combined to form input hybrids containing styled elements around the border and plain elements within, and given as input to a seamless translation (ST) generator, whose output patches are expected to reconstruct the fully styled patch. An adversarial addition promotes generalization and robustness to diverse geometries at inference time, forming a simple and effective system for arbitrary sketch stylization, as demonstrated upon a variety of styles and sketches.
Image Morphing with Perceptual Constraints and STN Alignment
Apr 29, 2020
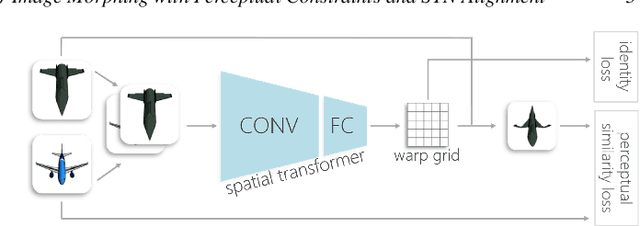
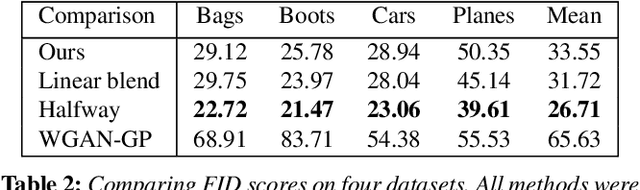

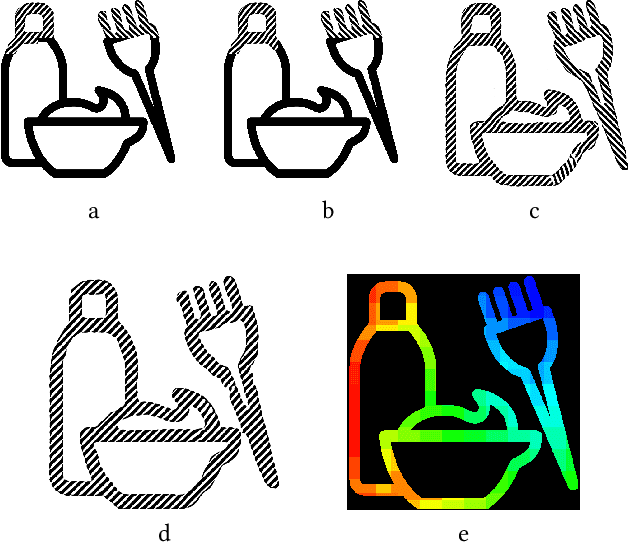
In image morphing, a sequence of plausible frames are synthesized and composited together to form a smooth transformation between given instances. Intermediates must remain faithful to the input, stand on their own as members of the set, and maintain a well-paced visual transition from one to the next. In this paper, we propose a conditional GAN morphing framework operating on a pair of input images. The network is trained to synthesize frames corresponding to temporal samples along the transformation, and learns a proper shape prior that enhances the plausibility of intermediate frames. While individual frame plausibility is boosted by the adversarial setup, a special training protocol producing sequences of frames, combined with a perceptual similarity loss, promote smooth transformation over time. Explicit stating of correspondences is replaced with a grid-based freeform deformation spatial transformer that predicts the geometric warp between the inputs, instituting the smooth geometric effect by bringing the shapes into an initial alignment. We provide comparisons to classic as well as latent space morphing techniques, and demonstrate that, given a set of images for self-supervision, our network learns to generate visually pleasing morphing effects featuring believable in-betweens, with robustness to changes in shape and texture, requiring no correspondence annotation.